Exploring DynamIQ and ARM’s New CPUs: Cortex-A75, Cortex-A55
by Matt Humrick on May 29, 2017 12:00 AM EST- Posted in
- Smartphones
- CPUs
- Arm
- Mobile
- Cortex
- DynamIQ
- Cortex A75
- Cortex A55
Cortex-A55 Microarchitecture
The Cortex-A55 is the next CPU microarchitecture in ARM’s Cambridge family of low-power, small-footprint cores, which also include the A5, A7, and A53. This new little core is an evolution of the A53, so the two cores share much in common. Using the A53 as the starting point makes sense—it has proven to be a successful design—but as the big cores evolved over time, the performance gap between the big cores and the A53 grew, altering the balance in ARM’s big.LITTLE scheme. And as ARM continues its push into new markets beyond mobile, it needs new features that the A53 lacks. The A55 addresses the performance issue with improvements to the memory system and other microarchitectural changes and adds key features by moving from the ARMv8.0 architecture to ARMv8.2.
At a high level, the A55 is still a dual-issue, in-order CPU with an 8-stage pipeline. According to ARM, 8 stages is still the sweet spot, because it’s not seeing significant frequency improvements when moving from 16/14nm to 10nm to 7nm (most of the process gains are with area scaling and reduced dynamic/leakage power). With 8 stages, the A55 should reach a similar peak frequency as A53. Moving to a shorter pipeline would reduce the max frequency without a significant improvement to power or area, while a longer pipeline would increase area and power consumption for only a small frequency gain.
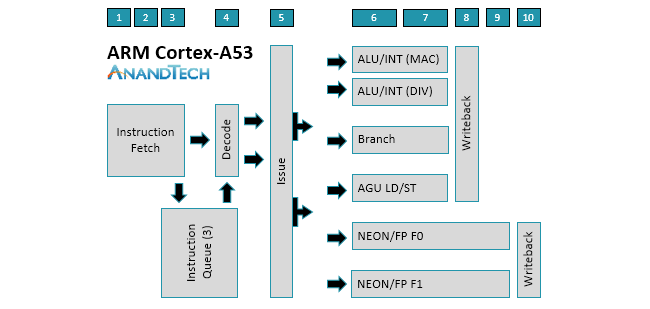
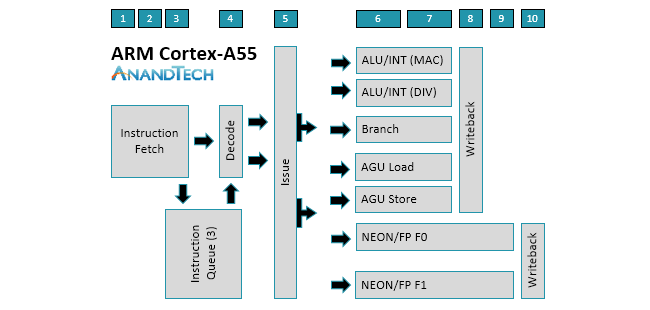
The similarities between the two cores is evident when examining the diagrams above. There’s still a 2-wide decode stage that decodes most instructions in a single cycle. Another feature that carries over from A53 is symmetric dual-issue for most instructions, meaning both issue slots can feed instructions to any pipeline. We’ll cover the execution pipelines in more detail below, but the big change here is that the A55 moves to independent load and store AGUs that can perform loads and stores in parallel instead of a single, combined AGU like the A53.
The A53’s core already provides good throughput, but not having instructions or data ready to process, perhaps because of a mispredicted branch or a cache miss, nullifies this advantage. Without the ability to execute instructions out of order while the CPU waits to fetch an instruction or data from elsewhere in the memory hierarchy, the entire core can stall (all other instructions need to wait for the current instruction to finish), so keeping an in-order core fed with instructions and data is critical. This is why ARM focused heavily on improving the A55’s memory system performance.
