The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTThe Core Complex, Caches, and Fabric
Many core designs often start with an initial low-core-count building block that is repeated across a coherent fabric to generate a large number of cores and the large die. In this case, AMD is using a CPU Complex (CCX) as that building block which consists of four cores and the associated caches.
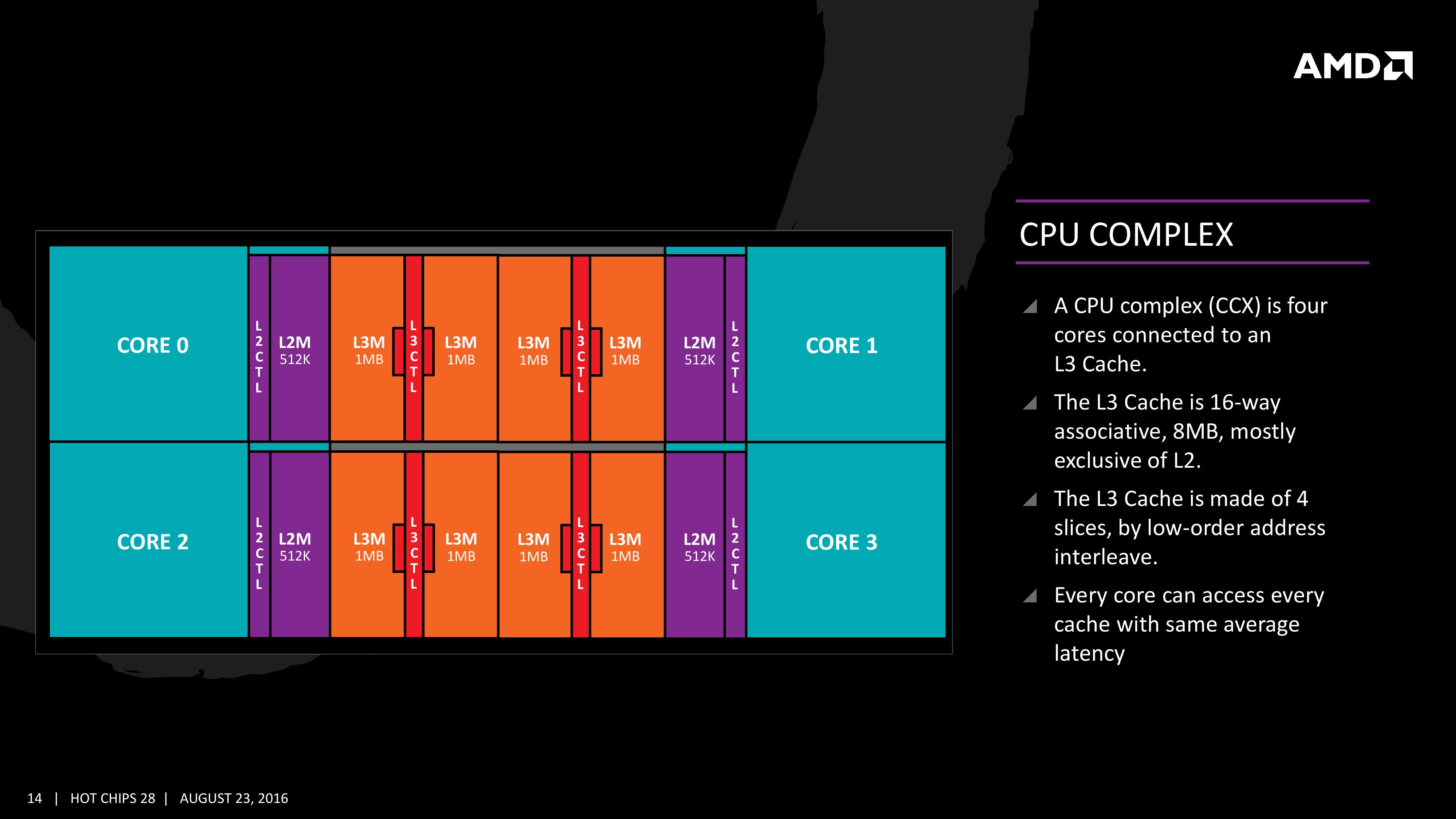
Each core will have direct access to its private L2 cache, and the 8 MB of L3 cache is, despite being split into blocks per core, accessible by every core on the CCX with ‘an average latency’ also L3 hits nearer to the core will have a lower latency due to the low-order address interleave method of address generation.
The L3 cache is actually a victim cache, taking data from L1 and L2 evictions rather than collecting data from prefetch/demand instructions. Victim caches tend to be less effective than inclusive caches, however Zen counters this by having a sufficiency large L2 to compensate. The use of a victim cache means that it does not have to hold L2 data inside, effectively increasing its potential capacity with less data redundancy.
