The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTExecution, Load/Store, INT and FP Scheduling
The execution of micro-ops get filters into the Integer (INT) and Floating Point (FP) parts of the core, which each have different pipes and execution ports. First up is the Integer pipe which affords a 168-entry register file which forwards into four arithmetic logic units and two address generation units. This allows the core to schedule six micro-ops/cycle, and each execution port has its own 14-entry schedule queue.
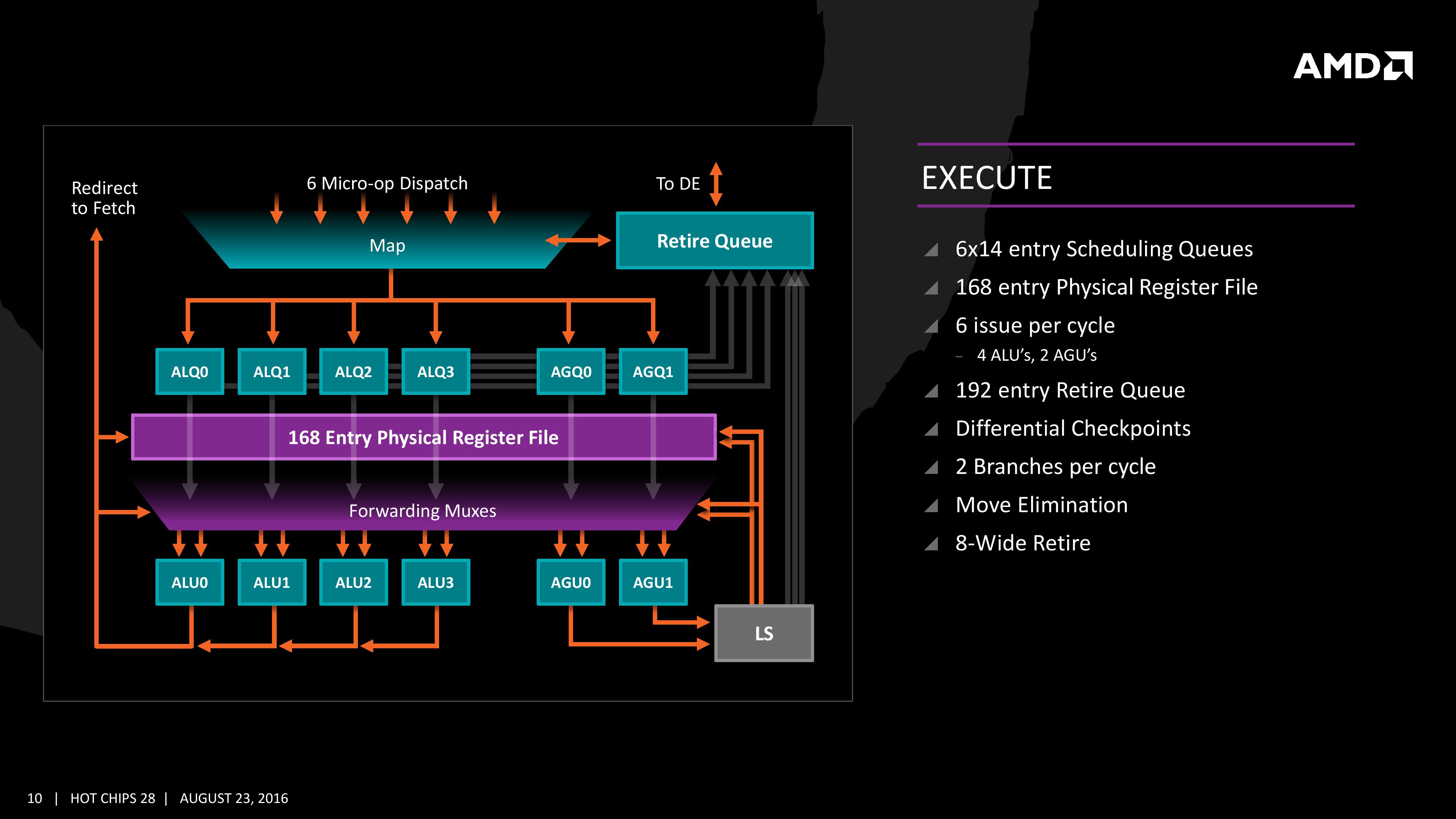
The INT unit can work on two branches per cycle, but it should be noted that not all the ALUs are equal. Only two ALUs are capable of branches, one of the ALUs can perform IMUL operations (signed multiply), and only one can do CRC operations. There are other limitations as well, but broadly we are told that the ALUs are symmetric except for a few focused operations. Exactly what operations will be disclosed closer to the launch date.
