The Intel Core i9-7980XE and Core i9-7960X CPU Review Part 1: Workstation
by Ian Cutress on September 25, 2017 3:01 AM ESTBenchmarking Performance: CPU System Tests
Our first set of tests is our general system tests. These set of tests are meant to emulate more about what people usually do on a system, like opening large files or processing small stacks of data. This is a bit different to our office testing, which uses more industry standard benchmarks, and a few of the benchmarks here are relatively new and different.
All of our benchmark results can also be found in our benchmark engine, Bench.
PDF Opening
First up is a self-penned test using a monstrous PDF we once received in advance of attending an event. While the PDF was only a single page, it had so many high-quality layers embedded it was taking north of 15 seconds to open and to gain control on the mid-range notebook I was using at the time. This put it as a great candidate for our 'let's open an obnoxious PDF' test. Here we use Adobe Reader DC, and disable all the update functionality within. The benchmark sets the screen to 1080p, opens the PDF to in fit-to-screen mode, and measures the time from sending the command to open the PDF until it is fully displayed and the user can take control of the software again. The test is repeated ten times, and the average time taken. Results are in milliseconds.

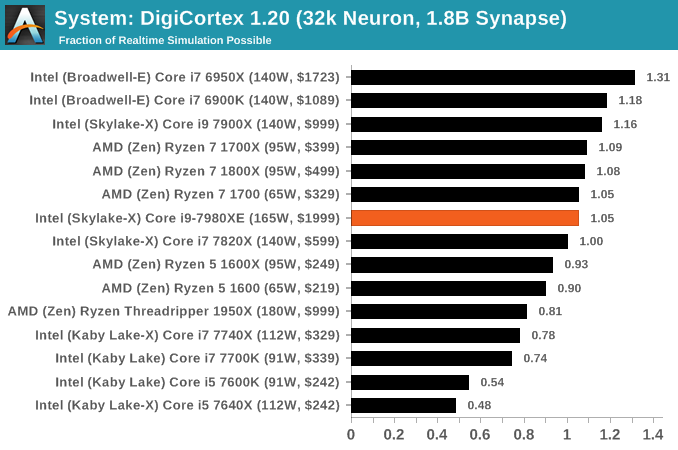
FCAT Processing: link
One of the more interesting workloads that has crossed our desks in recent quarters is FCAT - the tool we use to measure stuttering in gaming due to dropped or runt frames. The FCAT process requires enabling a color-based overlay onto a game, recording the gameplay, and then parsing the video file through the analysis software. The software is mostly single-threaded, however because the video is basically in a raw format, the file size is large and requires moving a lot of data around. For our test, we take a 90-second clip of the Rise of the Tomb Raider benchmark running on a GTX 980 Ti at 1440p, which comes in around 21 GB, and measure the time it takes to process through the visual analysis tool.
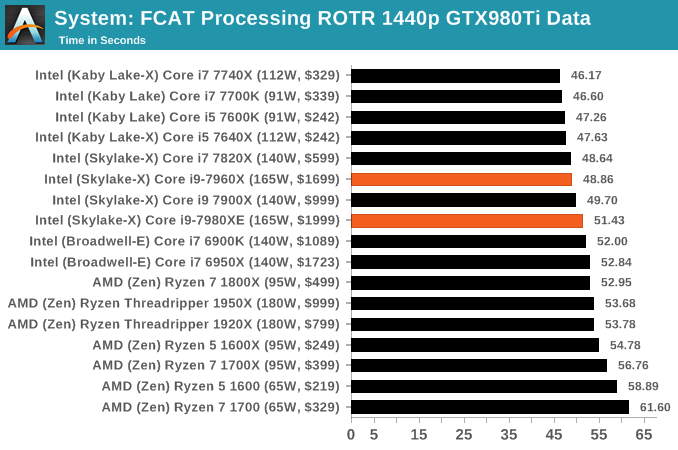
Dolphin Benchmark: link
Many emulators are often bound by single thread CPU performance, and general reports tended to suggest that Haswell provided a significant boost to emulator performance. This benchmark runs a Wii program that ray traces a complex 3D scene inside the Dolphin Wii emulator. Performance on this benchmark is a good proxy of the speed of Dolphin CPU emulation, which is an intensive single core task using most aspects of a CPU. Results are given in minutes, where the Wii itself scores 17.53 minutes.
