The Intel Skylake-X Review: Core i9 7900X, i7 7820X and i7 7800X Tested
by Ian Cutress on June 19, 2017 9:01 AM ESTBenchmarking Performance: CPU Encoding Tests
One of the interesting elements on modern processors is encoding performance. This includes encryption/decryption, as well as video transcoding from one video format to another. In the encrypt/decrypt scenario, this remains pertinent to on-the-fly encryption of sensitive data - a process by which more modern devices are leaning to for software security. Video transcoding as a tool to adjust the quality, file size and resolution of a video file has boomed in recent years, such as providing the optimum video for devices before consumption, or for game streamers who are wanting to upload the output from their video camera in real-time. As we move into live 3D video, this task will only get more strenuous, and it turns out that the performance of certain algorithms is a function of the input/output of the content.
HandBrake H264 and HEVC
As mentioned above, video transcoding (both encode and decode) is a hot topic in performance metrics as more and more content is being created. First consideration is the standard in which the video is encoded, which can be lossless or lossy, trade performance for file-size, trade quality for file-size, or all of the above can increase encoding rates to help accelerate decoding rates. Alongside Google's favorite codec, VP9, there are two others that are taking hold: H264, the older codec, is practically everywhere and is designed to be optimized for 1080p video, and HEVC (or H265) that is aimed to provide the same quality as H264 but at a lower file-size (or better quality for the same size). HEVC is important as 4K is streamed over the air, meaning less bits need to be transferred for the same quality content.
Handbrake is a favored tool for transcoding, and so our test regime takes care of three areas.
Low Quality/Resolution H264: He we transcode a 640x266 H264 rip of a 2 hour film, and change the encoding from Main profile to High profile, using the very-fast preset.
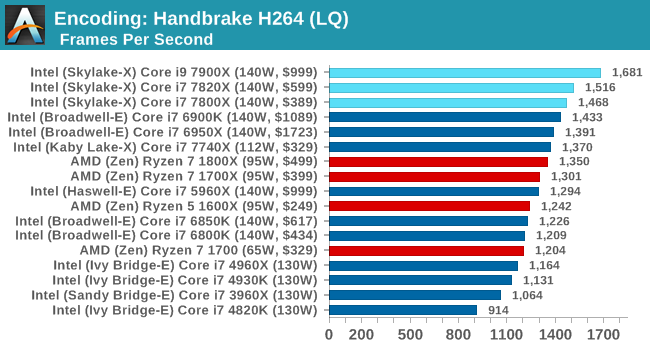
More cores, more frequency, more IPC, more fun: the Core i9-7900X wins here, and even the i7-7800X wins out against the Core i7-6900K.
High Quality/Resolution H264: A similar test, but this time we take a ten-minute double 4K (3840x4320) file running at 60 Hz and transcode from Main to High, using the very-fast preset.
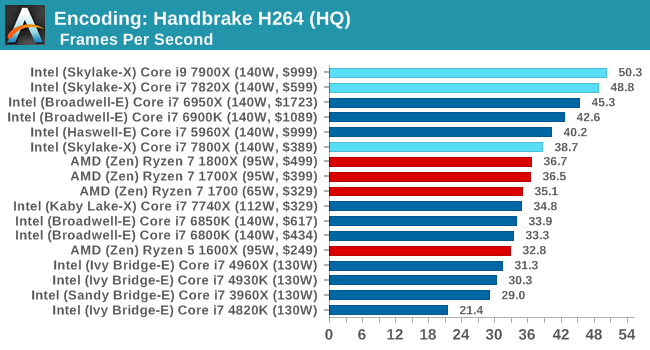
Moving into HQ mode means making the job more parallel, so the higher core counts stay at the top of the chart.