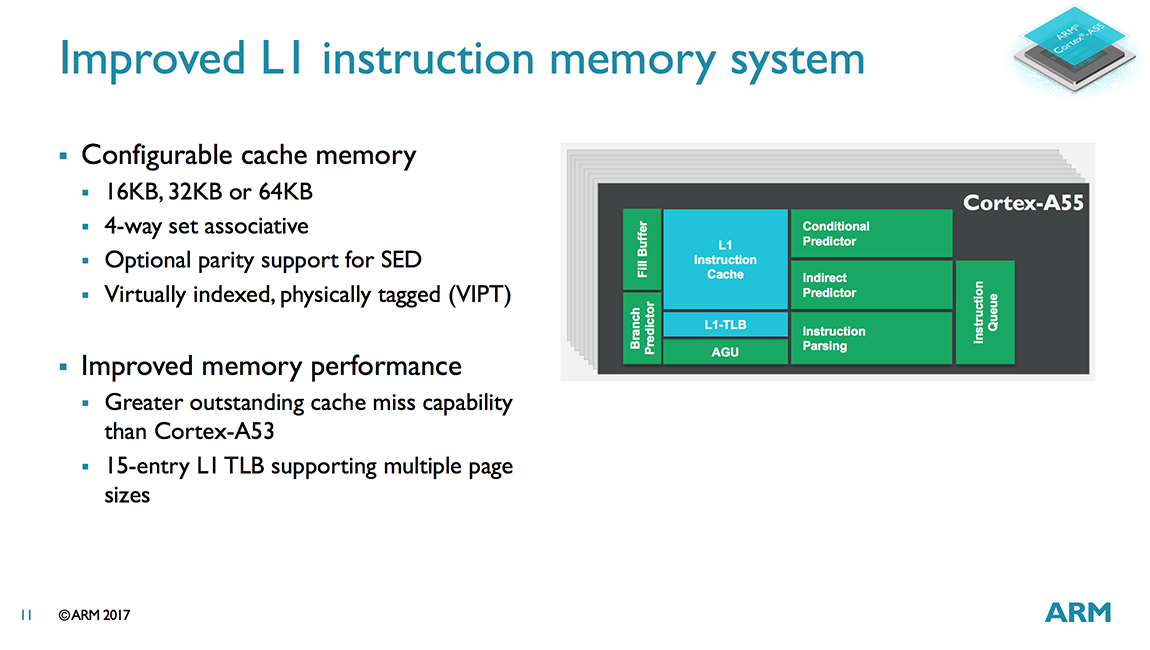
Starting on the instruction side, the L1 I-cache is now 4-way set associative versus 2-way for the A53. It’s still VIPT (Virtually Indexed, Physically Tagged), which is commonly used for L1 caches as it reduces latency, but there’s a larger 15-entry L1 TLB that supports multiple page sizes. This simple-sounding change actually required a significant amount of work to alleviate issues with timing pressure. The size of the L1 I-cache is configurable with options for 16KB, 32KB, or 64KB, which is similar to the A53 that offers a range from 8KB to 64KB.
It seems that every new CPU microarchitecture comes with a new branch predictor, and the A55 is no exception. The new conditional predictor increases prediction accuracy by using neural network based algorithms. It also adds loop termination prediction, which avoids a mispredict occurring at the end of a loop. There are also new 0-cycle micro-predictors ahead of the main conditional predictor. These are not as accurate as the main predictor, but their ability to perform predictions back to back to back provide a significant performance uplift by reducing pipeline bubbles even in tight loops. There’s also an indirect predictor that’s only used when necessary, reducing the power penalty because indirect branches do not occur as frequently. This includes a 256-entry BTAC (Branch Target Address Cache).
