Intel to Develop Discrete GPUs, Hires Raja Koduri as Chief Architect & Senior VP
by Ryan Smith on November 8, 2017 5:15 PM EST- Posted in
- GPUs
- Intel
- Raja Koduri

On Monday, Intel announced that it had penned a deal with AMD to have the latter provide a discrete GPU to be integrated onto a future Intel SoC. On Tuesday, AMD announced that their chief GPU architect, Raja Koduri, was leaving the company. Now today the saga continues, as Intel is announcing that they have hired Raja Koduri to serve as their own GPU chief architect. And Raja's task will not be a small one; with his hire, Intel will be developing their own high-end discrete GPUs.
Starting from the top and following yesterday’s formal resignation from AMD, Raja Koduri has jumped ship to Intel, where he will be serving as a Senior VP for the company, overseeing the new Core and Visual Computing group. As a chief architect and general manager, Intel is tasking Raja with significantly expanding their GPU business, particularly as the company re-enters the discrete GPU field. Raja of course has a long history in the GPU space as a leader in GPU architecture, serving as the manager of AMD’s graphics business twice, and in between AMD stints serving as the director of graphics architecture on Apple’s GPU team.

Meanwhile, in perhaps the only news that can outshine the fact that Raja Koduri is joining Intel, is what he will be doing for Intel. As part of today’s revelation, Intel has announced that they are instituting a new top-to-bottom GPU strategy. At the bottom, the company wants to extend their existing iGPU market into new classes of edge devices, and while Intel doesn’t go into much more detail than this, the fact that they use the term “edge” strongly implies that we’re talking about IoT-class devices, where edge goes hand-in-hand with neural network inference. This is a field Intel already plays in to some extent with their Atom processors on the GPU side, and their Movidius neural compute engines on the dedicated silicon sign.
However in what’s likely the most exciting part of this news for PC enthusiasts and the tech industry as a whole, is that in aiming at the top of the market, Intel will once again be going back into developing discrete GPUs. The company has tried this route twice before; once in the early days with the i740 in the late 90s, and again with the aborted Larrabee project in the late 2000s. However even though these efforts never panned out quite like Intel has hoped, the company has continued to develop their GPU architecture and GPU-like devices, the latter embodying the massive parallel compute focused Xeon Phi family.
Yet while Intel has GPU-like products for certain markets, the company doesn’t have a proper GPU solution once you get beyond their existing GT4-class iGPUs, which are, roughly speaking, on par with $150 or so discrete GPUs. Which is to say that Intel doesn’t have access to the midrange market or above with their iGPUs. With the hiring of Raja and Intel’s new direction, the company is going to be expanding into full discrete GPUs for what the company calls “a broad range of computing segments.”
Reading between the lines, it’s clear that Intel will be going after both the compute and graphics sub-markets for GPUs. The former of course is an area where Intel has been fighting NVIDIA for several years now with less success than they’d like to see, while the latter would be new territory for Intel. However it’s very notable that Intel is calling these “graphics solutions”, so it’s clear that this isn’t just another move by Intel to develop a compute-only processor ala the Xeon Phi.

NVIDIA are at best frenemies; the companies’ technologies complement each other well, but at the same time NVIDIA wants Intel’s high-margin server compute business, and Intel wants a piece of the action in the rapid boom in business that NVIDIA is seeing in the high performance computing and deep learning markets. NVIDIA has already begun weaning themselves off of Intel with technologies such as the NVLInk interconnect, which allows faster and cache-coherent memory transfers between NVIDIA GPUs and the forthcoming IBM POWER9 CPU. Meanwhile developing their own high-end GPU would allow Intel to further chase developers currently in NVIDIA’s stable, while in the long run also potentially poaching customers from NVIDIA’s lucrative (and profitable) consumer and professional graphics businesses.
To that end, I’m going to be surprised if Intel doesn’t develop a true top-to-bottom product stack that contains midrange GPUs as well – something in the vein of Polaris 10 and GP106 – but for the moment the discrete GPU aspect of Intel’s announcement is focused on high-end GPUs. And, given what we typically see in PC GPU release cycles, even if Intel does develop a complete product stack, I wouldn’t be too surprised if Intel’s first released GPU was a high-end GPU, as it’s clear this is where Intel needs to start first to best combat NVIDIA.
