AMD's Future in Servers: New 7000-Series CPUs Launched and EPYC Analysis
by Ian Cutress on June 20, 2017 4:00 PM EST- Posted in
- CPUs
- AMD
- Enterprise CPUs
- EPYC
- Whitehaven
- 1P
- 2P
With recent fears about security, and given that these processors are aiming to go to the Enterprise space, AMD had to dedicate some time to explaining how secure the new platform is. AMD has had its Secure Processor in several CPUs at this point: a 32-bit ARM Cortex-A5 acting as a microcontroller that runs a secure OS/kernel with secure off-chip storage for firmware and data – this helps provide cryptographic functionality for secure key generation and key management. This starts with hardware validated boot (TPM), but includes Secure Memory Encryption and Secure Encrypted Virtualization.
Encryption starts at the DRAM level, with an AES-128 engine directly attached to the MMU. This is designed to protect against physical memory attacks, with each VM and Hypervisor able to generate a separate key for their environment. The OS or Hypervisor can choose which pages to encrypt via page tables, and the DMA engines can provide support for external devices such as network storage and graphics cards to access encrypted pages.
Because each VM or container can obtain its own encryption key, this isolates them from each other, protecting against cross-contamination. It also allows unencrypted VMs to run alongside encrypted ones, removing the all-or-nothing scenario. The keys are transparent to the VMs themselves, managed by the protected hypervisor. It all integrates with existing AMD-V technology.
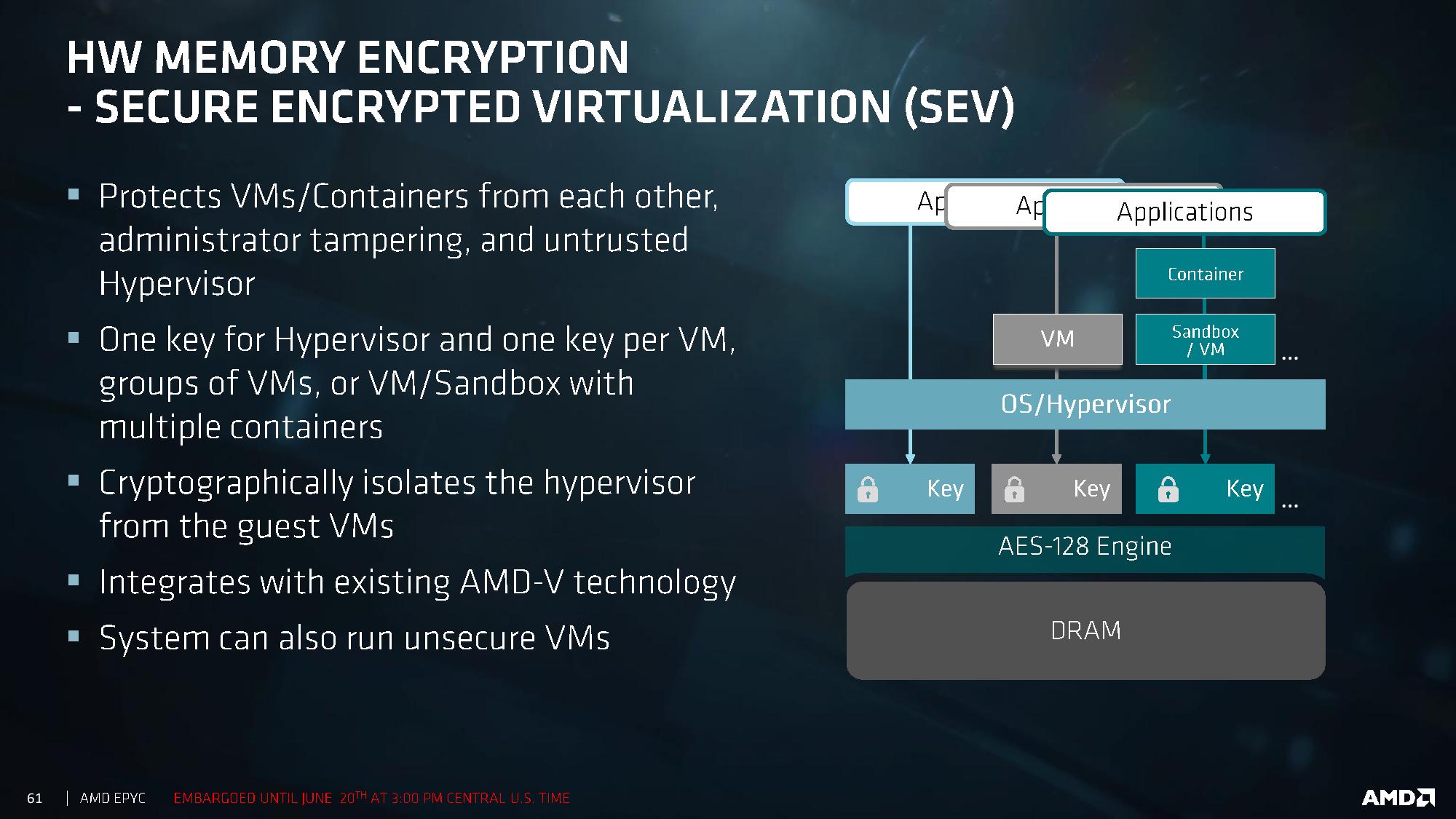
Alongside this are direct RAS features in the core, with the L1 data cache using SEC-DED ECC and L2/L3 caches using DEC-TED ECC. The DRAM support involves x4 DRAM device failure correction with addr/cmd parity and write CRC with replay. Data poisoning is handled with reporting and a machine check recovery mode. The Infinity Fabric between dies and between sockets is also link-packet CRC backed with retry.