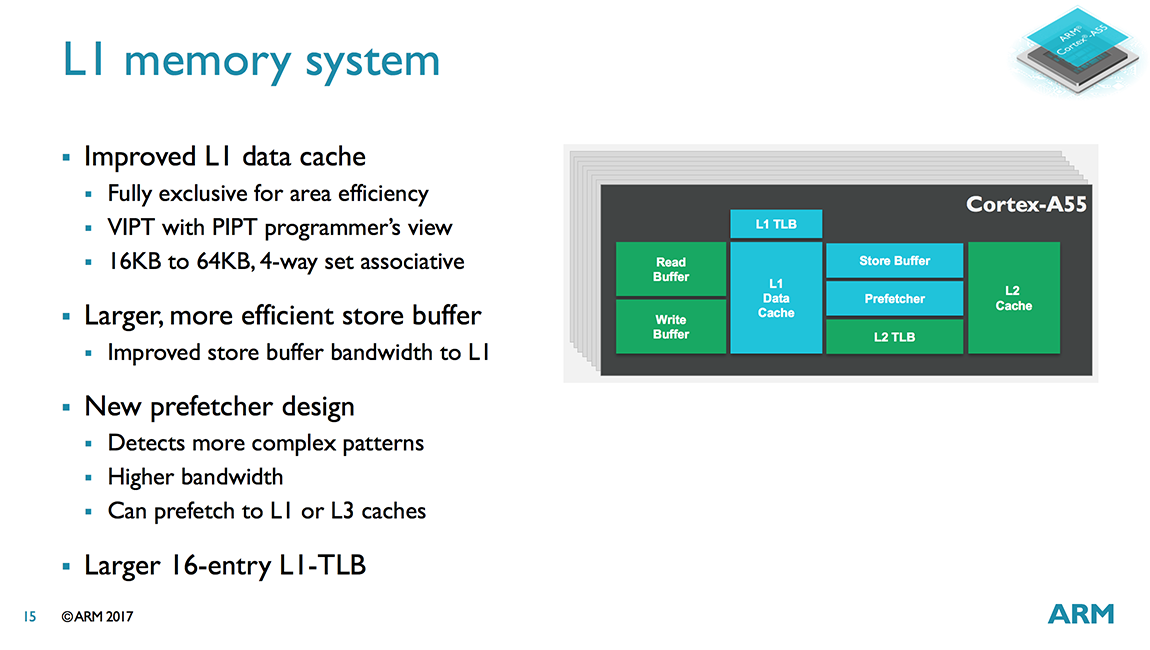
Switching over to the data path, the A55 includes an improved data prefetcher that delivers higher bandwidth. It’s capable of detecting more complex cache miss patterns and can prefetch to the L1 or L3 caches. ARM expects these improvements to make a noticeable impact on mobile device UI performance.
The L1 D-cache is still 4-way set associative like the A53, but is now fully-exclusive instead of pseudo-exclusive, which saves area because data is not duplicated in the L2 cache. The size of the L1 D-cache is also configurable with 16KB, 32KB, or 64KB options, which is also similar to the A53’s range from 8KB to 64KB.
Another big change for the L1 D-cache is moving from a PIPT (Physically Indexed, Physically Tagged) to a VIPT access scheme. This reduces cache latency because the cache index lookup happens in parallel with the TLB translation, but also creates aliasing issues where several virtual addresses might reference the same physical address. The A55 deals with aliasing in hardware, however, making the VIPT cache appear like a PIPT cache to the programmer.
Further enhancements include a larger 16-entry micro-TLB for the L1 D-cache, a significant increase over the A53’s 10-entry micro-TLB, and a larger store buffer with higher bandwidth into the L1 to better cope with workloads that generate a lot of stores. ARM also reduced the L1 pointer chasing load-to-use latency from 3 cycles in A53 to 2 cycles in A55, providing a small performance bump when working with certain types of data structures.
Being compatible with DynamIQ means the A55 gets an integrated L2 cache that operates at core speed. This reduces L2 latency by 50% (12 cycles to 6 cycles) compared to the A53 and its shared L2. The L2 cache size options include 0KB, 64KB, 128KB, and 256KB. ARM expects 128KB to be the most common for mobile applications, but there should be a reasonable number of 256KB configurations too. The smaller sizes will appeal to the networking and embedded markets that desire lower area/cost or need more deterministic memory behavior. With the L2 now part of the core, the A55’s L2 TLB grows to 1024 entries up from 512 entries for A53.
The A55’s integrated L2 uses PIPT, which is simpler to implement and uses less power than VIPT. Unlike the VIPT L1, using PIPT for the L2 does not incur a performance penalty because its naturally higher latency means there’s sufficient time to get the physical address from the TLB before performing the tag compare.

The L2 is 4-way set associative like the L1, a design choice meant to minimize cache latency, which is important for reducing the impact of stalls on in-order cores. The downside to using a less associative cache is a greater chance to miss, but ARM feels comfortable with this compromise with an L3 cache sitting reasonably close to the core.
