The Intel Skylake-X Review: Core i9 7900X, i7 7820X and i7 7800X Tested
by Ian Cutress on June 19, 2017 9:01 AM ESTDie Size Estimates and Arrangements
On the previous page, we showed pictures of ring bus and mesh arrangements. With a ring bus, ultimately the silicon layout of the cores and the interconnects can be regular but are not that stringent. Put the cores in a circle (or overlapping circles) and away you go. With a mesh, things get a little more rigid.
The mesh diagrams on the previous page are all presented as rectangles in x*y arrangements. You either have to add a full row or a full column to increase the die count, whereas in a ring it could be straight forward just to add another pair of cores into the ring (which is what happened over the last few generations). Adding a pair of cores in a mesh means that you end up with more corners and more edges – not all cores end up ‘equal’ and there can be performance penalties therein. Ideally, an arrangement where x = y is usually the best bet. This lets us make some predictions about how Intel’s silicon is lining up.
A side-note for discussion. If we had a 100x100 core arrangement, the cores in the middle would have big latency to get anywhere near external memory. Also, a 2D mesh could become a 3D mesh.
Three things come to our aid in discussing the LCC and HCC silicon. First was the original Skylake-X announcement back at Computex: one of Intel’s slides had an image of the basic floorplan of the HCC silicon to be used for the high core-count Skylake-X processors:
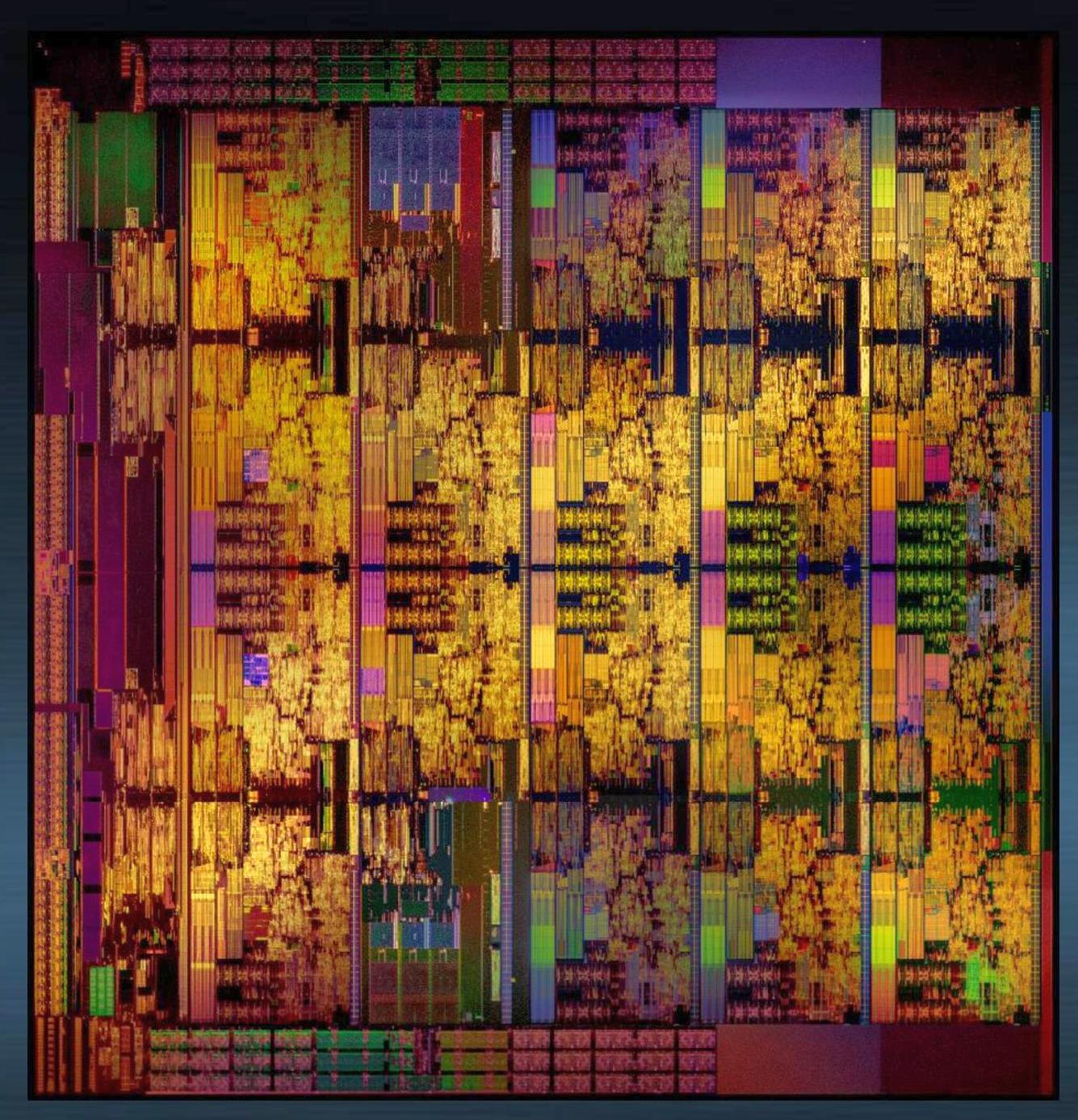
At the time, we were a bit stumped by this image. By counting the regular structures, we can see 4x5 arrangement, or rather a 20-core chip. On closer inspection two of the cores were different: on the second column, the top and bottom ‘cores’ did not look like cores. At the time we postulated that given the size of AVX512, this might be where they were. But the second piece of information was given through Intel’s mesh announcement.
Here’s the diagram:
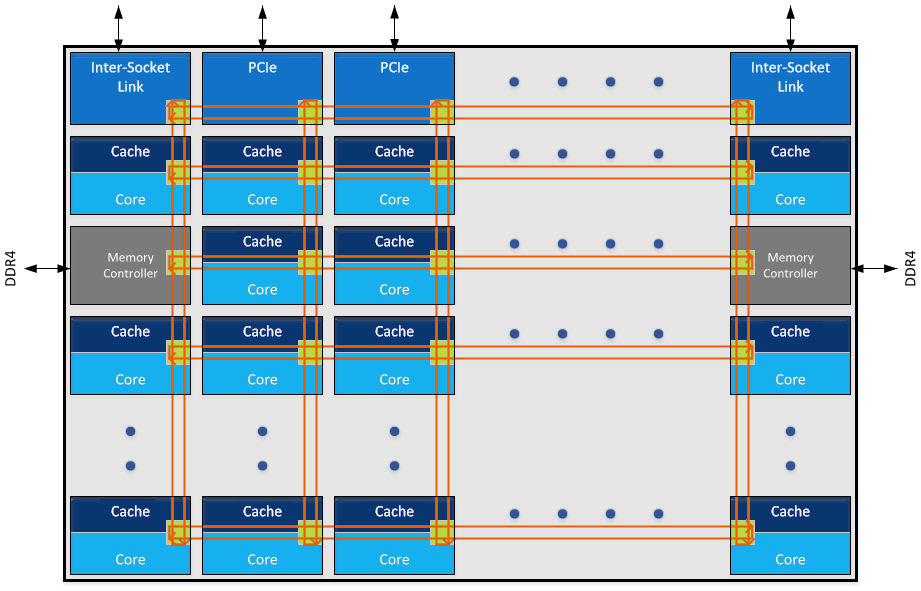
This is meant to be a pseudo mockup of a theoretical core of n processors using the mesh topology. At the top are the socket links, along with the PCIe root complexes. However on the left and right are the DRAM controllers, essentially taking up the same area as a core but also using one of the mesh networking links.