More broadly speaking, this is an interesting shift in direction for Intel, and one that arguably indicates that Intel’s iGPU-exclusive efforts in the GPU space were not the right move. For the longest time, Intel played very conservatively with its iGPUs, maxing out with the very much low-end GT2 configuration. More recently, starting with the Haswell generation in 2013, Intel introduced more powerful GT3 and GT4 configurations. However this was primarily done at the behest of a single customer – Apple – and even to this day, we see very little OEM adoption of Intel’s higher performance graphics options by the other PC OEMs. The end result has been that Intel has spent the last decade making the kinds of CPUs that their cost-conscious customers want, with just a handful of high-performance versions.

I would happily argue that outside of Apple, most other PC OEMs don’t “get it” with respect to graphics, but at this juncture that’s beside the point. Between Monday’s strongly Apple-flavored Kaby Lake-G SoC announcement and now Intel’s vastly expanded GPU efforts, the company is, if only finally, becoming a major player in the high-performance GPU space.
Besides taking on NVIDIA though, this is going to put perpetual underdog AMD into a tough spot. AMD’s edge over Intel for the longest time has been their GPU technology. The Zen CPU core has thankfully reworked that balance in the last year, though AMD still hasn’t quite caught up to Intel here on peak performance. The concern here is that the mature PC market has strongly favored duopolies – AMD and Intel for CPUs, AMD and NVIDIA for GPUs – so Intel’s entrance into the discrete GPU space upsets the balance on the latter. And while AMD is without a doubt more experienced than Intel, Intel has the financial and fabrication resources to fight NVIDIA, something AMD has always lacked. Which isn’t to say that AMD is by any means doom, but Intel’s growing GPU efforts and Raja’s move to Intel has definitely made AMD’s job harder.
Meanwhile, on the technical side of matters, the big question going forward with Intel’s efforts is over which GPU architecture Intel will use to build their discrete GPUs. Despite their low performance targets, Intel’s Gen9.5 graphics is a very capable architecture in terms of features and capabilities. In fact, prior to the launch of AMD’s Vega architecture a couple months back, it was arguably the most advanced PC GPU architecture, supporting higher tier graphics features than even NVIDIA’s Pascal architecture. So in terms of features alone, Gen9.5 is already a very decent base to start from.
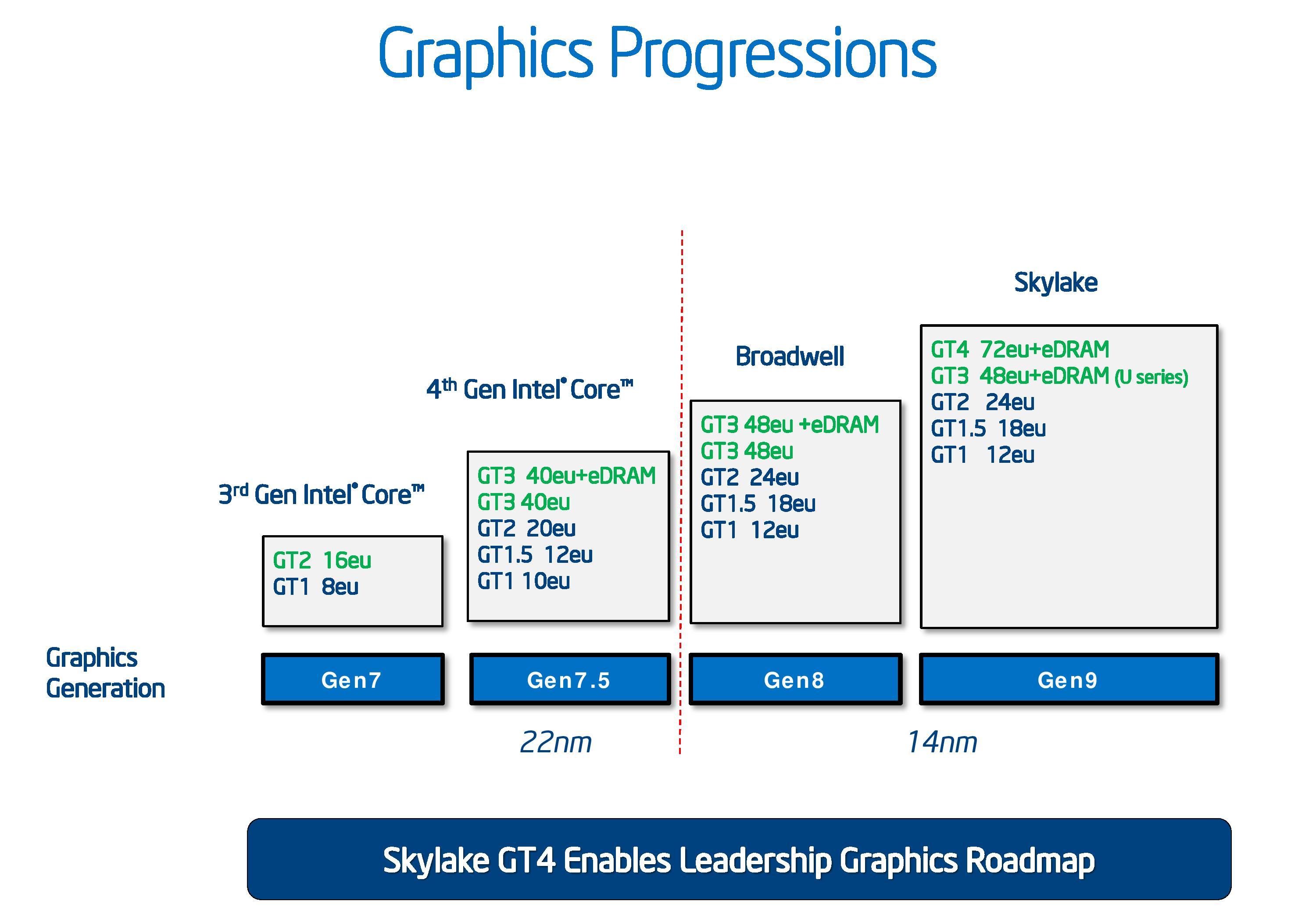