The INT pipe will keep track of branching instructions with differential checkpoints, to cut down on storing redundant data between branches (saves queue entries and power), but can also perform Move Elimination. This is where a simple mov command between two registers occurs – instead of inflicting a high energy loop around the core to physically move the single instruction, the core adjusts the pointers to the registers instead and essentially applies a new mapping table, which is a lower power operation.
Both INT and FP units have direct access to the retire queue, which is 192-entry and can retire 8 instructions per cycle. In some previous x86 CPU designs, the retire unit was a limiting factor for extracting peak performance, and so having it retire quicker than dispatch should keep the queue relatively empty and not near the limit.
The Load/Store Units are accessible from both AGUs simultaneously, and will support 72 out-of-order loads. Overall, as mentioned before, the core can perform two 16B loads (2x128-bit) and one 16B store per cycle, with the latter relying on a 44-entry Store queue. The TLB buffer for the L2 cache for already decoded addresses is two level here, with the L1 TLB supporting 64-entry at all page sizes and the L2 TLB going for 1.5K-entry with no 1G pages. The TLB and data pipes are split in this design, which relies on tags to determine if the data is in the cache or to start the data prefetch earlier in the pipeline.
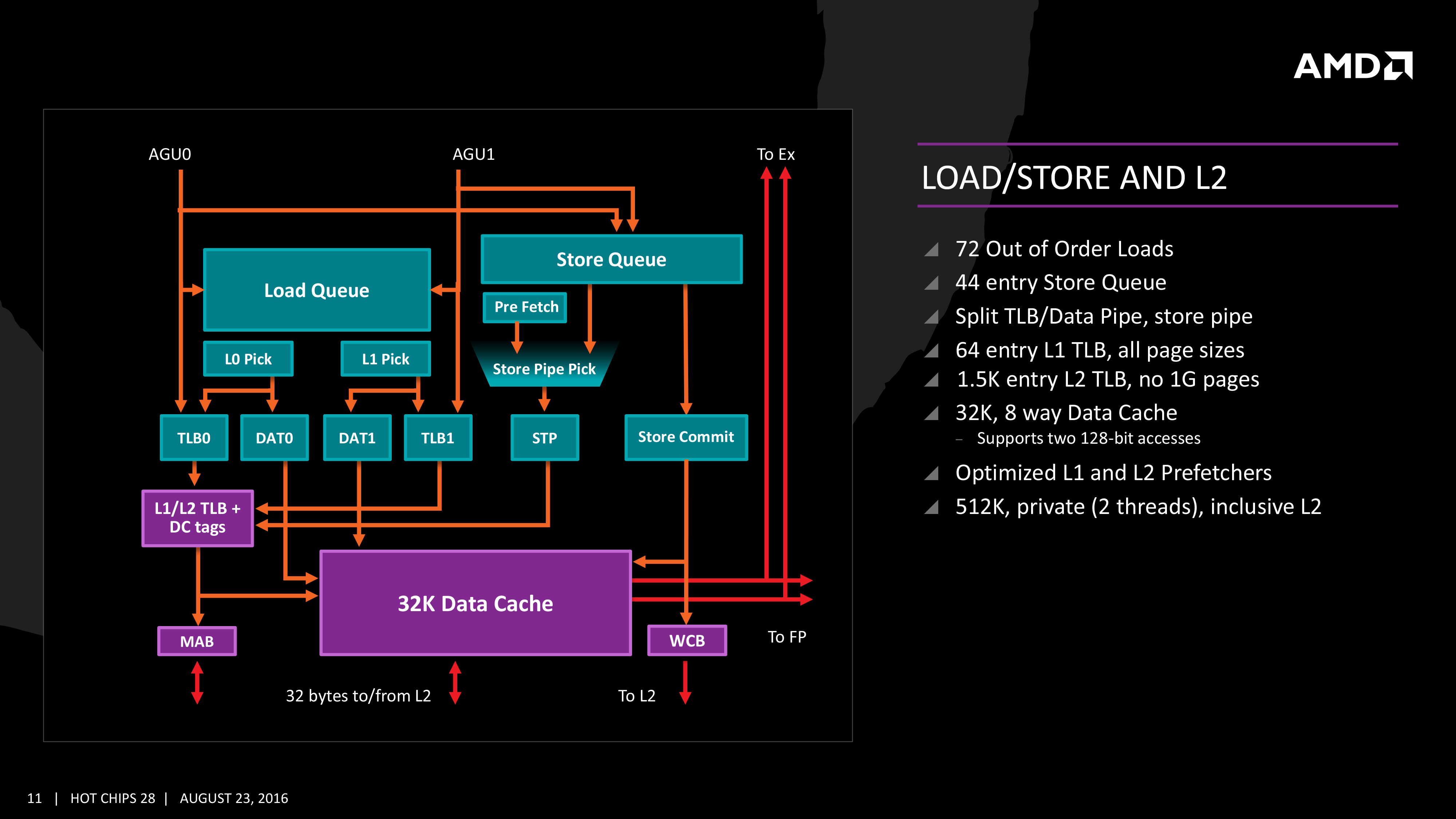
The data cache here also has direct access to the main L2 cache at 32 Bytes/cycle, with the 512 KB 8-way L2 cache being private to the core and inclusive. When data resides back in L1 it can be processed back to either the INT or the FP pipes as required.