It is worth noting that a single CCX has 8 MB of cache, and as a result the 8-core Zen being displayed by AMD at the current events involves two CPU Complexes. This affords a total of 16 MB of L3 cache, albeit in two distinct parts. This means that the true LLC for the entire chip is actually DRAM, although AMD states that the two CCXes can communicate with each other through the custom fabric which connects both the complexes, the memory controller, the IO, the PCIe lanes etc.
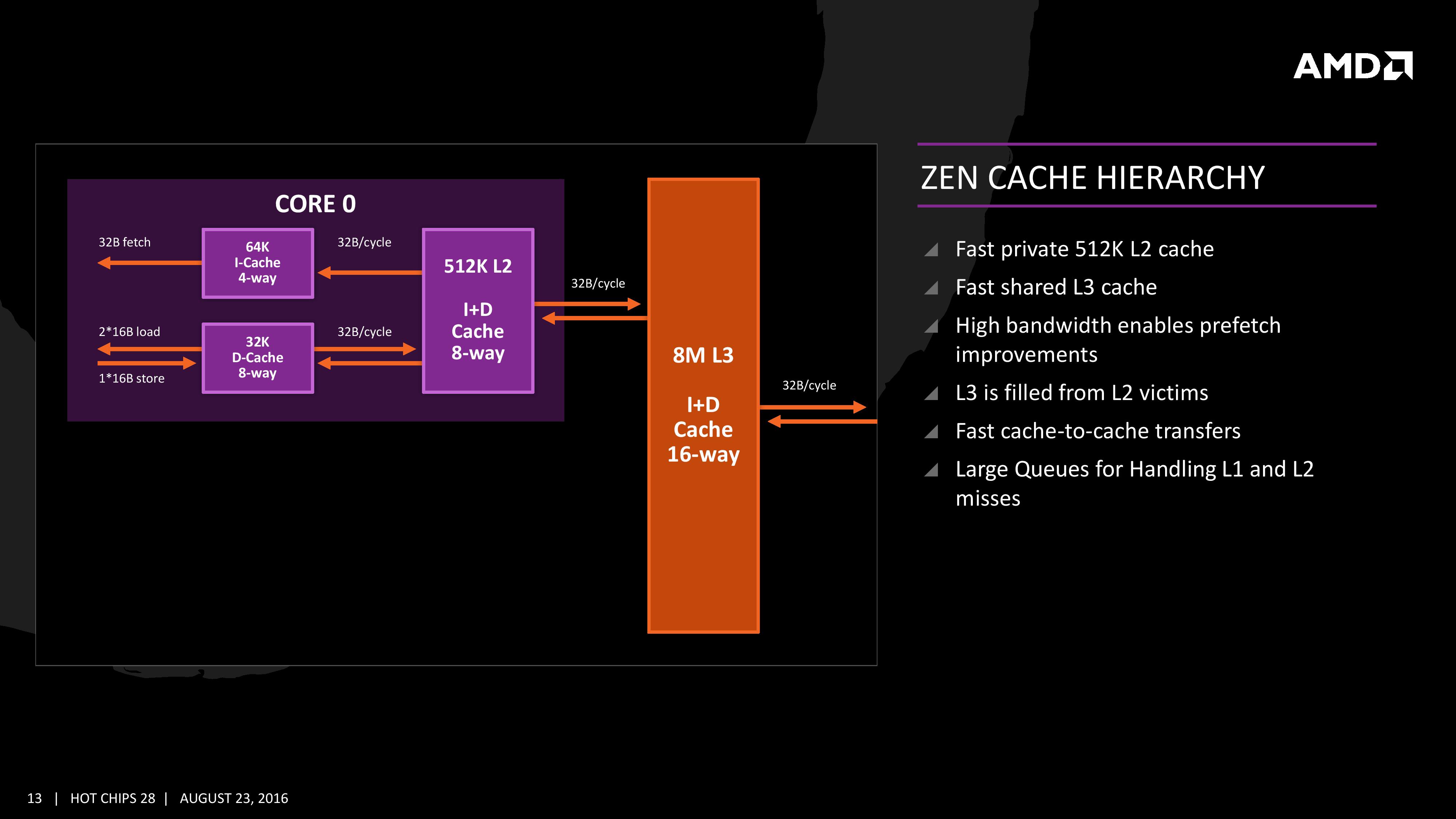
The cache representation shows L1 and L2 being local to each the core, followed by 8MB of L3 split over several cores. AMD states that the L1 and L2 bandwidth is nearly double that of Excavator, with L3 now up to 5x for bandwidth, and that this bandwidth will help drive the improvements made on the prefetch side. AMD also states that there are large queues in play for L1/L2 cache misses.