One element that was not discussed is live VM migration across encrypted environments. We fully suspect that an AMD-to-AMD live migration be feasible, although an AMD-to-Intel or Intel-to-AMD will have issues, given that each microarchitecture has unique implementations of certain commands.








131 Comments
View All Comments
Gothmoth - Tuesday, June 20, 2017 - link
i read AMD reduced the benchmark numbers for intel by 46% because of compiler benefits for intel...can someone look at the fineprint and confirm or rebunk this???
spikebike - Tuesday, June 20, 2017 - link
Well AMD is comparing a benchmark compiled with gcc-6.2 and running on Intel vs the same benchmark comiled with gcc-6.2 and running on AMD. For people who compile their own binaries with gcc this is quite fair. However intel's compiler is sometimes substantially faster than gcc, question is are the binaries you care about (Games? Handbrake? Something else?) compiled with intel's compiler or gcc?Gothmoth - Tuesday, June 20, 2017 - link
you could be right but it reads on tomshardware as if they just take the numbers provided by intel and reduce them.. they actually don´t test on intel. the just take numbers from intel and reduce them by 46%.hamoboy - Tuesday, June 20, 2017 - link
From what I read they tested the flagship Xeon, found the performance multiplier (~0.57), then extrapolated them across the rest of the range. So not completely scummy, but still cause to wait for actual benchmarks.TC2 - Wednesday, June 21, 2017 - link
according to the numbersE5-2698 v4 / EPYC 7551 ~~ 1.11
all this looks quite misleading! but this is amd :)
TC2 - Wednesday, June 21, 2017 - link
1.11 per core i mean to sayRyan Smith - Tuesday, June 20, 2017 - link
We still need to independently confirm the multiplier, but yes, AMD is reducing Intel's official SPEC scores."Scores for these E5 processors extrapolated from test results published at www.spec.org, applying a conversion multiplier to each published score"
davegraham - Tuesday, June 20, 2017 - link
Jeff @ Techreport has the multiplier officially listed.deltaFx2 - Wednesday, June 21, 2017 - link
Intel "cheats" in the icc compiler when compiling SPEC workloads. Libquantum is most notorious for such cheating but many others are also prone to this issue. In Libq, the icc compiler basically reorganize the datastructures and memory layout to get excellent vectorization, and I think 1/10th the bandwidth requirements as compared to gcc -O2. These transformations are there only for libquantum so it has little to no use for general workloads. Hence gcc (and llvm) reject such transformations. It's not unlike VW's emission defeat devices, actually.Go to Ars Technica. They have the full dump of slides. AMD does benchmark Xeon 1 or 2 systems themselves. However for some of the graphs where Xeon data is presented, they use Intel's published numbers (on icc of course), and derate it by this factor to account for this cheating. You could argue that AMD should have benched all the systems themselves and that's fair enough. But I don't think Tom's hardware is exactly qualified to know or state that the derate is 20% and not 40% or whatever. They benchmark consumer hardware, and wouldn't know a thing about this. So any number coming from these sources are dubious.
patrickjp93 - Wednesday, June 21, 2017 - link
Wrong. See the CPPCon 2015/2016 "Compiler Switches" talks. ICC does not CHEAT at all. It hasn't since 2014.Intel wins purely on merit.