So scoot back to that HCC die image, and zoom in on one of those odd looking ‘cores’:
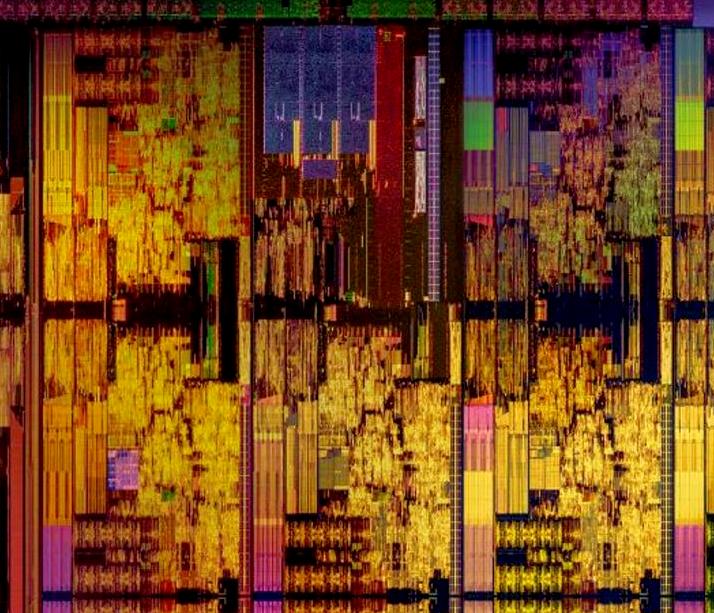
What we can see is three regular blue/green vertical areas, which means three on each side, for a total of six. Skylake-X only has four memory channels, but leaks have shown that the new Skylake-SP processors have six memory channels by design, so here they are. In the 4x5 grid, we have 18 cores and two sets of memory channels.
Back when Skylake-X was announced at Computex, I wrote that we were expecting the LCC silicon to be a 12-core design. At this time, we were still expecting Intel to use a ring-bus topology, and I mentioned before, adding two cores to a ring bus is fairly easy at the expense of peak latency between cores. Now that we know that Intel is using a mesh, it is quite different.
12 cores could quite easily fit into LCC silicon in a 3x4 arrangement, but that does not leave any room for the six memory controllers that the enterprise Xeons are all meant to have. If we added two ‘extra’ core sized areas for the 12-core design, we need a total of 14 segments. Using the x*y arrangement as required above, the only way 14 cores works is using a 7*2 arrangement. If this was the case, the DRAM controllers would essentially fill a whole row, or be at opposite ends of the column. If one of the x*y numbers is the number two, it makes more sense to use a ring bus any day of the week for power, die area and simplicity.
So that means that the 12-core SKU, the Core i9-7920X, is likely derived from the HCC 18-core silicon. Which also explains why that CPU has been delayed until August.
Die Sizes
At this point in time, the Skylake-X processors based on the LCC silicon have been in the hands of a few people. At Computex there were several extreme overclocking (using sub-zero coolants) events dedicated to the new processors. One element of recent extreme overclocking is delidding the processor and removing the integrated heat spreader to replace the thermal interface material underneath.
In general removing the IHS is not recommended without practice and experience, but for some processors in the past we have seen sizeable temperature benefits by replacing the standard thermal interface material (TIM) that Intel uses. The discussion on whether Intel should be offering a standard goopy TIM or the indium-tin solder that they used to (and AMD uses) is one I’ve run on AnandTech before, but there’s a really good guide from Roman Hartung, who overclocks by the name der8auer. I’m trying to get him to agree to post it on AnandTech with SKL-X updates so we can discuss it here, but it really is some nice research. You can find the guide over at http://overclocking.guide.
However removing the IHS means we can measure the silicon die.
The 10-core LCC die, which is a 3x4 design, measures in at 14.3 x 22.4, or 322mm2.
Using this, working from Intel’s 4x5 HCC diagram (and assuming it hasn’t been stretched), we can get 21.6 x 22.4 = 484mm2 for the high-core count design.
That leaves the Extreme core count option. Using the x*y strategy again, Intel could either run a 5x5 design, which gives 25 areas and 23 cores – which is unlikely. Next up is a 5x6 design, which gives 30 areas and 28 cores. It’s no secret that many leaks are pointing to a 28-core XCC processor at this point.
There’s also the fact that Intel provided this die shot at the Intel Manufacturing Day a few weeks ago, clearly showing the 5x6 arrangement:

Doing the basic math on a 5x6 design gives us a 21.6 x 32.3 = 698mm2 die size for XCC.
| Skylake-SP Die Sizes | |||
| Arrangement | Dimensions (mm) |
Die Area (mm2) |
|
| LCC | 3x4 (10-core) | 14.3 x 22.4 | 322 mm2 |
| HCC | 4x5 (18-core) | 21.6 x 22.4 | 484 mm2 |
| XCC | 5x6 (28-core) | 21.6 x 32.3 | 698 mm2 |
Compared to other chips with Intel’s mesh architecture, Knights Landing comes in at 646mm2 (minus MCDRAM), and sources put Knights Corner at 720mm2.