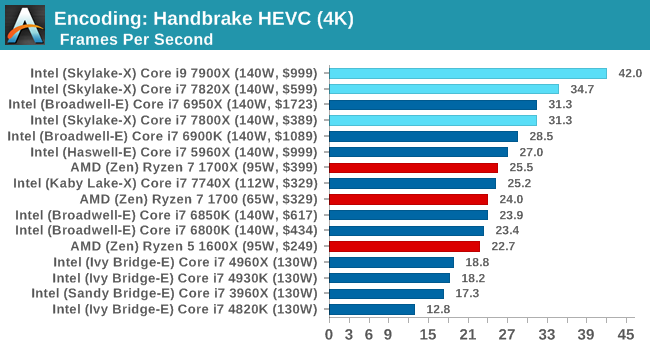
HEVC Test: Using the same video in HQ, we change the resolution and codec of the original video from 4K60 in H264 into 4K60 HEVC.
WinRAR 5.40
For the 2017 test suite, we move to the latest version of WinRAR in our compression test. WinRAR in some quarters is more user friendly that 7-Zip, hence its inclusion. Rather than use a benchmark mode as we did with 7-Zip, here we take a set of files representative of a generic stack (33 video files in 1.37 GB, 2834 smaller website files in 370 folders in 150 MB) of compressible and incompressible formats. The results shown are the time taken to encode the file. Due to DRAM caching, we run the test 10 times and take the average of the last five runs when the benchmark is in a steady state.
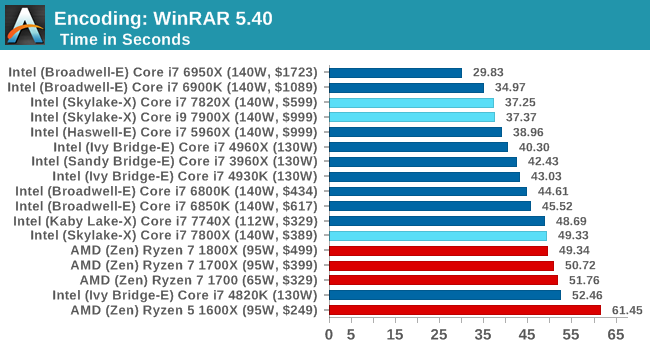
WinRAR loves having access to all the caches as much as possible, to prefetch and store data as needed. The Skylake-X chips fall back a bit here, even with DDR4-2666 support. The Core i7-7800X uses DDR4-2400 memory, so puts it further behind. Interesting didn't realise that the lower core count Broadwell-E chips were affected so much by this test, and the higher core count Ivy Bridge-E parts are faster here.
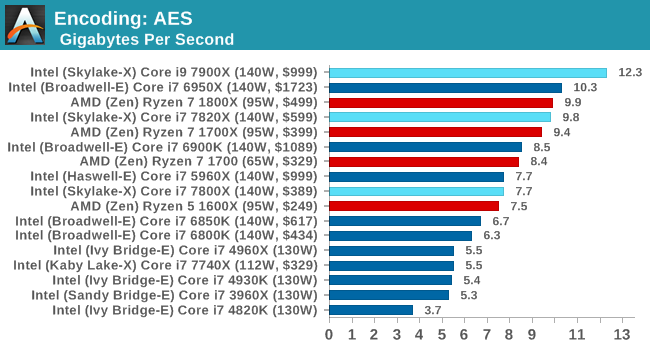
AES Encoding
Algorithms using AES coding have spread far and wide as a ubiquitous tool for encryption. Again, this is another CPU limited test, and modern CPUs have special AES pathways to accelerate their performance. We often see scaling in both frequency and cores with this benchmark. We use the latest version of TrueCrypt and run its benchmark mode over 1GB of in-DRAM data. Results shown are the GB/s average of encryption and decryption.
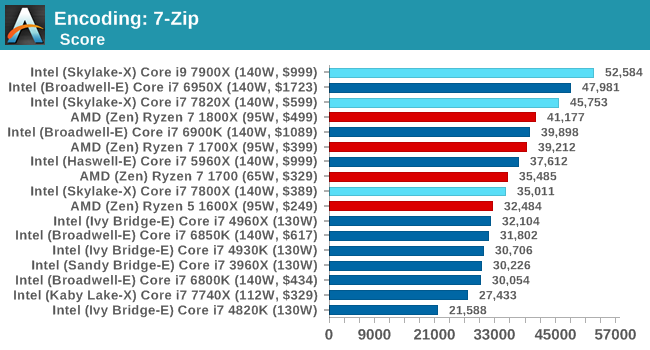
7-Zip
One of the freeware compression tools that offers good scaling performance between processors is 7-Zip. It runs under an open-source licence, is fast, and easy to use tool for power users. We run the benchmark mode via the command line for four loops and take the output score.