Having access to a (potentially) large L3 cache, something the A53 did not have, will also help improve performance. As previously stated, in-order cores are sensitive to cache misses that cause the core to stall, so they respond particularly well to increases in cache size and reductions in memory access latency. ARM says the A53/A55 sees roughly a 5% performance improvement for each doubling of cache size depending on workload.
We’ll end our tour through the data path and our discussion about the A55’s memory system improvements with the AGUs (Address Generation Units). According to ARM’s internal benchmarking, the CPU can spend a lot of time doing loads and stores, so improving performance here was crucial. Instead of sticking with the A53’s single, combined AGU, the A55 uses independent load and store AGUs that can perform loads and stores in parallel, enabling a higher issue rate into the memory system. Note that the A55’s AGUs are not capable of performing both loads and stores (just one or the other) like the AGUs in the A73/A75, a trade off between performance and complexity.
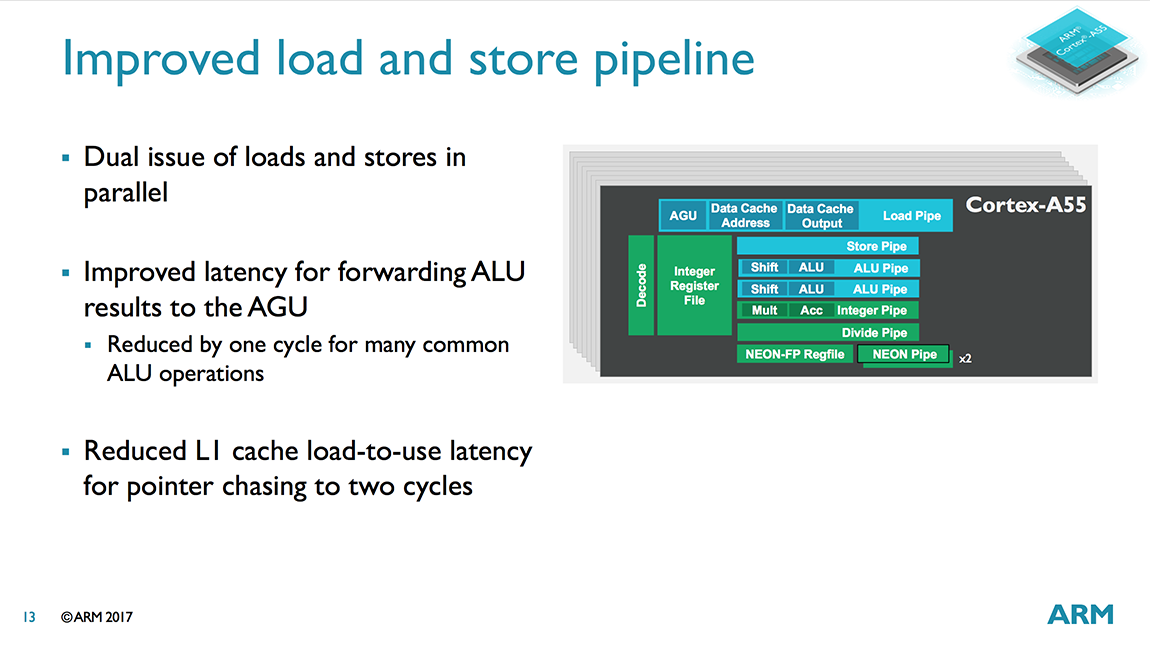
Shifting our focus to the execution pipes, we find 2 ALU/INT units that are functionally the same as the A53’s. Both ALUs can perform basic operations such as additions and shifts, but only one ALU handles integer multiplication and multiply-accumulate operations, while the other focuses on integer division with a Radix-16 divider. So while the A53/A55 cannot perform 2 integer multiplies or divides in parallel, it can dual issue a MUL/MAC alongside a divide/add/shift. The ALUs are still 2 stages, but nearly all instructions complete in 1 cycle. There are also several forwarding paths built in, including paths within the same pipe or cross pipe, to reduce execution latency.
The 2 64-bit NEON/Floating Point pipes are still optional (some markets do not require them) and are served from a dedicated 128-bit register file like the A53. Each SIMD NEON pipe in the A53/A55 can perform 8 8-bit integer, 4 16-bit integer, 2 32-bit integer or single-precision floating-point (FP), or 1 64-bit integer or double-precision FP operations per cycle, giving programmers the flexibility to choose the right balance between precision and performance. As part of its support for the ARMv8.2 architecture, the A55 gains native support for half-precision FP16 operations too. The A53 can fetch FP16 values, but they need to be converted to FP32 before execution. This is no longer the case with A55, so the core performs less work when dealing with FP16 values that are frequently used in some image processing and machine learning applications that require 16-bit precision.