The catch is whether Gen9.5 and its successors can efficiently scale out to the levels needed for a high-performance GPU. Architectural scalability is in some respects the unsung hero of GPU architecture design, as while it’s kind of easy to design a small GPU architecture, it’s a lot harder to design an architecture that can scale up to multiple units in a 400mm2+ die size. Which isn’t to say that Gen9.5 can’t, only that we as the public have never seen anything bigger than the GT4 configuration, which is still a relatively small design by GPU standards.
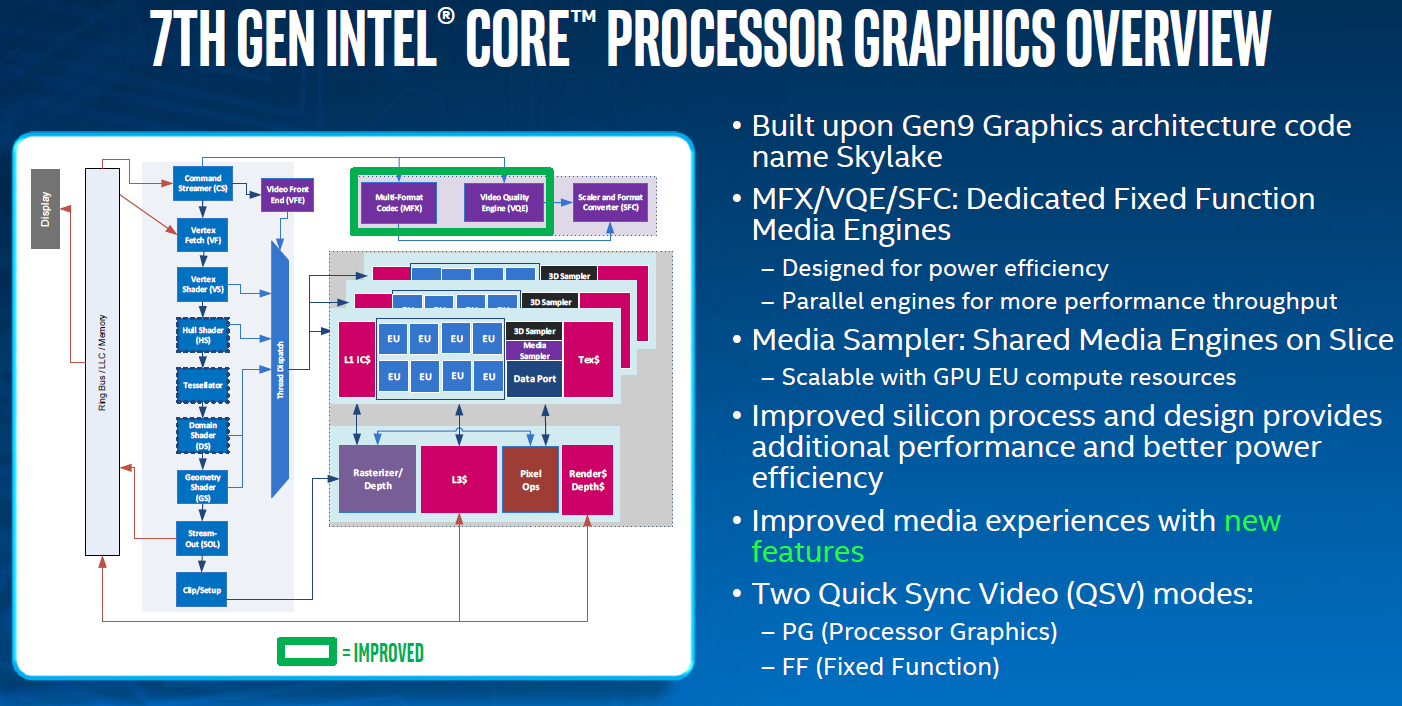
Though perhaps the biggest wildcard here is Intel’s timetable. Nothing about Intel’s announcement says when the company wants to launch these high-end GPUs. If, for example, Intel wants to design a GPU from scratch under Raja, then this would be a 4+ year effort and we’d easily be talking about the first such GPU in 2022. On the other hand, if this has been an ongoing internal project that started well before Raja came on board, then Intel could be a lot closer. Given what kind of progress NVIDIA has made in just the last couple of years, I can only imagine that Intel wants to move quickly, and what this may boil down to is a tiered strategy where Intel takes both routes, if only to release a big Gen9.5(ish) GPU soon to buy time for a new architecture later.
In directing these tasks, Raja Koduri has in turn taken on a very big role at Intel. Until recently, Intel’s graphics lead was Tom Piazza, a Sr. Fellow and capable architect, but also an individual who was never all that public outside of Intel. By contrast, Raja will be a much more public individual thanks to the combination of Intel’s expanded GPU efforts, Raja’s SVP role, and the new Core and Visual Computing group that has been created just for him.
For what Intel is seeking to do, it’s clear why they picked Raja, given his experience inside and outside of AMD, and more specifically, with integrated graphics at both AMD and Apple. The flip side to that however is that while Apple’s graphics portfolio boomed under Raja during his time at the company, his most recent AMD stint didn’t go quite as well. AMD’s Vega GPU architecture has yet to live up to all of its promises, and while success and failure at this level is never the responsibility of a single individual, Intel will certainly be looking to have a better launch than Vega. Which, given the company’s immense resources, is definitely something they can do.