264 Comments
View All Comments
mat9v - Tuesday, June 20, 2017 - link
To play it safe, invest in the Core i9-7900X today.To play it safe and get a big GPU, save $400 and invest in the Core i7-7820X today.
Then the conclusion should have been - wait for fixed platform. I'm not even suggesting choosing Ryzen as it performs slower but encouraging buying flawed (for now) platform?
mat9v - Tuesday, June 20, 2017 - link
Please then correct tables on 1st page comparing Ryzen and 7820X and 7800X to state that Intel has 24 lines as they leave 24 for PCIEx slots and 4 is reserved for DMI 3.0If you strip Ryzen lines to only show those available for PCIEx do so for Intel too.
Ryan Smith - Wednesday, June 21, 2017 - link
The tables are correct. The i7 7800 series have 28 PCIe lanes from the CPU for general use, and another 4 DMI lanes for the chipset.PeterCordes - Tuesday, June 20, 2017 - link
Nice article, thanks for the details on the microarchitectural changes, especially to execution units and cache. This explains memory bandwidth vs. working-set size results I observed a couple months ago on Google Compute Engine's Skylake-Xeon VMs with ~55MB of L3: The L2-L3 transition was well beyond 256kB. I had assumed Intel wouldn't use a different L3 cache design for SKX vs. SKL, but large L2 doesn't make much sense with an inclusive L3 of 2 or 2.5MB per core.Anyway, some corrections for page3: The allocation queue (IDQ) is in Skylake-S is always 64 uops, with or without HT. For example, I looked at the `lsd.uops` performance counter in a loop with 97 uops on my i7-6700k. For 97 billion counts of uops_issued.any, I got exactly 0 counts of lsd.uops, with the system otherwise idle. (And I looked at cpu_clk_unhalted.one_thread_active to make sure it was really operating in non-HT mode the majority of the time it was executing.) Also, IIRC, Intel's optimization manual explicitly states that the IDQ is always 64 entries in Skylake.
The scheduler (aka RS or Reservation Station) is 97 unfused-domain uops in Skylake, up from 60 in Haswell. The 180int / 168fp numbers you give are the int / fp register-file sizes. They are sized more like the ROB (224 fused-domain uops, up from 192 in Haswell), not the scheduler, since like the ROB, they have to hold onto values until retirement, not just until execution. See also http://blog.stuffedcow.net/2013/05/measuring-rob-c... for when the PRF size vs. the ROB is the limit on the out-of-order window. See also http://www.realworldtech.com/haswell-cpu/6/ for a nice block diagram of the whole pipeline.
SKL-S DIVPS *latency* is 11 cycles, not 3. The *throughput* is one per 3 cycles for 128-bit vectors, or one per 5 cycles for 256b vectors, according to Agner Fog's table. I forget if I've tested that myself. So are you saying that SKL-SP has one per 5 cycle throughput for 128-bit vectors? What's the throughput for 256b and 512b vectors?
-----
It's really confusing the way you keep saying "AVX unit" or "AVX-512 unit" when I think you mean "512b FMA unit". It sounds like vector-integer, shuffle, and pretty much everything other than FMA will have true 512b execution units. If that's correct, then video codecs like x264/x265 should run the same on LCC vs. HCC silicon (other than differences in mesh interconnect latency), because they're integer-only, not using any vector-FP multiply/add/FMA.
-------
> This should allow programmers to separate control flow from data flow...
SIMD conditional operations without AVX512 are already done branchlessly (I think that's what you mean by separate from control-flow) by masking the input and/or output. e.g. to conditionally add some elements of a vector, AND the input with a vector of all-one or all-zero elements (as produced by CMPPS or PGMPEQD, for example). Adding all-zeros is a no-op (the additive identity).
