The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTExecution, Load/Store, INT and FP Scheduling
The execution of micro-ops get filters into the Integer (INT) and Floating Point (FP) parts of the core, which each have different pipes and execution ports. First up is the Integer pipe which affords a 168-entry register file which forwards into four arithmetic logic units and two address generation units. This allows the core to schedule six micro-ops/cycle, and each execution port has its own 14-entry schedule queue.
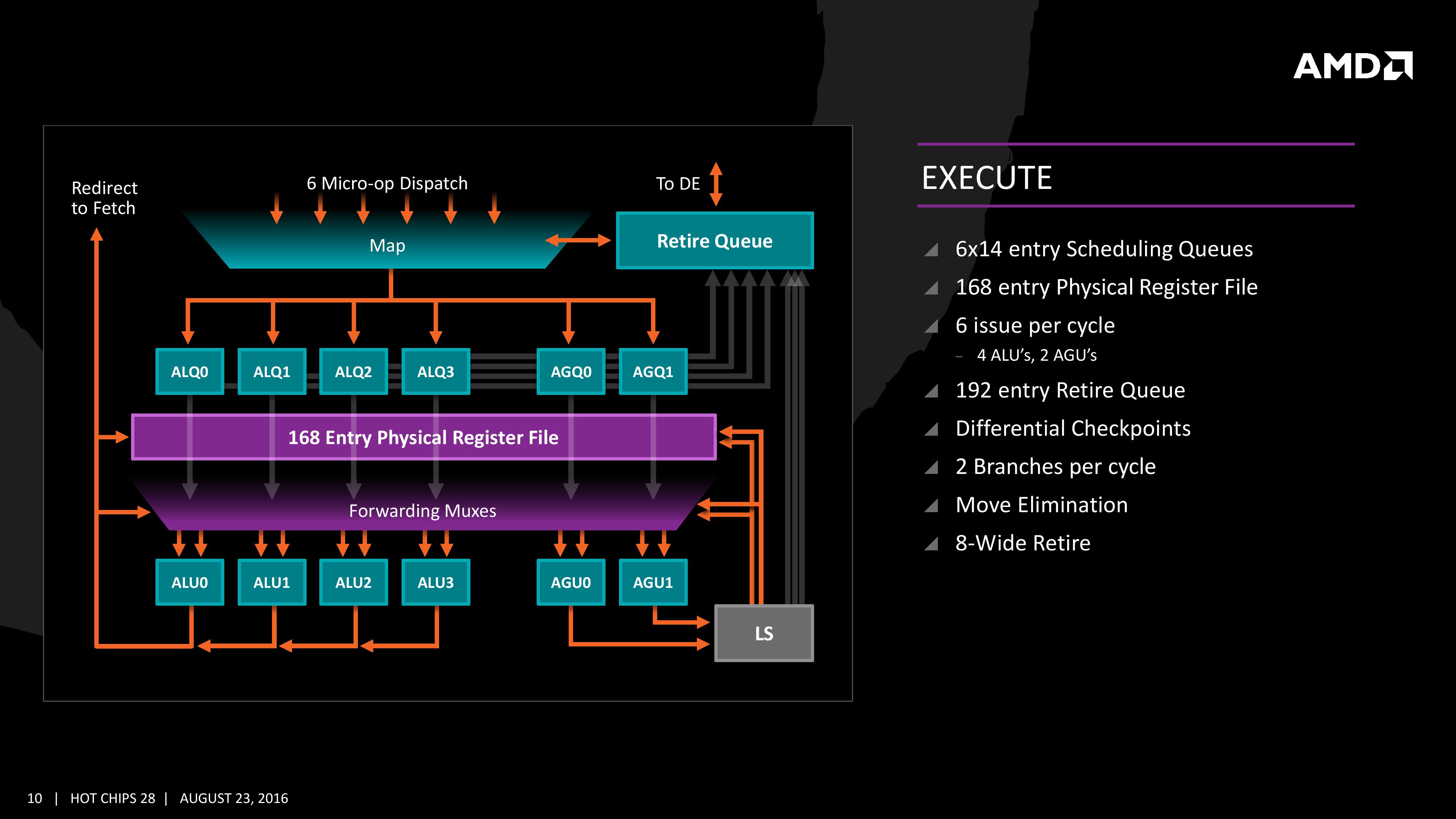
The INT unit can work on two branches per cycle, but it should be noted that not all the ALUs are equal. Only two ALUs are capable of branches, one of the ALUs can perform IMUL operations (signed multiply), and only one can do CRC operations. There are other limitations as well, but broadly we are told that the ALUs are symmetric except for a few focused operations. Exactly what operations will be disclosed closer to the launch date.
