The Intel Skylake-X Review: Core i9 7900X, i7 7820X and i7 7800X Tested
by Ian Cutress on June 19, 2017 9:01 AM ESTComparing Skylake-S and Skylake-X/SP Performance Clock-for-Clock
If you’ve read through the full review up to this point (and kudos), there should be three things that stick in the back of your mind about the new Skylake-SP cores: Cache, Mesh and AVX512. These are the three main features that separate the consumer grade Skylake-S core from this new core, and all three can have an impact in clock-for-clock performance. Even though the Skylake-S and the Skylake-SP are not competing in the same markets, it is still poignant to gather how much the changes affect the regular benchmark suite.
For this test, we took the Skylake-S based Core i5-6600 and the Skylake-SP based Core i9-7900X and ran them both with only 4 cores, no hyperthreading, and 3 GHz on all cores with no Turbo active. Both CPUs were run in high performance modes in the OS to restrict any time-to-idle, so it is worth noting here that we are not measuring power. This is just raw throughput.
Both of these cores support different DRAM frequencies, however: the i5-6600 lists DDR4-2133 as its maximum supported frequency, whereas the i9-7900X will run at DDR4-2400 at 2DPC. I queried a few colleagues as to what I should do here – technically the memory support is an extended element of the microarchitecture, and the caches/uncore/untile will be running at different frequencies, so how much of the system support should be chipped away for parity. The general consensus was to test with the supported frequencies, given this is how the parts ship.
For this analysis, each test was broken down in two ways: what sort of benchmark (single thread, multi-thread, mixed) and what category of benchmark (web, office, encode).
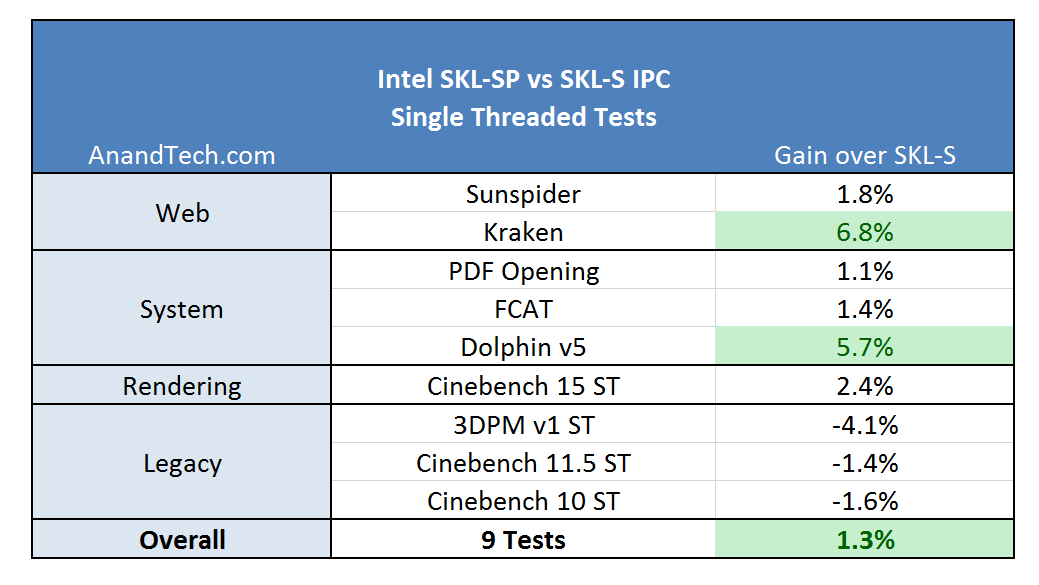
For the single threaded tests, results were generally positive. Kraken enjoyed the L2, and Dolphin emulation had a good gain as well. The legacy tests did not fair that great: 3DPM v1 has false sharing, which is likely taking a hit due to the increased L2 latency.