But at the end of the day, this is just the first step for Intel and for Raja. By hiring an experienced hand like Raja Koduri and by announcing that they are getting into high-end discrete GPUs, Intel is very clearly telegraphing their intent to become a major player in the GPU space. Given Intel’s position as a market leader it’s a logical move, and given their lack of recent discrete GPU experience it’s also an ambitious move. So while this move stands to turn the PC GPU market as we know it on its head, I’m looking forward to seeing just what a GPU-focused Intel can do over the coming years.
Source: Intel








200 Comments
View All Comments
SaturnusDK - Thursday, November 9, 2017 - link
So the question is if we'll see more sacred cows slaughtered in the coming months and have nVidia announce a collaboration with AMD to deliver custom Ryzen-based CPUs to pair with their discrete graphic on a single package to fight Intel?Dragonstongue - Thursday, November 9, 2017 - link
GCN Uarch is NOT at fault, they cannot seem to "trim them back" on the lowest end to keep power in check, and do not have the financial grunt to ensure devs are able to code for is properly, but that being said, all the advanced "grunt" for workstation and the like pays in spades where that extra "stuff" can and is more effectively leveraged, Nv is a lean mean fighting "basic needs" machine for the lower end where they are not able/capable to do the most advanced things in DX10-11-12 like Radeons can, cause they "trimmed the fat" which is fine for purpose built "race car" but, not everything wants a specific purpose built "race car" design, Pascal (except for highest end) is far more a tweaked/custom "tuner" where GCN has always been a full out top tier all bells and whistles F1/Le mans type racer.the Uarch of GCN has always been VERY solid, except for some memory feeding issues in some ways, but, really depends on the section of the market the intended card is competing, for example, my good old 7870 is holding up VERY well and still to this day has not been more or less completely "replaced" for similar grunt at similar power levels specific size bus, shaders, transistor density etc....something GCN for sure is GREAT, the specific transistor density, likely is not easy to figure out how to turn things off and on at will to keep performance/power/temperature in check, cause as an "area density" GCN/Polaris/Vega is still technically more "efficient" then Pascal, if you take all them fancy settings Radeons have and plant them on Pascal, or conversely take all the fancy power saving whatever "lean mean" from Pascal and transplant to GCN/Polaris/Vega likely power would go up noticeably for Nv and massively down for Radeons.