The INT pipe will keep track of branching instructions with differential checkpoints, to cut down on storing redundant data between branches (saves queue entries and power), but can also perform Move Elimination. This is where a simple mov command between two registers occurs – instead of inflicting a high energy loop around the core to physically move the single instruction, the core adjusts the pointers to the registers instead and essentially applies a new mapping table, which is a lower power operation.
Both INT and FP units have direct access to the retire queue, which is 192-entry and can retire 8 instructions per cycle. In some previous x86 CPU designs, the retire unit was a limiting factor for extracting peak performance, and so having it retire quicker than dispatch should keep the queue relatively empty and not near the limit.
The Load/Store Units are accessible from both AGUs simultaneously, and will support 72 out-of-order loads. Overall, as mentioned before, the core can perform two 16B loads (2x128-bit) and one 16B store per cycle, with the latter relying on a 44-entry Store queue. The TLB buffer for the L2 cache for already decoded addresses is two level here, with the L1 TLB supporting 64-entry at all page sizes and the L2 TLB going for 1.5K-entry with no 1G pages. The TLB and data pipes are split in this design, which relies on tags to determine if the data is in the cache or to start the data prefetch earlier in the pipeline.
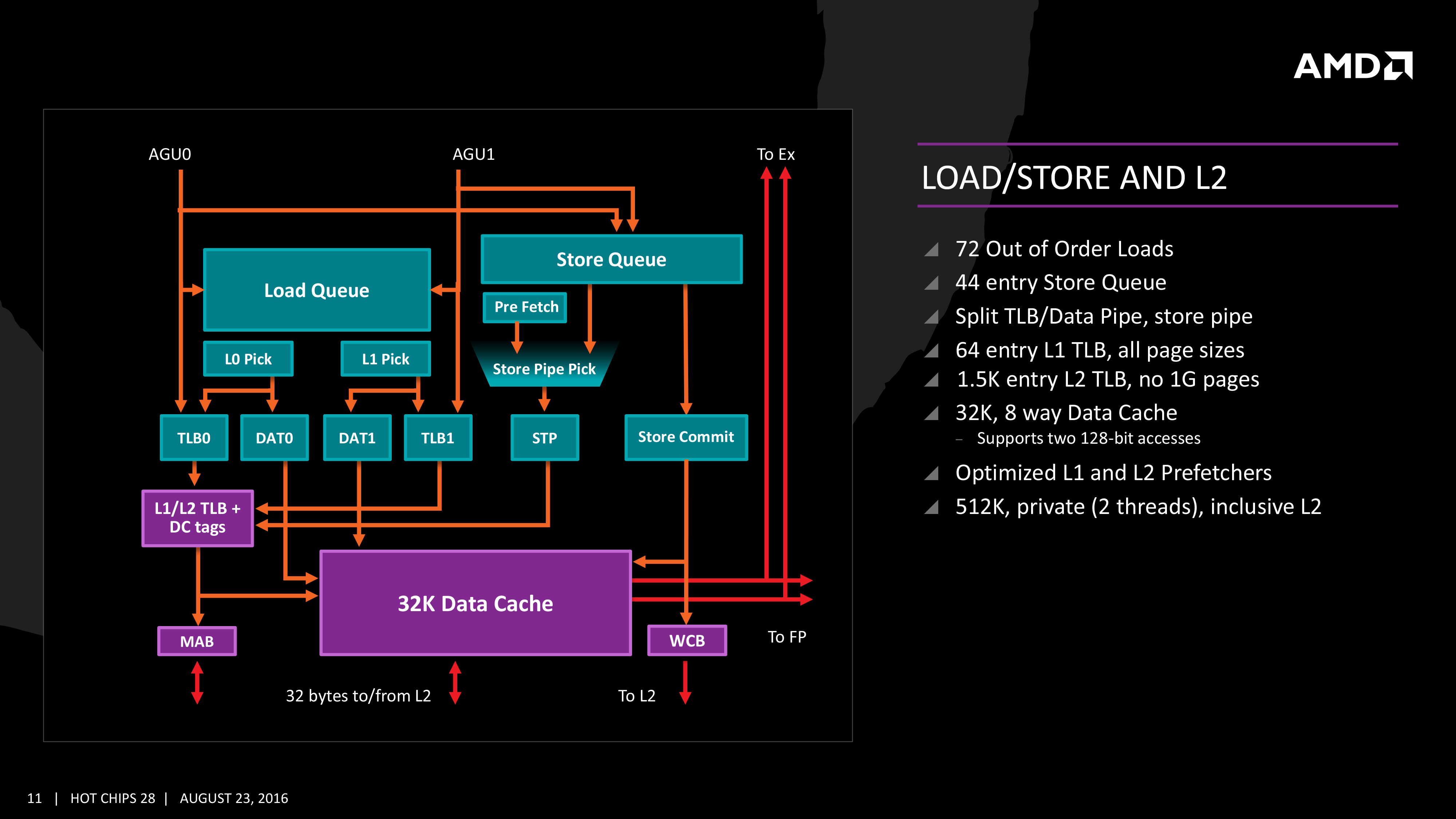
The data cache here also has direct access to the main L2 cache at 32 Bytes/cycle, with the 512 KB 8-way L2 cache being private to the core and inclusive. When data resides back in L1 it can be processed back to either the INT or the FP pipes as required.
Moving onto the floating point part of the core, and the first thing to notice is that there are two scheduling queues here. These are listed as ‘schedulable’ and ‘non-schedulable’ queues with lower power operation when certain micro-ops are in play, but also allows the backup queue to sort out parts of the dispatch in advance via the LDCVT. The register file is 160 entry, with direct FP to INT transfers as required, as well as supporting accelerated recovery on flushes (when data is written to a cache further back in the hierarchy to make room).
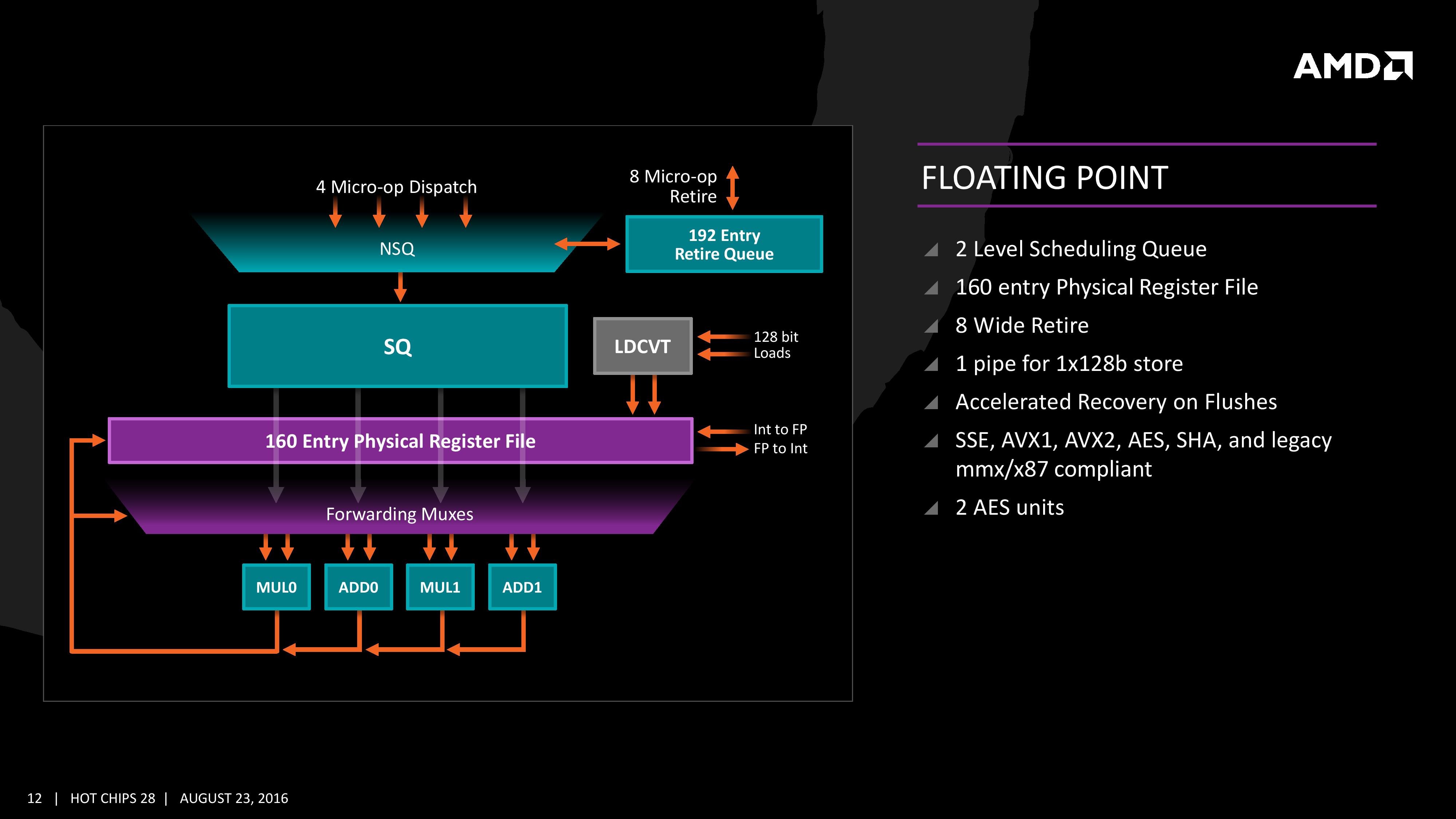
The FP Unit uses four pipes rather than three on Excavator, and we are told that the latency in Zen is reduced as well for operations (though more information on this will come at a later date). We have two MUL and two ADD in the FP unit, capable of joining to form two 128-bit FMACs, but not one 256-bit AVX. In order to do AVX, the unit will split the operations accordingly. On the counter side each core will have 2 AES units for cryptography as well as decode support for SSE, AVX1/2, SHA and legacy mmx/x87 compliant code.








574 Comments
View All Comments
mapesdhs - Thursday, March 2, 2017 - link
It would be bizarre if they weren't clocked a lot higher, since there'll be a greater thermal limit per core, which is why the 4820K is such a fun CPU (high-TDP socket, 40 PCIe lanes, but only 4 cores so oc'ing isn't really limited by thermals compared to 6-core SB-E/IB-E) that can beat the 5820K in some cases (multi-GPU/compute).Meteor2 - Friday, March 3, 2017 - link
...Silverblue, look at the PDF opening test. What comes top? It's not an AMD chip.Cooe - Sunday, February 28, 2021 - link
Lol, because opening PDF's is where people need/will notice more performance? -_-CPU's have been able to open up PDF's fast enough to be irrelevant since around the turn of the century...
