The Intel Skylake-X Review: Core i9 7900X, i7 7820X and i7 7800X Tested
by Ian Cutress on June 19, 2017 9:01 AM ESTBenchmarking Performance: CPU System Tests
Our first set of tests is our general system tests. These set of tests are meant to emulate more about what people usually do on a system, like opening large files or processing small stacks of data. This is a bit different to our office testing, which uses more industry standard benchmarks, and a few of the benchmarks here are relatively new and different.
PDF Opening
First up is a self-penned test using a monstrous PDF we once received in advance of attending an event. While the PDF was only a single page, it had so many high-quality layers embedded it was taking north of 15 seconds to open and to gain control on the mid-range notebook I was using at the time. This put it as a great candidate for our 'let's open an obnoxious PDF' test. Here we use Adobe Reader DC, and disable all the update functionality within. The benchmark sets the screen to 1080p, opens the PDF to in fit-to-screen mode, and measures the time from sending the command to open the PDF until it is fully displayed and the user can take control of the software again. The test is repeated ten times, and the average time taken. Results are in milliseconds.
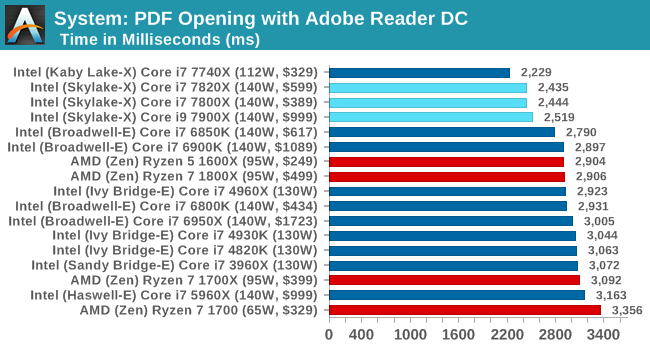
The extra frequency of the new processors is helping when it comes to opening our monster PDF, but also the extra L2 cache is likely having an effect as well.
FCAT Processing
One of the more interesting workloads that has crossed our desks in recent quarters is FCAT - the tool we use to measure stuttering in gaming due to dropped or runt frames. The FCAT process requires enabling a color-based overlay onto a game, recording the gameplay, and then parsing the video file through the analysis software. The software is mostly single-threaded, however because the video is basically in a raw format, the file size is large and requires moving a lot of data around. For our test, we take a 90-second clip of the Rise of the Tomb Raider benchmark running on a GTX 980 Ti at 1440p, which comes in around 21 GB, and measure the time it takes to process through the visual analysis tool.
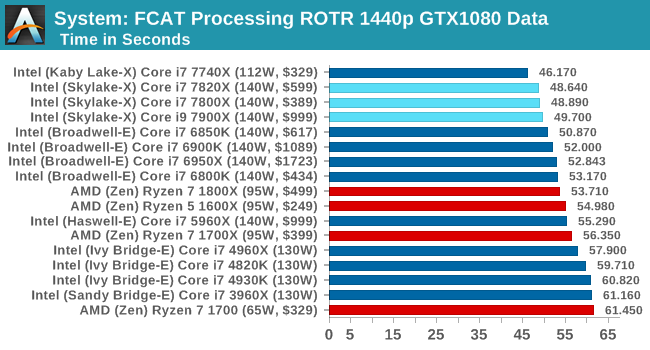
FCAT takes in a frame, processes it and dumps it, all on a single thread. The quicker you get through the workload the better, and frequency is supreme, hence we get the 7820X followed by the 7800X then the 7900X. Even though the 7900X has the higher turbo here, the results are with the margin expected.
3D Particle Movement v2.1
This is the latest version of the self-penned 3DPM benchmark. The goal of 3DPM is to simulate semi-optimized scientific algorithms taken directly from my doctorate thesis. Version 2.1 improves over 2.0 by passing the main particle structs by reference rather than by value, and decreasing the amount of double->float->double recasts the compiler was adding in. It affords a ~25% speed-up over v2.0, which means new data.