Mask registers and support for doing it as part of another operation makes it much more efficient, potentially making it a win to vectorize things that otherwise wouldn't be. But it's not a new capability; you can do the same thing with boolean vectors and SSE/AVX VPBLENDVPS.
PeterCordes - Tuesday, June 20, 2017 - link
Speed Shift / Hardware P-State is not Windows-specific, but this article kind of reads as if it is.Your article doesn't mention any other OSes, so nothing it says is actually wrong: I'm sure it did require Intel's collaboration with MS to get support into Win10. The bullet-point in the image that says "Collaboration between Intel and Microsoft specifically for W10 + Skylake" may be going too far, though. That definitely implies that it only works on Win10, which is incorrect.
Linux has supported it for a while. "HWP enabled" in your kernel log means the kernel has handed off P-state selection to the hardware. (Since Linux is open-source, Intel contributed most of the code for this through the regular channels, like they do for lots of other drivers.)
dmesg | grep intel_pstate
[ 1.040265] intel_pstate: Intel P-state driver initializing
[ 1.040924] intel_pstate: HWP enabled
The hardware exposes a knob that controls the tradeoff between power and performance, called Energy Performance Preference or EPP. Len Brown@Intel's Linux patch notes give a pretty good description of it (and how it's different from a similar knob for controlling turbo usage in previous uarches), as well as describing how to use it from Linux. https://patchwork.kernel.org/patch/9723427/.
# CPU features related to HWP, on an i7-6700k running Linux 4.11 on bare metal
fgrep -m1 flags /proc/cpuinfo | grep -o 'hwp[_a-z]*'
hwp
hwp_notify
hwp_act_window
hwp_epp
I find the simplest way to see what speed your cores are running is to just `grep MHz /proc/cpuinfo`. (It does accurately reflect the current situation; Linux finds out what the hardware is actually doing).
IDK about OS X support, but I assume Apple has got it sorted out by now, almost 2 years after SKL launch.
Arbie - Wednesday, June 21, 2017 - link
There are folks for whom every last compute cycle really matters to their job. They have to buy the technical best. If that's Intel, so be it.For those dealing more with 'want' than 'need', a lot of this debate misses an important fact. The only reason Intel is suddenly vomiting cores, defecating feature sizes, and pre-announcing more lakes than Wisonsin is... AMD. Despite its chronic financial weakness that company has, incredibly, come from waaaay behind and given us real competition again. In this ultra-high stakes investment game, can they do that twice? Maybe not. And Intel has shown us what to expect if they have no competitor. In this limited-supplier market it's not just about who has the hottest product - it's also about whom we should reward with our money, and about keeping vital players in the game.
I suggest - if you can, buy AMD. They have earned our support and it's in our best interests to do so. I've always gone with Intel but have lately come to see this bigger picture. It motivated me to buy an 1800X and I will also buy Vega.
Rabnor - Wednesday, June 21, 2017 - link
To play it safe and get a big GPU, save $400 and invest in the Core i7-7820X today.You have to spend that $400+ on a good motherboard & aio cooler.
Are you sold by Intel, anandtech?
Synviks - Thursday, June 22, 2017 - link
For some extra comparison: running Cinebench R15 on my 14c 2.7ghz Haswell Xeon, with turbo to 3ghz on all cores, my score is 2010.Pretty impressive performance gain if they can shave off 4 cores and end up with higher performance.
Pri - Thursday, June 22, 2017 - link
On the first page you wrote this:Similarly, the 6-core Core i7-7820X at $599 goes up against the 8-core $499 Ryzen 7 1800X.
The Core i7 7820X was mistakenly written as a 6-core processor when it is in-fact an 8-core processor.
Kind Regards.
Gigabytes - Thursday, June 22, 2017 - link
Okay, here is what I learned from this article. Gaming performance sucks and you will be able to cook a pizza inside your case. Did I miss anything?Oh, one thing missing.
Play it SMART and wait to see the Ripper in action before buy your new Intel toaster oven.