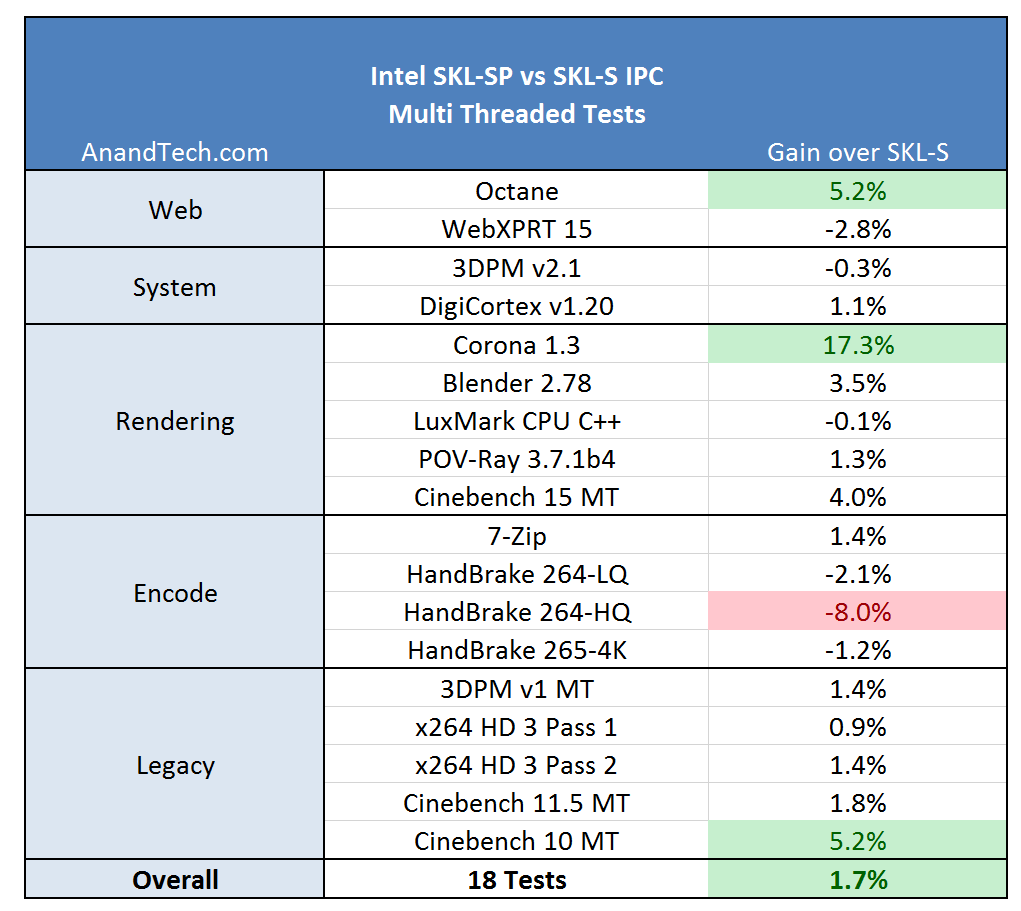
On the multithreaded tests, the big winner here was Corona. Corona is a high-performance renderer for Autodesk 3ds Max, showing that the larger L2 does a good job with its code base. The step back was in Handbrake – our testing does not implement any AVX512 code, but the L3 victim cache might be at play here over the L3 inclusive cache in SKL-S.
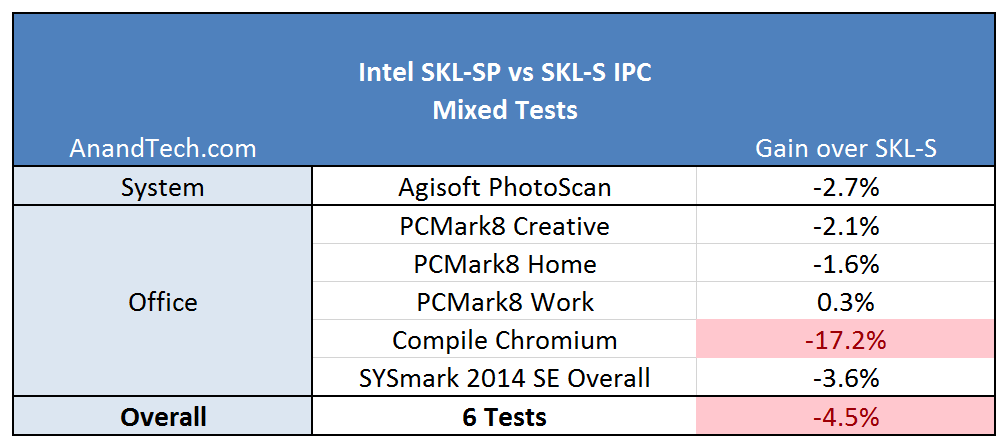
The mixed results are surprising: these tests vary with ST and MT parts to their computation, some being cache sensitive as well. The big outlier here is the compile test, indicating that the Skylake-SP might not be (clock for clock) a great compilation core. This is a result we can trace back to the L3 again, being a smaller non-inclusive cache. In our results database, we can see similar results when comparing a Ryzen 7 1700X, an 8-core 95W CPU with 16MB of L3 victim cache, is easily beaten by a Core i7-7700T, with 4 cores at 35W but has 8MB of inclusive L3 cache.