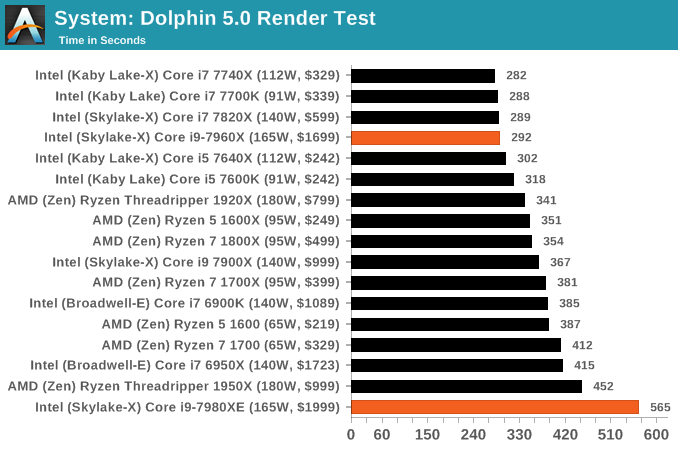
3D Movement Algorithm Test v2.1: link
This is the latest version of the self-penned 3DPM benchmark. The goal of 3DPM is to simulate semi-optimized scientific algorithms taken directly from my doctorate thesis. Version 2.1 improves over 2.0 by passing the main particle structs by reference rather than by value, and decreasing the amount of double->float->double recasts the compiler was adding in. It affords a ~25% speed-up over v2.0, which means new data.
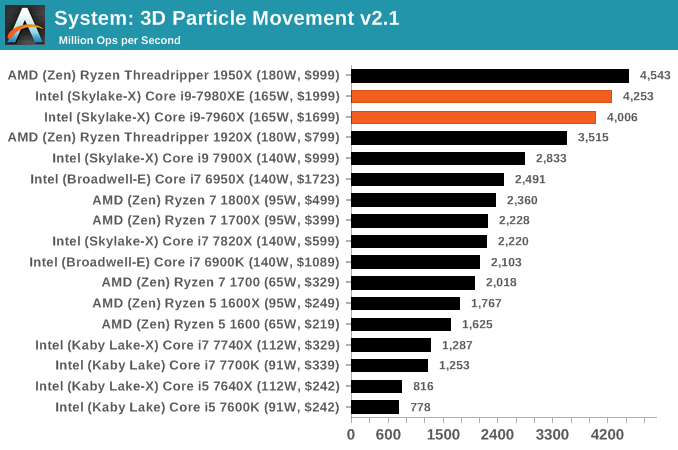
DigiCortex v1.20: link
Despite being a couple of years old, the DigiCortex software is a pet project for the visualization of neuron and synapse activity in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron/1.8B synapse simulation. The results on the output are given as a fraction of whether the system can simulate in real-time, so anything above a value of one is suitable for real-time work. The benchmark offers a 'no firing synapse' mode, which in essence detects DRAM and bus speed, however we take the firing mode which adds CPU work with every firing.
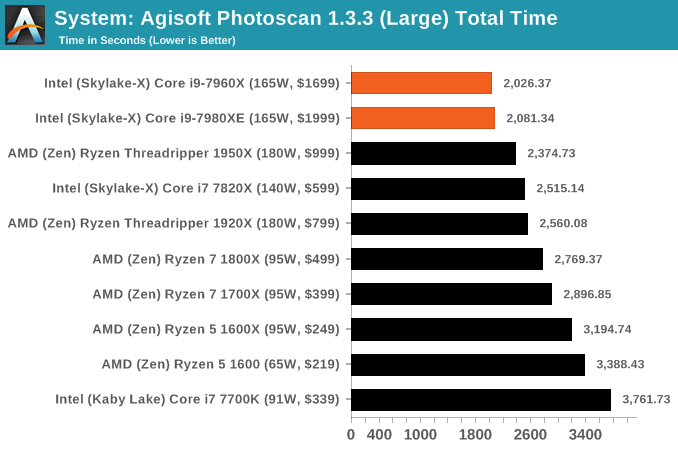
Agisoft Photoscan 1.3.3: link
Photoscan stays in our benchmark suite from the previous version, however now we are running on Windows 10 so features such as Speed Shift on the latest processors come into play. The concept of Photoscan is translating many 2D images into a 3D model - so the more detailed the images, and the more you have, the better the model. The algorithm has four stages, some single threaded and some multi-threaded, along with some cache/memory dependency in there as well. For some of the more variable threaded workload, features such as Speed Shift and XFR will be able to take advantage of CPU stalls or downtime, giving sizeable speedups on newer microarchitectures.








