The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTSimultaneous MultiThreading (SMT)
Zen will be AMD’s first foray into a true simultaneous multithreading structure, and certain parts of the core will act differently depending on their implementation. There are many ways to manage threads, particularly to avoid stalls where one thread is blocking another that ends in the system hanging or crashing. The drivers that communicate with the OS also have to make sure they can distinguish between threads running on new cores or when a core is already occupied – to achieve maximum throughput then four threads should be across two cores, but for efficiency where speed isn’t a factor, perhaps power gating/clock gating half the cores in a CCX is a good idea.
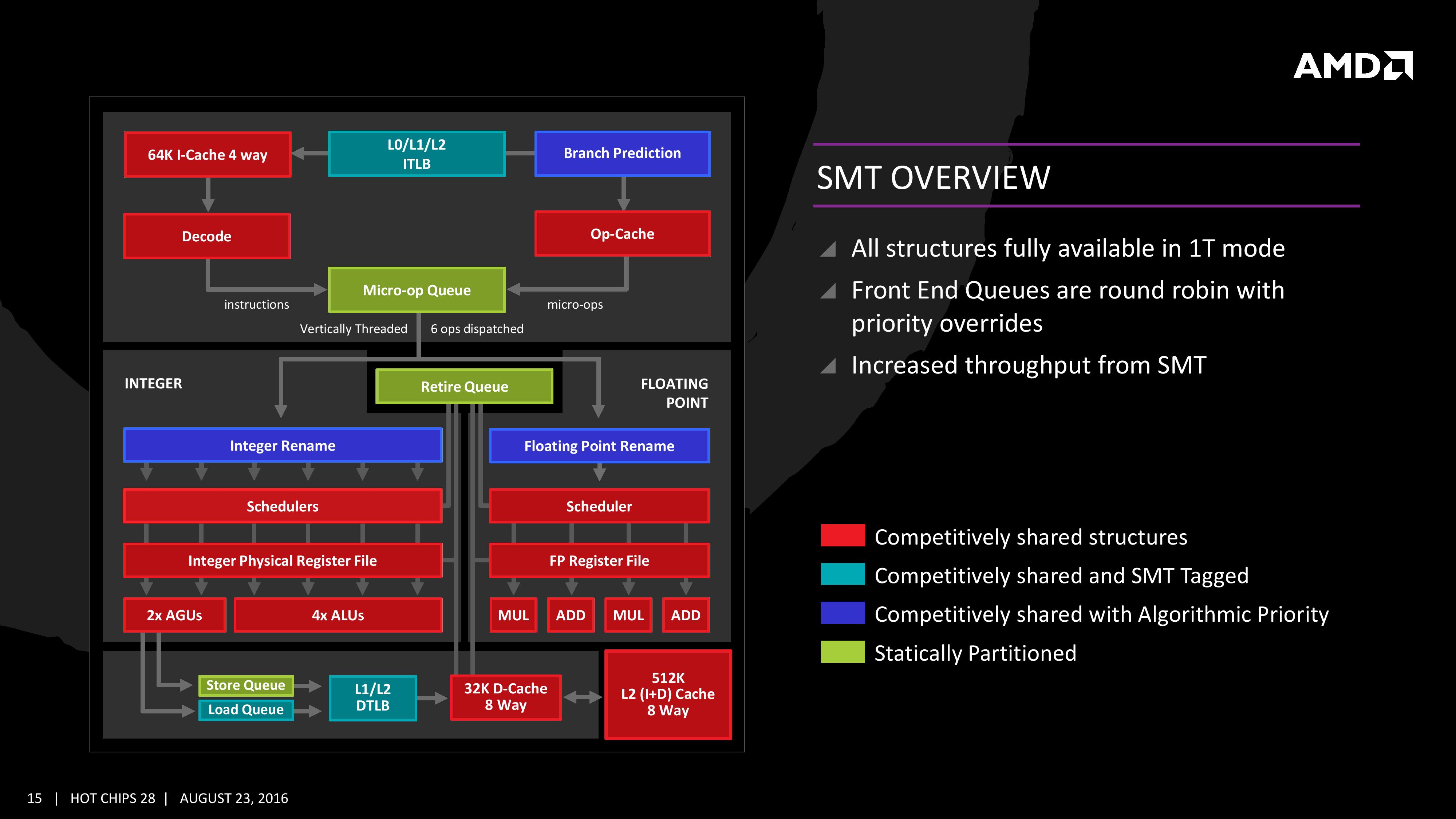
There are a number of ways that AMD will deal with thread management. The basic way is time slicing, and giving each thread an equal share of the pie. This is not always the best policy, especially when you have one performance dominant thread, or one thread that creates a lot of stalls, or a thread where latency is vital. In some methodologies the importance of a thread can be tagged or determined, and this is what we get here, though for some of the structures in the core it has to revert to a basic model.