The A55 also includes a new INT8 dot product instruction, another useful addition for machine learning, that offers a 4x performance improvement over the A53 (which increases to about 5x when taking the memory system improvements into account). Instead of executing multiple instructions back to back to back like the A53, the A55 only needs to push a single instruction through the pipe.
One final noteworthy improvement is the ability to do a fused multiply–add (FMA) in a single pass instead of two for the A53, reducing latency from 8 cycles to 4.
The A55 has much in common with the A53, which is not surprising because the A53 already delivers good core throughput. While the A55 gets some improvements to the NEON/FP pipes, mostly from additional instructions courtesy of ARMv8.2, most of its performance gains come from changes to the memory system meant to reduce both the number of core stalls and their latency impact when they do occur.








104 Comments
View All Comments
lilmoe - Monday, May 29, 2017 - link
All of ARM's hope of having any significant, mainstream, server market share was demolished with the announcement of Naples.Wilco1 - Monday, May 29, 2017 - link
Check https://community.arm.com/processors/b/blog/posts/... - at the end there is a whole section on how much faster Cortex-A75 is compared to Cortex-A72 on SPECrate in big server designs. And Cortex-A55 also has all the RAS features required for servers.lilmoe - Monday, May 29, 2017 - link
It's about damn time they're addressing the little cores. We might not get anything better until they go fully OoO on both clusters with 7nm and beyond.Meteor2 - Monday, May 29, 2017 - link
In-order is more efficient, and that's important for 'workhorse' cores, whatever the node. Why waste energy when you don't need to? Like A53, A55 is about doing enough work quick enough, not doing as much as possible as fast as possible. (I think A35 was too weedy for life outside of IoT.)Plus I suspect that the ARM ISA is suited to in-order.
lilmoe - Monday, May 29, 2017 - link
Energy consumption goes down with each process node advancement. The A53 is spending most of its compute time well over 1.2ghz on flagship SoCs. At 1.5ghz and beyond, it starts wasting more energy than the big cluster at similar performance points. Your point is absolutely correct in an "ideal workload", but the real world is far from that with higher resolution screens and all the other crazy peripherals OEMs employ. We'll have to wait and see the performance energy curve first before determining the sweet spot of the a55 vs where most of the actual workload resides.Meteor2 - Friday, June 2, 2017 - link
Haven't seen an energy/performance curve on Anandtech for ages :(nandnandnand - Monday, May 29, 2017 - link
Low tier tech news outlets are saying the A75 has 50% more performance and that the A55 is 2.5x more power efficient:Compare: https://venturebeat.com/2017/05/28/arm-wants-to-bo... which acknowledges "in some use cases"
To: http://www.zdnet.com/article/arm-launches-new-cort... which just says "up to"
50% figure comes from comparing A73 at 2.4 GHz to A75 at 3.0 GHz: https://www.theregister.co.uk/2017/05/29/arm_cpus_...
jjj - Monday, May 29, 2017 - link
The 2.5x claim was on an ARM slide but it included process shrinks.The 50% claim seems to be at 2W per core not 3GHz but even then it clearly isn't in SPEC,maybe in Geekbench it gets close to that gain at 2W.
Krysto - Monday, May 29, 2017 - link
I wouldn't be surprised if we do see some configurations at 7nm like that (3GHz). ARM has always tended to give pretty unrealistic clock speed peak performance for its cores, which no chip maker actually ended up implementing, but I think this time it may be different due to Chromebooks and Windows 10 on ARM, where a 15W TDP or even higher is perfectly fine, as long as you also get good performance/W (compared to Intel/AMD).However, chip makers and OEMs will also have to take into account Windows 10 on ARM emulation, so they'll need to keep those chips at least 10% lower TDP/power consumption than the Intel/AMD competitors at those levels of performance.
jjj - Monday, May 29, 2017 - link
A75 is not aimed at 7nm, that's where the next core comes in.