152 Comments
View All Comments
mapesdhs - Monday, September 25, 2017 - link
Just curious mmrezaie, why do you say "unofficially"? ECC support is included on specs pages for X399 boards.frowertr - Tuesday, September 26, 2017 - link
Run Unbound on a Pi or other Linux VM and block all thise adverts at the DNS level for all the devices on your LAN. I havent seen a site add anywhere in years from my home.Notmyusualid - Thursday, September 28, 2017 - link
@frowertrInteresting - But that won't work for me - I'm a frequent traveller, and thus on different LANs all the time.
But what works for me, is PeerBlock, then iblocklist.com for the Ad-server & Malicious lists and others, add Microsoft and any other entity I don't want my packets broadcast to (my Antivirus alerts me when I need updates anyway - and thus I temporarily allow http through the firewall for that type of occasion).
realistz - Monday, September 25, 2017 - link
This is why the "core wars" won't be a good thing for consumers. Focus on better single thread perf instead quantity.sonichedgehog360@yahoo.com - Monday, September 25, 2017 - link
On the contrary, single-threaded performance is largely a dead end until we hit quantum computing due to instability inherent to extremely high clock speeds. The core wars is exactly what we need to incentivize developers to improve multi-core scaling and performance: it represents the future of computing.extide - Monday, September 25, 2017 - link
Some things just can't be split up into multiple threads -- it's not a developer skill level or laziness issue, it's just the way it is. Single threaded speed will always be important.PixyMisa - Monday, September 25, 2017 - link
Maybe, but it's still a dead end. It's not going to improve much, ever.HStewart - Monday, September 25, 2017 - link
As a developer for 30 years this is absolutely correct - especially with the user interface logic which includes graphics. Until technology is a truly able to multi-thread the display logic and display hardware - it very important to have single thread performance. I would think this is critically important for games since they deal a lot with screen. Intel has also done something very wise and I believe they realize this important - by allowing some cores to go faster than others. Multi-core is basically hardware assisted multi-threaded applications which is very dependent on application design - most of time threads are used for background tasks. Another critical error is database logic - unless the database core logic is designed to be multithread, you will need single point of entry and in some cases - they database must be on screen thread. Of course with advancement is possible hardware to handle threading and such, it might be possible to over come these limitations. But in NO WAY this is laziness of developer - keep in mind a lot of software has years of development and to completely rewrite the technology is a major and costly effort.lilmoe - Monday, September 25, 2017 - link
There are lots of instances where I'd need summation and other complex algorithm results from millions of records in certain tables. If I'm going the traditional sql route, it would take ages for the computation to return the desired values. I instead divide the load one multiple threads to get a smaller set in which I would perform some cleanup and final arithmetic. Lots of extra work? Yup. More ram per transaction total? Oh yea. Faster? Yes, dramatically faster.WPF was the first attempt by Microsoft to distribute UI load across multiple cores in addition to the gpu, it was so slow in its early days due to lots out inefficiencies and premature multi-core hardware. It's alot better now, but much more work than WinForms as you'd guess. UWP UI is also completely multithreaded.
Android is inching closer to completely have it's UI multithreaded and separate from the main worker thread. We're getting there.
Both you and sonich are correct, but it's also a fact that developers are taking their sweet time to get familiar with and/or use these technologies. Some don't want to that route simply because of technology bias and lock-in.
HStewart - Monday, September 25, 2017 - link
"Both you and sonich are correct, but it's also a fact that developers are taking their sweet time to get familiar with and/or use these technologies. Some don't want to that route simply because of technology bias and lock-in."That is not exactly what I was saying - it completely understandable to use threads to handle calculation - but I am saying that the designed of hardware with a single screen element makes it hard for true multi-threading. Often the critical sections must be lock - especially in a multi-processor system.
The best use of multi-threading and mult-cpu systems is actually in 3D rendering, this is where multiple threads can be use to distribute the load. In been a while since I work with Lightwave 3D and Vue, but in those days I would create a render farm - one of reason, I purchase a Dual Xeon 5160 ten years ago. But now a days processors like these processors here could do the work or 10 or normal machines on my farm ( Xeon was significantly more power then the P4's - pretty much could do the work of 4 or more P4's back then )