That is all am saying, it takes much power to have all them fancy bells and whistles, that is why mostly Fermi, Kepler, Maxwell were using LOTS of power but more "fleshed out" than Pascal technically is, trim a chunk of all that away use fancy clock gating etc ramp clocks up, so essentially (bad analogy) took a run of the mill full weight Porshe and strip out all the seats, use extensive carbon fibre, ramp up the turbos etc etc, full out custom "tuner" the Radeons since back to the 2000 series (3870-4870-5870-6870-7870-280-380-460-580)pretty much for the most part did not truly "trim the fat" was +/- more or less same raw "given performance" same raw given "power required" etc etc, whereas the similar competing Nv designs went from being "hugely powerful requiring lots of power" to "less power but technically less powerful but higher clocked"
Many different ways to look at it I suppose, hard to directly compare what used to be a "behemoth" that was "put on a diet" but learned to run very fast vs a behemoth that is ok being a behemoth and sometimes has issues curbing its appetite.
I think (IMO) is AMD/Radeon could figure out how to turn all that extra grunt off and on at will while retaining the "full fat" design, will end up being killer grunt, whereas for Nv to put that grunt back after they did everything to "strip the fat" it probably wouldn't work as well for Nv as it would for AMD to "optimize" power down vs the other "power up".
Interesting, very very interesting.
FreckledTrout - Thursday, November 9, 2017 - link
Honestly AMD's biggest issue is there process. Its nailing them on both Zen and Vega right now. That 14nm process just scales up in frequency like crap. I mean look at underclocked Vega 56 or lower clocks of Ryzen, very efficient. More than anything getting on that new 7nm process is there biggest thing they need to do right now.Yojimbo - Friday, November 10, 2017 - link
Eh, NVIDIA uses Samsung's 14 nm process for the 1050 and 1050 Ti. It looks a slightly less optimal than TSMC's 16 FF+, but it's not that big of a difference. The GlobalFoundries 14 nm process is supposed to be very close to Samsung's, it just took GlobalFoundries longer to get it up and running.peevee - Thursday, November 9, 2017 - link
"Intel has the financial and fabrication resources to fight NVIDIA, something AMD has always lacked"Not always. There was a time what is now GlobalFoundries has been a part of AMD, while NVidia never had their own production.
peevee - Thursday, November 9, 2017 - link
What would be helpful in the article is performance comparison graph (in FLOPS) between Intel solutions and the ranges from AMD and NVidia, not just abstract EUs compared only to each other.Stuka87 - Thursday, November 9, 2017 - link
Soon as I saw Raja was leaving AMD I said to those around me "He is going to Intel". And sure enough, here he is.peevee - Thursday, November 9, 2017 - link
At this point x86 is so inappropriate for the modern chip technology and computing requirements, it holds the whole industry down. ARMv8 is not much better.PeachNCream - Thursday, November 9, 2017 - link
That's like pretty much every modern CPU though. o.O What other option is there right now that could replace one or both of them?peevee - Thursday, November 9, 2017 - link
There is no option. Only somebody with resources of Intel or AMD or Qualcomm can fully develop one.But ideologically, it should be realized that the current limits are power efficiency and physical length of interconnections transmitting most signals (which is again a primary determinant of power), and the only performance which matters anymore is for processing of large datasets, in massively parallel manner. And nobody cares about programming in codes or assembly anymore, only stack-based high-level programming languages. It is not 1945 anymore, Von Neumann should be abandoned and the whole architecture rethought from scratch.
And that logically leads to:
1) as little of unnecessary processing as possible (so less caching and other data copying including to-from registers, no speculative execution etc)
2) Processing should happen as close to memory holding the data to be processed as possible, preferably within 1mm.
3) temporary unused transistors are OK as long as they do not make signal paths longer and can be used when the data in the memory nearby needs to be processed in massively parallel manner.
It could be solved by an architecture which does not have any general-purpose registers and as few specialized as possible (IP and SP) to be able to redistribute state to many cores as cheaply (in terms of power) as possible. Directly-cached (non associatively) top of the stack is the register file, full-stop.
Bit-based addressing and processing (because you don't need to unpack and process 16 bits when you need 10 bits for video etc).
Hardware map-reduce to distribute the work close to the memory where data is, not a piecemeal and fixed-width vector operations.
Compressed (not reduced) instruction set.
Native, transparent virtualization.