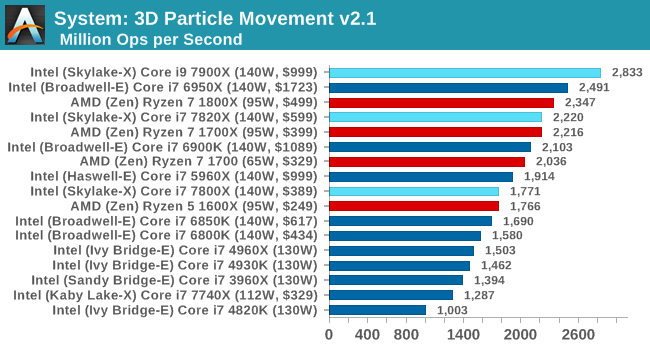
Give 3DPMv2.1 some cores, and it will show you the world / some numbers. The 1800X and 6950X were gunning for top spot, but the extra frequency of the 7900X wins here.
DigiCortex 1.20
Despite being a couple of years old, the DigiCortex software is a pet project for the visualization of neuron and synapse activity in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron/1.8B synapse simulation. The results on the output are given as a fraction of whether the system can simulate in real-time, so anything above a value of one is suitable for real-time work. The benchmark offers a 'no firing synapse' mode, which in essence detects DRAM and bus speed, however we take the firing mode which adds CPU work with every firing.
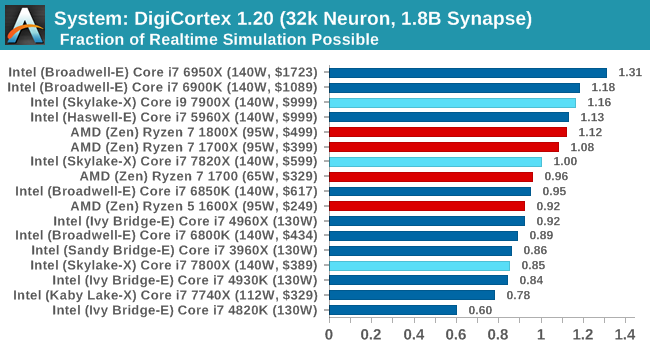
DigiCortex loves a bit of memory, although when speaking with the developer, there can some instances where the beast needs to be fed. Losing the inclusive L3 might be a factor here, especially with the 7800X all the way down.
Agisoft Photoscan 1.0
Photoscan stays in our benchmark suite from the previous version, however now we are running on Windows 10 so features such as Speed Shift on the latest processors come into play. The concept of Photoscan is translating many 2D images into a 3D model - so the more detailed the images, and the more you have, the better the model. The algorithm has four stages, some single threaded and some multi-threaded, along with some cache/memory dependency in there as well. For some of the more variable threaded workload, features such as Speed Shift and XFR will be able to take advantage of CPU stalls or downtime, giving sizeable speedups on newer microarchitectures.
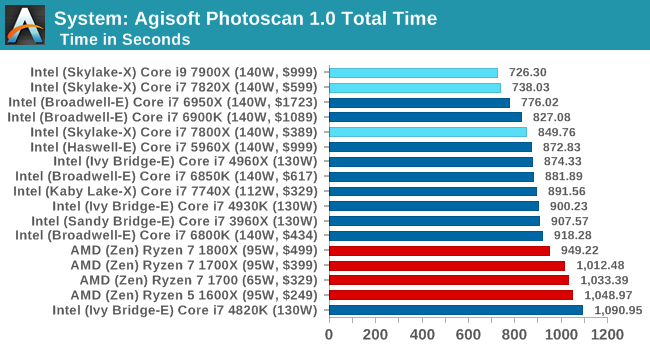
Photoscan is a mixed bag of operations, going through single thread sections to multithread and a range of cache/memory bandwidth requirepements. There's not much difference between thw 10 core and the 8 core, but the frequency helps against Broadwell-E.








