The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTSimultaneous MultiThreading (SMT)
Zen will be AMD’s first foray into a true simultaneous multithreading structure, and certain parts of the core will act differently depending on their implementation. There are many ways to manage threads, particularly to avoid stalls where one thread is blocking another that ends in the system hanging or crashing. The drivers that communicate with the OS also have to make sure they can distinguish between threads running on new cores or when a core is already occupied – to achieve maximum throughput then four threads should be across two cores, but for efficiency where speed isn’t a factor, perhaps power gating/clock gating half the cores in a CCX is a good idea.
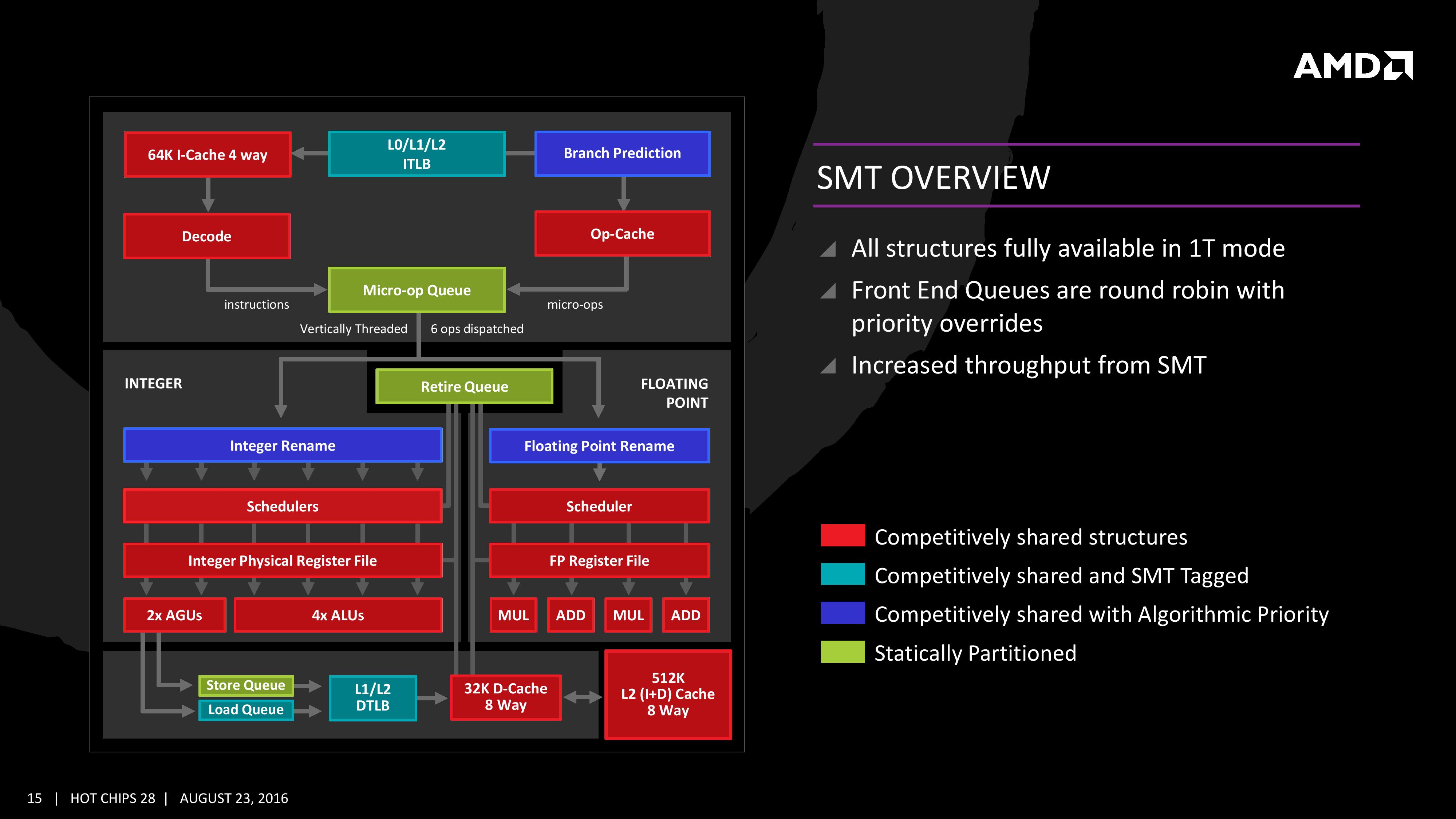
There are a number of ways that AMD will deal with thread management. The basic way is time slicing, and giving each thread an equal share of the pie. This is not always the best policy, especially when you have one performance dominant thread, or one thread that creates a lot of stalls, or a thread where latency is vital. In some methodologies the importance of a thread can be tagged or determined, and this is what we get here, though for some of the structures in the core it has to revert to a basic model.
With each thread, AMD performs internal analysis on the data stream for each to see which thread has algorithmic priority. This means that certain threads will require more resources, or that a branch miss needs to be prioritized to avoid long stall delays. The elements in blue (Branch Prediction, INT/FP Rename) operate on this methodology.
A thread can also be tagged with higher priority. This is important for latency sensitive operations, such as a touch-screen input or immediate user input elements required. The Translation Lookaside Buffers work in this way, to prioritize looking for recent virtual memory address translations. The Load Queue is similarly enabled this way, as typically low latency workloads require data as soon as possible, so the load queue is perfect for this.