rarson - Thursday, March 2, 2017 - link
"AMD really isn't offering anything much for the mid range or regular desktop user either."So I'd HIGHLY recommend you wait 3 months, or overpay for Intel stuff. Because the lower-core Zen chips will no doubt provide the same performance-per-dollar that the high-end Ryzen chips are offering right now.
rarson - Thursday, March 2, 2017 - link
"their $499 CPU is often beaten by an i3."It's clear that you're looking at raw benchmark numbers and not real-world performance for what the chip is designed. If all you need is i3 performance, then why the hell are you looking at an 8-core processor that runs $329 or more?
Ratman6161 - Friday, March 3, 2017 - link
Its all academic to me. As I posted elsewhere, my i7-2600K is still offering me all the performance I need. So I'm just reading this out of curiosity. I also really, really want to like AMD CPU's because I still have a lot of nostalgia for the good old days of the Athlon 64 - when AMD was actually beating Intel in both performance and price. And sometimes I like to tinker around with the latest toys even if I don't particularly need it. I have a home lab with two VMWare ESXi systems built on FX-8320's because at the time they were the cheapest way to get to 8 threads - running a lot of VM's but with each VM doing light work.I also run an IT department so I'm always keeping tabs on what might be coming down the pike when I get ready to update desktops. But there is a sharp divide between what I buy for myself at home and what I buy for users at work. At work, most of our users actually would do fine with an i3. But I'm also keeping an eye out for what AMD has on offer in this range.
Notmyusualid - Tuesday, March 7, 2017 - link
@ Jimster480Sorry pal, but that is false, or inaccurate information.
ALL BUT the lowest model of CPUs in the 2011v3 platform are 40 PCIE lanes. Again, only the entry-level chip (6800K),has 28 lanes:
http://www.anandtech.com/show/10337/the-intel-broa...
But I do agree with you, that this is competing against the HEDT line.
Peace.
slickr - Thursday, March 2, 2017 - link
I'm sorry, but that sound just like Intel PR. I don't usually call people shills, but your reply seems to be straight out of Intel's PR book! First of all more and more games are taking advantage of more cores, you can easily see this especially with DX12 titles where if you have even 16 cores it will take advantage of.So having 8 cores for $330 to $500 is incredible value! We also see that the Ryzen chips are all competitive compared to the $1100 6900k which is where the comparison should be. Performance on 8 cores.
And as I've found out real world performance on 8 cores compared to 4 cores is like night and day. Have you tried running a demanding game, streaming in through OBS to Twitch, with the browser open to read Twitch chat and check other stuff in the process, while also having musicbee open and playing your songs and a separate program to read Twitch donations and text, etc...
This is where 4 core struggles a lot, while 8 core responsiveness is perfect. I can't use my PC if I decide to reduce a video size to a smaller one with a 4 core. Even 8 cores are fully taken advantage off, but through one core you can always do other stuff like watch movie or surf the internet without it struggling to process.
But even if games are your holy grail and what you base your opinion on, then Ryzen does really well. Its equal or slightly slower than the much much more optimized Intel processors. But you have to keep in mind a lot of the game code is optimized solely for Intel. That is what most gamers use, in fact over 80% is Intel based gamers, but developers will optimize for AMD now that they have a competitor on their hands.
We see this all the time, with game developers optimizing for RX 400 series a lot, even though Nvidia has the large majority of share in the market. So I expect to see anywhere from 10% to 25% more performance in games and programs that are also optimized for AMD hardware.
lmcd - Thursday, March 2, 2017 - link
How can you call someone a shill and post this without any self-awareness? Your real-world task is GPU-constrained anyway, since you should be using a GPU capable of both video encode and rendering simultaneously. If not, you can consider excellent features like Intel's Quick Sync, which works even with a primary GPU in use these days.Meteor2 - Friday, March 3, 2017 - link
Game code is optimised for x86.