Moving onto the floating point part of the core, and the first thing to notice is that there are two scheduling queues here. These are listed as ‘schedulable’ and ‘non-schedulable’ queues with lower power operation when certain micro-ops are in play, but also allows the backup queue to sort out parts of the dispatch in advance via the LDCVT. The register file is 160 entry, with direct FP to INT transfers as required, as well as supporting accelerated recovery on flushes (when data is written to a cache further back in the hierarchy to make room).
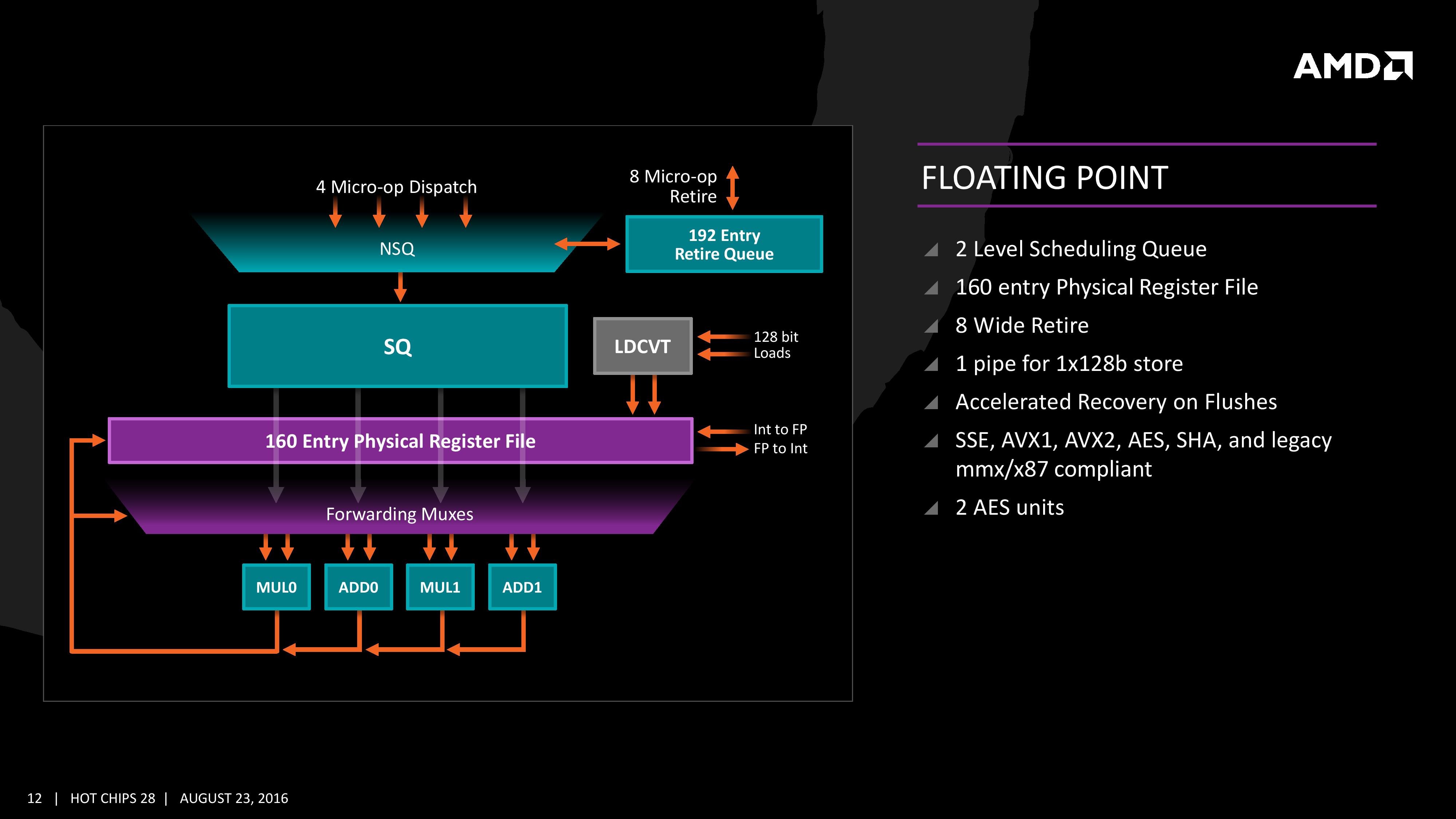
The FP Unit uses four pipes rather than three on Excavator, and we are told that the latency in Zen is reduced as well for operations (though more information on this will come at a later date). We have two MUL and two ADD in the FP unit, capable of joining to form two 128-bit FMACs, but not one 256-bit AVX. In order to do AVX, the unit will split the operations accordingly. On the counter side each core will have 2 AES units for cryptography as well as decode support for SSE, AVX1/2, SHA and legacy mmx/x87 compliant code.