Certain parts of the core are statically partitioned, giving each thread an equal timing. This is implemented mostly for anything that is typically processed in-order, such as anything coming out of the micro-op queue, the retire queue and the store queue. However, when running in SMT mode but only with a single thread, the statically partitioned parts of the core can end up as a bottleneck, as they are idle half the time.
The rest of the core is done via competitive scheduling, meaning that if a thread demands more resources it will try to get there first if there is space to do so each cycle.
New Instructions
AMD has a couple of tricks up its sleeve for Zen. Along with including the standard ISA, there are a few new custom instructions that are AMD only.

Some of the new commands are linked with ones that Intel already uses, such as RDSEED for random number generation, or SHA1/SHA256 for cryptography (even with the recent breakthrough in security). The two new instructions are CLZERO and PTE Coalescing.
The first, CLZERO, is aimed to clear a cache line and is more aimed at the data center and HPC crowds. This allows a thread to clear a poisoned cache line atomically (in one cycle) in preparation for zero data structures. It also allows a level of repeatability when the cache line is filled with expected data. CLZERO support will be determined by a CPUID bit.
PTE (Page Table Entry) Coalescing is the ability to combine small 4K page tables into 32K page tables, and is a software transparent implementation. This is useful for reducing the number of entries in the TLBs and the queues, but requires certain criteria of the data to be used within the branch predictor to be met.








574 Comments
View All Comments
mapesdhs - Sunday, March 5, 2017 - link
If you have a Q6600, I can understand that, but the QX9650 ain't too bad. ;)Marburg U - Monday, March 6, 2017 - link
I'm on a Q9550 running at 3.8 for the past 6 years. I could still run modern games at 1050p, with a r9 270x, but that's the best i can squeeze out of it. Mind that i'm still on DDR2 (my motherboard turns 10 in a few months). I really want to embrace a ultra wide monitor.mapesdhs - Monday, March 6, 2017 - link
Moving up to 2560x1440 may indeed benefit from faster RAM, but it probably depends on the game. Likewise, CPU dependencies vary, and they can lessen at higher resolutions, though this isn't always the case. Still, good point about DDR2 there. To what kind of GPU were you thinking of upgrading? Highend like 1080 Ti? Mid-range? Used GTX 980s are a good deal these days, and a bunch of used 980 Tis will likely hit the market shortly. I've tested 980 SLI with older platforms, actually not too bad, though I've not done tests with my QX9650 yet, started off at the low end to get through the pain. :D (P4/3.4 on an ASUS Striker II Extreme, it's almost embarassing)Ian.
Meditari - Monday, March 6, 2017 - link
I'm actually using a Q9550 that's running at 3.8 as well. I have a 980ti and it can do 4k, albeit at 25-30fps in newer games like Witcher 3. Fairly certain a 1080ti would work great with a Q9550, but I feel like the time for these chips is coming to an end. Still incredible that a 8 year old chip can still hold it's own by just upgrading the GPUmapesdhs - Tuesday, March 7, 2017 - link
Intriguing! Many people don't even try to use such a card on an older mbd, they just assume from sites reviews that it's not worth doing. Can you run 3DMark11/13? What results do you get? You won't be able to cite the URLs here directly, but you can mention the submission numbers and I can compare them to my 980 Ti running on newer CPUs (the first tests I do with every GPU I obtain are with a 5GHz 2700K, at which speed it has the same multithreaded performance as a stock 6700K).What do you get for CB 11.5 and CB R15 single/multi?
What mbd are you using? I ask because some later S775 mbds did use DDR3, albeit not at quite the speeds possible with Z68, etc. In other words, you could move the parts on a better mbd as an intermediate step, though finding such a board could be difficult. Hmm, given the value often placed on such boards, it'd probably be easier to pick up a used 3930K and a board to go with it, that would be fairly low cost.
Or of course just splash for a 1700X. 8)
Ian.
Notmyusualid - Tuesday, March 7, 2017 - link
Welcome to the 21:9 fan club brother.But be careful of the 1920x1080 screens, my brother's 21:9 doesn't look half as good as my 3440x1440 screen.. It just needs that little bit more verticle resoultion.
My pals 4k screen is lovely, and brings his 4GB 980 GTX to its knees. Worse aspect ratio (in my opinion), and too many pixels (for now) to draw.
Careful of second-hand purchases too, many panels with backlight-bleed issues out there, and they are returns for that reason, again, in my opinion.
AnnonymousCoward - Monday, March 6, 2017 - link
Long story short:20% lower single-thread than Intel
70% higher multi-thread due to 8 cores
$330-$500
Mugur - Tuesday, March 7, 2017 - link
Actually, on average -6.8% IPC versus Kaby Lake (at the same frequency) - I believe this came directly from AMD. Add to this a lower grade 14nm process (GF again) that is biting AMD again and again (see last year RX480). Motherboard issues (memory, HPET), OS/application issues (SMT, lack of optimizations).All in all, I'm really impressed of what they achieved with such obstacles.
AnnonymousCoward - Tuesday, March 7, 2017 - link
Just looking at CineBench at a given TDP and price, AMD is 20% lower. That's the high level answer, regardless of IPC * clock frequency. I agree it's a huge win for AMD, and for users who need multicore performance.Cooe - Monday, March 1, 2021 - link
Maybe compare to Intel's Broadwell-E chips with actually similar core counts.... -_-