The Intel Kaby Lake-X i7 7740X and i5 7640X Review: The New Single-Threaded Champion, OC to 5GHz
by Ian Cutress on July 24, 2017 8:30 AM EST- Posted in
- CPUs
- Intel
- Kaby Lake
- X299
- Basin Falls
- Kaby Lake-X
- i7-7740X
- i5-7640X
Benchmarking Performance: CPU System Tests
Our first set of tests is our general system tests. These set of tests are meant to emulate more about what people usually do on a system, like opening large files or processing small stacks of data. This is a bit different to our office testing, which uses more industry standard benchmarks, and a few of the benchmarks here are relatively new and different.
All of our benchmark results can also be found in our benchmark engine, Bench.
PDF Opening
First up is a self-penned test using a monstrous PDF we once received in advance of attending an event. While the PDF was only a single page, it had so many high-quality layers embedded it was taking north of 15 seconds to open and to gain control on the mid-range notebook I was using at the time. This put it as a great candidate for our 'let's open an obnoxious PDF' test. Here we use Adobe Reader DC, and disable all the update functionality within. The benchmark sets the screen to 1080p, opens the PDF to in fit-to-screen mode, and measures the time from sending the command to open the PDF until it is fully displayed and the user can take control of the software again. The test is repeated ten times, and the average time taken. Results are in milliseconds.

PDF opening is all about single thread frequency and IPC, giving the win to the new KBL-X chips.
FCAT Processing: link
One of the more interesting workloads that has crossed our desks in recent quarters is FCAT - the tool we use to measure stuttering in gaming due to dropped or runt frames. The FCAT process requires enabling a color-based overlay onto a game, recording the gameplay, and then parsing the video file through the analysis software. The software is mostly single-threaded, however because the video is basically in a raw format, the file size is large and requires moving a lot of data around. For our test, we take a 90-second clip of the Rise of the Tomb Raider benchmark running on a GTX 980 Ti at 1440p, which comes in around 21 GB, and measure the time it takes to process through the visual analysis tool.
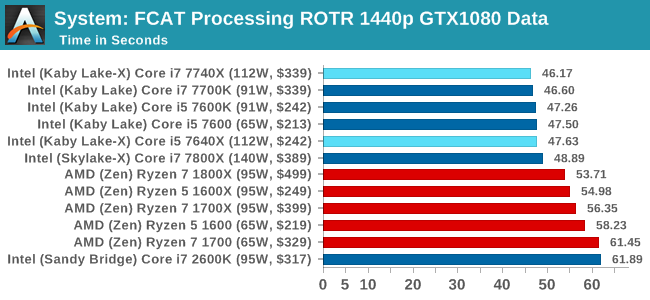
FCAT similarly favors frequency and IPC. For this sort of workload, the Core i7 is the best chip to get.
3D Movement Algorithm Test v2.1: link
This is the latest version of the self-penned 3DPM benchmark. The goal of 3DPM is to simulate semi-optimized scientific algorithms taken directly from my doctorate thesis. Version 2.1 improves over 2.0 by passing the main particle structs by reference rather than by value, and decreasing the amount of double->float->double recasts the compiler was adding in. It affords a ~25% speed-up over v2.0, which means new data.
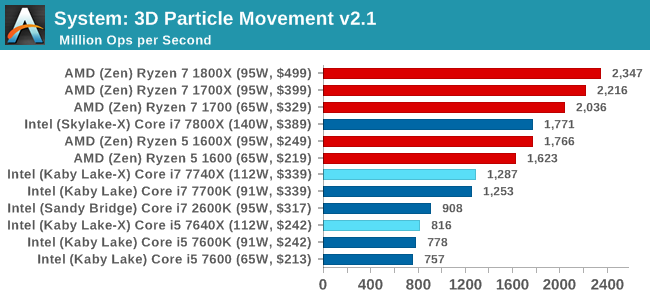
As 3DPM expands into several threads, the new quad-core parts will easily get trounced here by AMD's 8-cores for the same price. The Core i7-7800X puts on a good showing, as per core Intel's chips give a higher score.
DigiCortex v1.20: link
Despite being a couple of years old, the DigiCortex software is a pet project for the visualization of neuron and synapse activity in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron/1.8B synapse simulation. The results on the output are given as a fraction of whether the system can simulate in real-time, so anything above a value of one is suitable for real-time work. The benchmark offers a 'no firing synapse' mode, which in essence detects DRAM and bus speed, however we take the firing mode which adds CPU work with every firing.
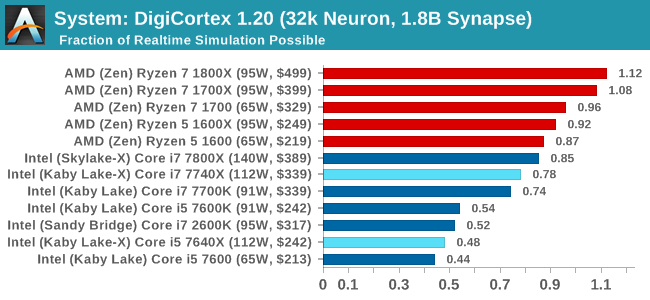
DigiCortex likes a bit of everything: cores, threads, IPC, frequency, uncore frequency, and memory frequency. The Core i7 parts roughly double the Core i5s due to the thread count, and also the AMD Ryzen parts skip ahead as well due to having double the threads to the Core i7.