574 Comments
View All Comments
mapesdhs - Sunday, March 5, 2017 - link
If you have a Q6600, I can understand that, but the QX9650 ain't too bad. ;)Marburg U - Monday, March 6, 2017 - link
I'm on a Q9550 running at 3.8 for the past 6 years. I could still run modern games at 1050p, with a r9 270x, but that's the best i can squeeze out of it. Mind that i'm still on DDR2 (my motherboard turns 10 in a few months). I really want to embrace a ultra wide monitor.mapesdhs - Monday, March 6, 2017 - link
Moving up to 2560x1440 may indeed benefit from faster RAM, but it probably depends on the game. Likewise, CPU dependencies vary, and they can lessen at higher resolutions, though this isn't always the case. Still, good point about DDR2 there. To what kind of GPU were you thinking of upgrading? Highend like 1080 Ti? Mid-range? Used GTX 980s are a good deal these days, and a bunch of used 980 Tis will likely hit the market shortly. I've tested 980 SLI with older platforms, actually not too bad, though I've not done tests with my QX9650 yet, started off at the low end to get through the pain. :D (P4/3.4 on an ASUS Striker II Extreme, it's almost embarassing)Ian.
Meditari - Monday, March 6, 2017 - link
I'm actually using a Q9550 that's running at 3.8 as well. I have a 980ti and it can do 4k, albeit at 25-30fps in newer games like Witcher 3. Fairly certain a 1080ti would work great with a Q9550, but I feel like the time for these chips is coming to an end. Still incredible that a 8 year old chip can still hold it's own by just upgrading the GPUmapesdhs - Tuesday, March 7, 2017 - link
Intriguing! Many people don't even try to use such a card on an older mbd, they just assume from sites reviews that it's not worth doing. Can you run 3DMark11/13? What results do you get? You won't be able to cite the URLs here directly, but you can mention the submission numbers and I can compare them to my 980 Ti running on newer CPUs (the first tests I do with every GPU I obtain are with a 5GHz 2700K, at which speed it has the same multithreaded performance as a stock 6700K).What do you get for CB 11.5 and CB R15 single/multi?
What mbd are you using? I ask because some later S775 mbds did use DDR3, albeit not at quite the speeds possible with Z68, etc. In other words, you could move the parts on a better mbd as an intermediate step, though finding such a board could be difficult. Hmm, given the value often placed on such boards, it'd probably be easier to pick up a used 3930K and a board to go with it, that would be fairly low cost.
Or of course just splash for a 1700X. 8)
Ian.
Notmyusualid - Tuesday, March 7, 2017 - link
Welcome to the 21:9 fan club brother.But be careful of the 1920x1080 screens, my brother's 21:9 doesn't look half as good as my 3440x1440 screen.. It just needs that little bit more verticle resoultion.
My pals 4k screen is lovely, and brings his 4GB 980 GTX to its knees. Worse aspect ratio (in my opinion), and too many pixels (for now) to draw.
Careful of second-hand purchases too, many panels with backlight-bleed issues out there, and they are returns for that reason, again, in my opinion.
AnnonymousCoward - Monday, March 6, 2017 - link
Long story short:20% lower single-thread than Intel
70% higher multi-thread due to 8 cores
$330-$500
Mugur - Tuesday, March 7, 2017 - link
Actually, on average -6.8% IPC versus Kaby Lake (at the same frequency) - I believe this came directly from AMD. Add to this a lower grade 14nm process (GF again) that is biting AMD again and again (see last year RX480). Motherboard issues (memory, HPET), OS/application issues (SMT, lack of optimizations).All in all, I'm really impressed of what they achieved with such obstacles.
AnnonymousCoward - Tuesday, March 7, 2017 - link
Just looking at CineBench at a given TDP and price, AMD is 20% lower. That's the high level answer, regardless of IPC * clock frequency. I agree it's a huge win for AMD, and for users who need multicore performance.Cooe - Monday, March 1, 2021 - link
Maybe compare to Intel's Broadwell-E chips with actually similar core counts.... -_-