264 Comments
View All Comments
Tephereth - Tuesday, June 20, 2017 - link
"For each of the GPUs in our testing, these games (at each resolution/setting combination) are run four times each, with outliers discarded. Average frame rates, 99th percentiles and 'Time Under x FPS' data is sorted, and the raw data is archived."So... where the hell are the games benchmarks in this review?
beck2050 - Tuesday, June 20, 2017 - link
The possibility of the 18 core beast in the upcoming Mac Pro is really exciting for music pros.That is a tremendous and long overdue leap for power users.
drajitshnew - Tuesday, June 20, 2017 - link
"... and only three PCIe 3.0 x4 drives can use the in-built PCIe RAID"I would like to know which raid level you would use. I can't see 3 m2 drives in raid 1, and raid 5 would require access to the cpu for parity calculations. Then raid 0 it is. Now, which drives will you use for raid 0, which do not saturate the DMI link for sequential reads? And if your workload does not have predominantly sequential reads, then why are you putting the drives in raid.
PeterCordes - Tuesday, June 20, 2017 - link
Standard motherboard RAID controllers are software raid anyway, where the OS drivers queue up writes to each drive separately, instead of sending the data once over the PCIe bus to a hardware RAID controller which queues writes to two drives.What makes it a "raid controller" is that you can boot from it, thanks to BIOS support. Otherwise it's not much different from Linux or Windows pure-software RAID.
If the drivers choose to implement RAID5, that can give you redundancy on 3 drives with the capacity of 2.
However, RAID5 on 3 disks is not the most efficient way. A RAID implementation can get the same redundancy by just storing two copies of every block, instead of generating parity. That avoids a ton of RAID5 performance problems, and saves CPU time. Linux md software RAID implements this as RAID10. e.g. RAID10f2 stores 2 copies of every block, striped across as many disks as you have. It works very well with 3 disks. See for example https://serverfault.com/questions/139022/explain-m...
IDK if Intel's mobo RAID controllers support anything like that or not. I don't use the BIOS to configure my RAID; I just put a boot partition on each disk separately and manage everything from within Linux. IDK if other OSes have soft-raid that supports anything similar either.
> And if your workload does not have predominantly sequential reads, then why are you putting the drives in raid.
That's a silly question. RAID0, RAID1, and RAID5 over 3 disks should all have 3x the random read throughput of a single disk, at least for high queue depths, since each disk will only see about 1/3rd of the reads. RAID0 similarly has 3x random write throughput.
RAID10n2 of 3 disks can have better random write throughput than a single disk, but RAID5 is much worse. RAID1 of course mirrors all the writes to all the disks, so it's a wash for writes. (But can still gain for mixed read and write workloads, since the reads can be distributed among the disks).
Lieutenant Tofu - Tuesday, June 20, 2017 - link
I wonder why 1600X outperforms 1800X here on WebXPRT. It's not a huge difference, but I don't see why it's happening. 6-core vs. 8-core, 3.6 GHz base, 4.0 GHz turbo. This presumably runs in just one thread, so performance should be nearly identical. The only reason I can think of is less contention across the IF on the 1600X due to less enabled cores, but don't see that having a major effect on a single-threaded test like this one.Maybe 1600X can XFR to a little higher than the 1800X.
Eyered - Tuesday, June 20, 2017 - link
Did they have any issues with heat at all?mat9v - Tuesday, June 20, 2017 - link
If that were so everyone would be using HEDT instead of 4c/8t CPUsmat9v - Tuesday, June 20, 2017 - link
Then why again why aren't every workstation consist of dual cpu xeons? If the expense is so insignificant compared to how much faster machine will earn...mat9v - Tuesday, June 20, 2017 - link
I'm just wondering how did 7900X menage to stay within 140W bracket during Prome95 tests when in other reviews it easily reached 250W or more. Is it some internal throttling mechanism that keeps CPU constantly dynamically underclocked to stay within power envelope? How does such compare to forced 4Ghz CPU clock?mat9v - Tuesday, June 20, 2017 - link
And yet in conclusion you say to play it safe and get 7900X ?How does that work together?