264 Comments
View All Comments
Tephereth - Tuesday, June 20, 2017 - link
"For each of the GPUs in our testing, these games (at each resolution/setting combination) are run four times each, with outliers discarded. Average frame rates, 99th percentiles and 'Time Under x FPS' data is sorted, and the raw data is archived."So... where the hell are the games benchmarks in this review?
beck2050 - Tuesday, June 20, 2017 - link
The possibility of the 18 core beast in the upcoming Mac Pro is really exciting for music pros.That is a tremendous and long overdue leap for power users.
drajitshnew - Tuesday, June 20, 2017 - link
"... and only three PCIe 3.0 x4 drives can use the in-built PCIe RAID"I would like to know which raid level you would use. I can't see 3 m2 drives in raid 1, and raid 5 would require access to the cpu for parity calculations. Then raid 0 it is. Now, which drives will you use for raid 0, which do not saturate the DMI link for sequential reads? And if your workload does not have predominantly sequential reads, then why are you putting the drives in raid.
PeterCordes - Tuesday, June 20, 2017 - link
Standard motherboard RAID controllers are software raid anyway, where the OS drivers queue up writes to each drive separately, instead of sending the data once over the PCIe bus to a hardware RAID controller which queues writes to two drives.What makes it a "raid controller" is that you can boot from it, thanks to BIOS support. Otherwise it's not much different from Linux or Windows pure-software RAID.
If the drivers choose to implement RAID5, that can give you redundancy on 3 drives with the capacity of 2.
However, RAID5 on 3 disks is not the most efficient way. A RAID implementation can get the same redundancy by just storing two copies of every block, instead of generating parity. That avoids a ton of RAID5 performance problems, and saves CPU time. Linux md software RAID implements this as RAID10. e.g. RAID10f2 stores 2 copies of every block, striped across as many disks as you have. It works very well with 3 disks. See for example https://serverfault.com/questions/139022/explain-m...
IDK if Intel's mobo RAID controllers support anything like that or not. I don't use the BIOS to configure my RAID; I just put a boot partition on each disk separately and manage everything from within Linux. IDK if other OSes have soft-raid that supports anything similar either.
> And if your workload does not have predominantly sequential reads, then why are you putting the drives in raid.
That's a silly question. RAID0, RAID1, and RAID5 over 3 disks should all have 3x the random read throughput of a single disk, at least for high queue depths, since each disk will only see about 1/3rd of the reads. RAID0 similarly has 3x random write throughput.
RAID10n2 of 3 disks can have better random write throughput than a single disk, but RAID5 is much worse. RAID1 of course mirrors all the writes to all the disks, so it's a wash for writes. (But can still gain for mixed read and write workloads, since the reads can be distributed among the disks).
Lieutenant Tofu - Tuesday, June 20, 2017 - link
I wonder why 1600X outperforms 1800X here on WebXPRT. It's not a huge difference, but I don't see why it's happening. 6-core vs. 8-core, 3.6 GHz base, 4.0 GHz turbo. This presumably runs in just one thread, so performance should be nearly identical. The only reason I can think of is less contention across the IF on the 1600X due to less enabled cores, but don't see that having a major effect on a single-threaded test like this one.Maybe 1600X can XFR to a little higher than the 1800X.
Eyered - Tuesday, June 20, 2017 - link
Did they have any issues with heat at all?mat9v - Tuesday, June 20, 2017 - link
If that were so everyone would be using HEDT instead of 4c/8t CPUsmat9v - Tuesday, June 20, 2017 - link
Then why again why aren't every workstation consist of dual cpu xeons? If the expense is so insignificant compared to how much faster machine will earn...mat9v - Tuesday, June 20, 2017 - link
I'm just wondering how did 7900X menage to stay within 140W bracket during Prome95 tests when in other reviews it easily reached 250W or more. Is it some internal throttling mechanism that keeps CPU constantly dynamically underclocked to stay within power envelope? How does such compare to forced 4Ghz CPU clock?mat9v - Tuesday, June 20, 2017 - link
And yet in conclusion you say to play it safe and get 7900X ?How does that work together?