Agisoft Photoscan 1.0: link
Photoscan stays in our benchmark suite from the previous version, however now we are running on Windows 10 so features such as Speed Shift on the latest processors come into play. The concept of Photoscan is translating many 2D images into a 3D model - so the more detailed the images, and the more you have, the better the model. The algorithm has four stages, some single threaded and some multi-threaded, along with some cache/memory dependency in there as well. For some of the more variable threaded workload, features such as Speed Shift and XFR will be able to take advantage of CPU stalls or downtime, giving sizeable speedups on newer microarchitectures.
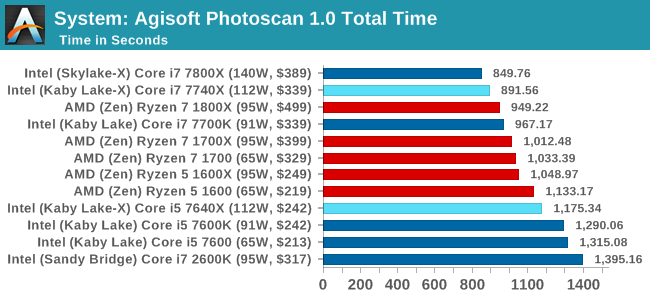
Agisoft is like a Formula 1 race circuit: the long fast straights and techical corners make it a nightmare to have the technology to be the best at both, and Photoscan has enough serial code for high single thread performance to take advantage but also massively parallel sections where having 12-18 threads makes a difference. Despite having half the threads, the single core performance of the Core i7-7740X makes it pull ahead of the Ryzen 7 chips, but when comparing the four threads of the Core i5-7640X to the twelve threads of the Ryzen 5 processors, having 12 threads wins.








176 Comments
View All Comments
iwod - Monday, July 24, 2017 - link
Intel has 10nm and 7nm by 2020 / 2021. Core Count is basically a solved problem, limited only by price.What we need is a substantial breakthrough in single thread performance. May be there are new material that could bring us 10+Ghz. But those aren't even on the 5 years roadmap.
mapesdhs - Monday, July 24, 2017 - link
That's more down to better sw tech, which alas lags way behind. It needs skills that are largely not taught in current educational establishments.wolfemane - Monday, July 24, 2017 - link
Under Handbrake testing, just above the first graph you state:"Low Quality/Resolution H264: He we transcode a 640x266 H264 rip of a 2 hour film, and change the encoding from Main profile to High profile, using the very-fast preset."
I think you mean to say "HERE we transcode..."
Great article overall. Thank you!
Ian Cutress - Monday, July 24, 2017 - link
Thanks, corrected :)wolfemane - Monday, July 24, 2017 - link
I wish your team would finally add in an edit button to comments! :)On the last graph ENCODING: Handbrake HEVC (4k) you don't list the 1800x, but it is present in the previous two graphs @ LQ and HQ. Was there an issue with the 1800x preventing 4k testing? Quite interested in it's results if you have them.
Ian Cutress - Monday, July 24, 2017 - link
When I first did the HEVC testing for the Ryzen 7 review, there was a slight issue in it running and halfway through I had to change the script because the automation sometimes dropped a result (like the 1800X which I didn't notice until I was 2-3 CPUs down the line). I need to put the 1800X back on anyway for AGESA 1006, which will be in an upcoming article.IanHagen - Monday, July 24, 2017 - link
One thing that caught my eye for a while is how compile tests using GCC or clang show much better results on Ryzen compared to using Microsoft's VS compiler. Phoronix tests clearly shows that. Thus, I cannot really believe yet on Ian's recurring explanation of Ryzen suffering from its victim L3 cache. After all, the 1800X beats the 7700K by a sizable margin when compiling the Linux kernel.Isn't Ryzen relatively poor performance compiling Chromium due to idiosyncrasies of the VS compiler?
Ian Cutress - Monday, July 24, 2017 - link
The VS compiler seems to love L3 cache, then. The 1800X does have 2x threads and 2x cores over the 7700K, accounting for the difference. We saw a -17% drop going from SKL-S with its fully inclusive L3 to SKL-SP with a victim L3, clock for clock.Chromium was the best candidate for a scripted, consistent compile workflow I could roll into our new suite (and runs on Windows). Always open for suggestions that come with an ELI5.
ddriver - Monday, July 24, 2017 - link
So we are married to chromium, because it only compiles with msvc on windows?Or maybe because it is a shitty implementation that for some reason stacks well with intel's offerings?
Pardon my ignorance, I've only been a multi-platform software developer for 8 years, but people who compile stuff a lot usually don't compile chromium all day.
I'd say go GCC or Clang, because those are quality community drive open source compilers that target a variety of platforms, unlike msvc. I mean if you really want to illustrate the usefulness of CPUs for software developers, which at this point is rather doubtful...
Ian Cutress - Monday, July 24, 2017 - link
Again, find me something I can rope into my benchmark suite with an ELI5 guide and I try and find time to look into it. The Chromium test took the best part of 2-3 days to get in a position where it was scripted and repeatable and fit with our workflow - any other options I examined weren't even close. I'm not a computer programmer by day either, hence the ELI5 - just years old knowledge of using Commodore BASIC, batch files, and some C/C++/CUDA in VS.