One interesting story is going to be how AMD’s coherent fabric works. For those that follow mobile phone SoCs, we know fabrics and interconnects such as CCI-400 or the CCN family are optimized to take advantage of core clusters along with the rest of the chip. A number of people have speculated that the fabric used in AMD’s new design is based on HyperTransport, however AMD has confirmed that they are using a superset HyperTransport here for Zen, and that the Infinity fabric design is meant to be high bandwidth, low latency, and be in both Zen and Vega as well as future products. Almost similar to the CPU/GPU roadmaps, the Fabric has its own as well.
Ultimately the new fabric involves a series of control and data passing structures, with the data passing enabling third-party IP in custom designs, a high-performance common bus for large multi-unit (CPU/GPU) structures, and socket to socket communication. The control elements are an extension of power management, enabling parts of the fabric to duty cycle when not in use, security by way of memory management and detection, and test/initialization for activities such as data prefetch.








574 Comments
View All Comments
mikeZZZ - Friday, March 3, 2017 - link
Anadtech, can we please run closer to real life scenarios such as a gaming benchmark with a file compression benchmark running at the same time. Even gaming enthusiasts run more than one program at a time. For example, file decompression in the background while playing a game, or baseball game streaming in a small window while playing a game. You already have many individual benchmarks, so why not go the extra but significant benchmark of running two? We know this favors the higher core CPUs (maybe even Ryzen 7 1700 over all other lower core ones CPUs) but that is closer to real life and should be very meaningful to someone wanting to make an informed purchase.ValiumMm - Saturday, March 4, 2017 - link
Would also like to see thisUrQuan3 - Friday, March 3, 2017 - link
Just want to put out a quick comment about benchmarking with Handbrake. In dealing with Broadwell-E, and especially ThunderX, I've found that Handbrake often doesn't scale well past about 10 cores, and really doesn't scale well past 16 or so. What seems to happen is that the single-threaded parts of Handbrake tend to dominate the encode time. In extreme cases, ultra-fast and placebo will take almost the same amount of time as x264 is consuming input faster than the rest of Handbrake can generate it. On ThunderX, I've found I can complete four 1080p placebo encodes in the same amount of time that I can complete one. I would expect a similar result on a 48 core Intel, though I do not have access to one beyond 24 cores. Turbo boost would hide this effect a bit.I am not knocking using Handbrake for benchmarking. The Handbrake and ray-trace results are the two that I care about most. I just thought I'd give a heads up about this limitation. You can check CPU usage statistics to get an indication of when you are running up against this limit.
Oh, and I am very excited to see multiple ray-tracers in your runs. Please continue.
Meteor2 - Saturday, March 4, 2017 - link
Presumably though you can have several x264 jobs running simultaneously on that hardware? So while your time to encode a certain piece doesn't decrease, you have more total-throughput (e.g. encoding several different bitrates for adaptive streaming). Should give good efficiency too on a larger Broadwell-E or a ThunderX.UrQuan3 - Tuesday, March 7, 2017 - link
Exactly. It's the first time I've thought about installing a queue manager for a single computer.jade5419 - Saturday, March 4, 2017 - link
I agree with this. In my experience Handbrake has a core / thread limit.I have a Z600 system with dual Xeon 5570 @ 2.93GHz, 6 core / 12 threads (total 24 threads), 48GB of RAM and a Z620 system with dual Xeon E5-2690 @ 2.9GHz 8 core / 16 threads (total 32 threads), 64GB RAM.
The two systems transcode video at the same speed using Handbrake 1.0.3. Monitoring CPU usage shows all threads of the Z600 at 100% utilization whereas the CPU utilization on the Z620 is approximately 80%.
Notmyusualid - Sunday, March 5, 2017 - link
Ever tried running GTA5 on 28 cores?It doesn't work. You have to adjust the game 'launchers' core affinity to < 26 cores or it won't even load.
Given this discovery, I expect there are many more applications out there, that may crap-out as we see more and more cores come into the mainstream.
Just a thought.
mapesdhs - Sunday, March 5, 2017 - link
I'd love to know why this happens. I'm guessing something dumb within Windows.Outlander_04 - Friday, March 3, 2017 - link
There is more than enough good news to make me want to buy a 6 core Ryzen when they become available .Likely that will be the sweet spot for gamers
0ldman79 - Saturday, March 4, 2017 - link
I'm looking forward to seeing Ryzen updated in the bench.There aren't any apps or benchmarks that cross over between the FX series and the Ryzen series, so we can't do any side by side comparison.
Great review guys. Looking forward to the six core Ryzen. I think just like the FX series the six core will be the sweet spot.