With each thread, AMD performs internal analysis on the data stream for each to see which thread has algorithmic priority. This means that certain threads will require more resources, or that a branch miss needs to be prioritized to avoid long stall delays. The elements in blue (Branch Prediction, INT/FP Rename) operate on this methodology.
A thread can also be tagged with higher priority. This is important for latency sensitive operations, such as a touch-screen input or immediate user input elements required. The Translation Lookaside Buffers work in this way, to prioritize looking for recent virtual memory address translations. The Load Queue is similarly enabled this way, as typically low latency workloads require data as soon as possible, so the load queue is perfect for this.
Certain parts of the core are statically partitioned, giving each thread an equal timing. This is implemented mostly for anything that is typically processed in-order, such as anything coming out of the micro-op queue, the retire queue and the store queue. However, when running in SMT mode but only with a single thread, the statically partitioned parts of the core can end up as a bottleneck, as they are idle half the time.
The rest of the core is done via competitive scheduling, meaning that if a thread demands more resources it will try to get there first if there is space to do so each cycle.
New Instructions
AMD has a couple of tricks up its sleeve for Zen. Along with including the standard ISA, there are a few new custom instructions that are AMD only.

Some of the new commands are linked with ones that Intel already uses, such as RDSEED for random number generation, or SHA1/SHA256 for cryptography (even with the recent breakthrough in security). The two new instructions are CLZERO and PTE Coalescing.
The first, CLZERO, is aimed to clear a cache line and is more aimed at the data center and HPC crowds. This allows a thread to clear a poisoned cache line atomically (in one cycle) in preparation for zero data structures. It also allows a level of repeatability when the cache line is filled with expected data. CLZERO support will be determined by a CPUID bit.
PTE (Page Table Entry) Coalescing is the ability to combine small 4K page tables into 32K page tables, and is a software transparent implementation. This is useful for reducing the number of entries in the TLBs and the queues, but requires certain criteria of the data to be used within the branch predictor to be met.








574 Comments
View All Comments
mapesdhs - Sunday, March 5, 2017 - link
Yet another example of manipulation which wouldn't be tolerated in other areas of commercial product. I keep coming across examples in the tech world where products are deliberately crippled, prices get hiked, etc., but because it's tech stuff, nobody cares. Media never mentions it.Last week I asked a seller site about why a particular 32GB 3200MHz DDR4 kit they had listed (awaiting an ETA) was so much cheaper than the official kits for Ryzen (same brand of RAM please note). Overnight, the seller site changed the ETA to next week but also increased the price by a whopping 80%, making it completely irrelevant. I've seen this happen three times with different products in the last 2 weeks.
Ian.
HomeworldFound - Sunday, March 5, 2017 - link
If they were pretty cheap then use your logic, placeholder prices happen. If they had no ETA the chances is that they had no prices. I don't see a shortage of decent DDR4 so it definitely isn't a supply and demand problem. Perhaps you need to talk to the manufacturer to get their guideline prices.HomeworldFound - Sunday, March 5, 2017 - link
Not really. If developers wanted to enhance AMD platforms, or it was actually worth it they'd have done it by now. It's now just an excuse to explain either underperformance or an inability to work with the industry.Notmyusualid - Tuesday, March 7, 2017 - link
@ sedraIt certainly should not be forgotten, that is for sure.
Rene23 - Monday, March 6, 2017 - link
yet people here mentioned multiple times "settled in 2009"; pretending it is not happening anymore, sick :-/GeoffreyA - Monday, March 6, 2017 - link
I kind of vaguely knew that benchmarks were often unfairly optimised for Intel CPUs; but I never knew this detailed information before, and from such a reputable source: Agner Fog. I know that he's an authority on CPU microarchitectures and things like that. Intel is evil. Even now with Ryzen, it seems the whole software ecosystem is somewhat suboptimal on it, because of software being tuned over the last decade for the Core microarchitecture. Yet, despite all that, Ryzen is still smashing Intel in many of the benchmarks.Outlander_04 - Monday, March 6, 2017 - link
Settled in 2009 .Not relevant to optimisation for Ryzen in any way
Rene23 - Monday, March 6, 2017 - link
settled in 2009 does not mean their current compiler and libraries are not doing it anymore, e.g. it could simply not run the best SSE/AVX code path disguised as simply not matching new AMD cpus properly.cocochanel - Saturday, March 4, 2017 - link
One thing that is not being mentioned by many is the increase in savings when you buy a CPU + mobo. Intel knows how to milk the consumer. On their 6-8 core flagships, a mobo with a top chipset will set you back 300-400 $ or even more. That's a lot for a mobo. Add the overpriced CPU. I expect AMD mobos to offer better value. Historically, they always did.On top of that, a VEGA GPU will probably be a better match for Ryzen than an Nvidia card, but I say probably and not certainly.
If I were to replace my aging gaming rig for Christmas, this would be my first choice.
mapesdhs - Sunday, March 5, 2017 - link
Bang goes the saving when one asks about a RAM kit awaiting an ETA and the seller hikes the price by 80% overnight (see my comment above).