If we treat each of these tests with equal weighting, the overall result will offer a +0.5% gain to the new Skylake-SP core, which is with the margin of error. Nothing too much to be concerned about for most users (except perhaps people who compile all day), although again, these two cores are not in chips that directly compete. The 10-core SKL-SP chip still does the business on compiling:
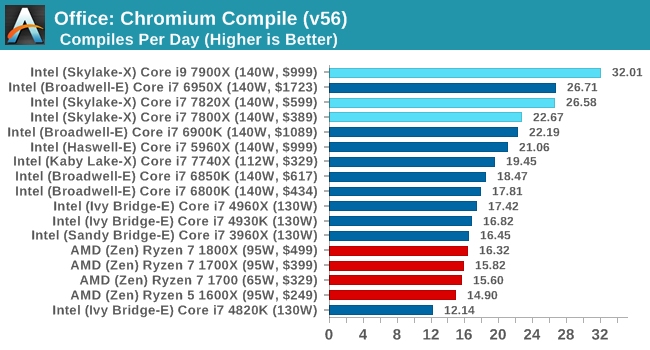
If all these changes (minus AVX512) offer a +0.5% gain over the standard Skylake-S core, then one question worth asking is what was the point? The answer is usually simple, and I suspect involves scaling (moving to chips with more cores), but also customer related. Intel’s big money comes from the enterprise, and no doubt some of Intel’s internal metrics (as well as customer requests) point to a sizeable chunk of enterprise compute being L2 size limited. I’ll be looking forward to Johan’s review on the enterprise side when the time comes.








264 Comments
View All Comments
Tephereth - Tuesday, June 20, 2017 - link
"For each of the GPUs in our testing, these games (at each resolution/setting combination) are run four times each, with outliers discarded. Average frame rates, 99th percentiles and 'Time Under x FPS' data is sorted, and the raw data is archived."So... where the hell are the games benchmarks in this review?
beck2050 - Tuesday, June 20, 2017 - link
The possibility of the 18 core beast in the upcoming Mac Pro is really exciting for music pros.That is a tremendous and long overdue leap for power users.
drajitshnew - Tuesday, June 20, 2017 - link
"... and only three PCIe 3.0 x4 drives can use the in-built PCIe RAID"I would like to know which raid level you would use. I can't see 3 m2 drives in raid 1, and raid 5 would require access to the cpu for parity calculations. Then raid 0 it is. Now, which drives will you use for raid 0, which do not saturate the DMI link for sequential reads? And if your workload does not have predominantly sequential reads, then why are you putting the drives in raid.
PeterCordes - Tuesday, June 20, 2017 - link
Standard motherboard RAID controllers are software raid anyway, where the OS drivers queue up writes to each drive separately, instead of sending the data once over the PCIe bus to a hardware RAID controller which queues writes to two drives.What makes it a "raid controller" is that you can boot from it, thanks to BIOS support. Otherwise it's not much different from Linux or Windows pure-software RAID.
If the drivers choose to implement RAID5, that can give you redundancy on 3 drives with the capacity of 2.
However, RAID5 on 3 disks is not the most efficient way. A RAID implementation can get the same redundancy by just storing two copies of every block, instead of generating parity. That avoids a ton of RAID5 performance problems, and saves CPU time. Linux md software RAID implements this as RAID10. e.g. RAID10f2 stores 2 copies of every block, striped across as many disks as you have. It works very well with 3 disks. See for example https://serverfault.com/questions/139022/explain-m...
IDK if Intel's mobo RAID controllers support anything like that or not. I don't use the BIOS to configure my RAID; I just put a boot partition on each disk separately and manage everything from within Linux. IDK if other OSes have soft-raid that supports anything similar either.
> And if your workload does not have predominantly sequential reads, then why are you putting the drives in raid.
That's a silly question. RAID0, RAID1, and RAID5 over 3 disks should all have 3x the random read throughput of a single disk, at least for high queue depths, since each disk will only see about 1/3rd of the reads. RAID0 similarly has 3x random write throughput.
RAID10n2 of 3 disks can have better random write throughput than a single disk, but RAID5 is much worse. RAID1 of course mirrors all the writes to all the disks, so it's a wash for writes. (But can still gain for mixed read and write workloads, since the reads can be distributed among the disks).
Lieutenant Tofu - Tuesday, June 20, 2017 - link
I wonder why 1600X outperforms 1800X here on WebXPRT. It's not a huge difference, but I don't see why it's happening. 6-core vs. 8-core, 3.6 GHz base, 4.0 GHz turbo. This presumably runs in just one thread, so performance should be nearly identical. The only reason I can think of is less contention across the IF on the 1600X due to less enabled cores, but don't see that having a major effect on a single-threaded test like this one.Maybe 1600X can XFR to a little higher than the 1800X.
Eyered - Tuesday, June 20, 2017 - link
Did they have any issues with heat at all?mat9v - Tuesday, June 20, 2017 - link
If that were so everyone would be using HEDT instead of 4c/8t CPUsmat9v - Tuesday, June 20, 2017 - link
Then why again why aren't every workstation consist of dual cpu xeons? If the expense is so insignificant compared to how much faster machine will earn...mat9v - Tuesday, June 20, 2017 - link
I'm just wondering how did 7900X menage to stay within 140W bracket during Prome95 tests when in other reviews it easily reached 250W or more. Is it some internal throttling mechanism that keeps CPU constantly dynamically underclocked to stay within power envelope? How does such compare to forced 4Ghz CPU clock?mat9v - Tuesday, June 20, 2017 - link
And yet in conclusion you say to play it safe and get 7900X ?How does that work together?