The AMD Radeon RX 480 Preview: Polaris Makes Its Mainstream Mark
by Ryan Smith on June 29, 2016 9:00 AM ESTThe Polaris Architecture: In Brief
For today’s preview I’m going to quickly hit the highlights of the Polaris architecture.
In their announcement of the architecture this year, AMD laid out a basic overview of what components of the GPU would see major updates with Polaris. Polaris is not a complete overhaul of past AMD designs, but AMD has combined targeted performance upgrades with a chip-wide energy efficiency upgrade. As a result Polaris is a mix of old and new, and a lot more efficient in the process.
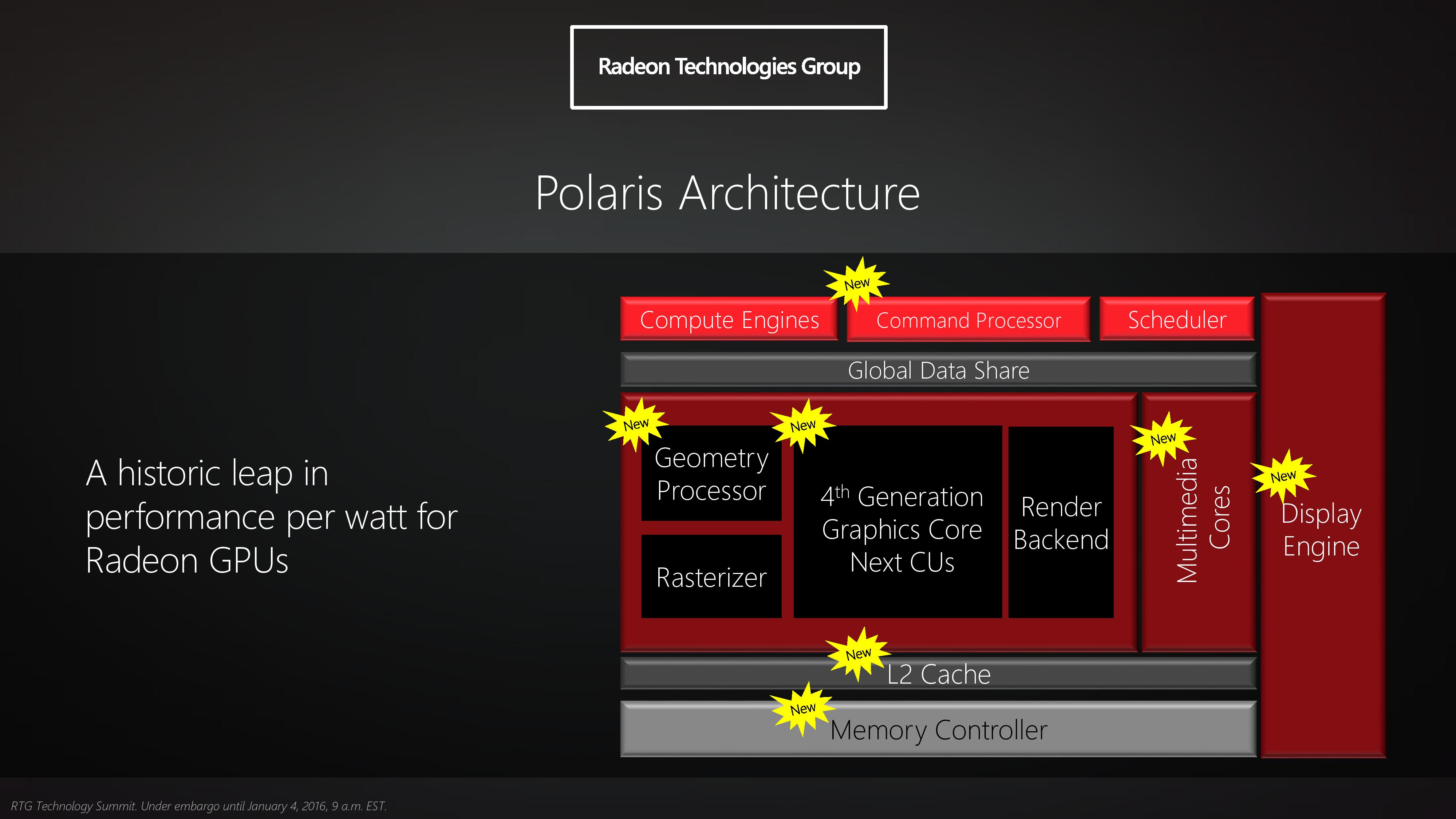
At its heart, Polaris is based on AMD’s 4th generation Graphics Core Next architecture (GCN 4). GCN 4 is not significantly different than GCN 1.2 (Tonga/Fiji), and in fact GCN 4’s ISA is identical to that of GCN 1.2’s. So everything we see here today comes not from broad, architectural changes, but from low-level microarchitectural changes that improve how instructions execute under the hood.

Overall AMD is claiming that GCN 4 (via RX 480) offers a 15% improvement in shader efficiency over GCN 1.1 (R9 290). This comes from two changes; instruction prefetching and a larger instruction buffer. In the case of the former, GCN 4 can, with the driver’s assistance, attempt to pre-fetch future instructions, something GCN 1.x could not do. When done correctly, this reduces/eliminates the need for a wave to stall to wait on an instruction fetch, keeping the CU fed and active more often. Meanwhile the per-wave instruction buffer (which is separate from the register file) has been increased from 12 DWORDs to 16 DWORDs, allowing more instructions to be buffered and, according to AMD, improving single-threaded performance.
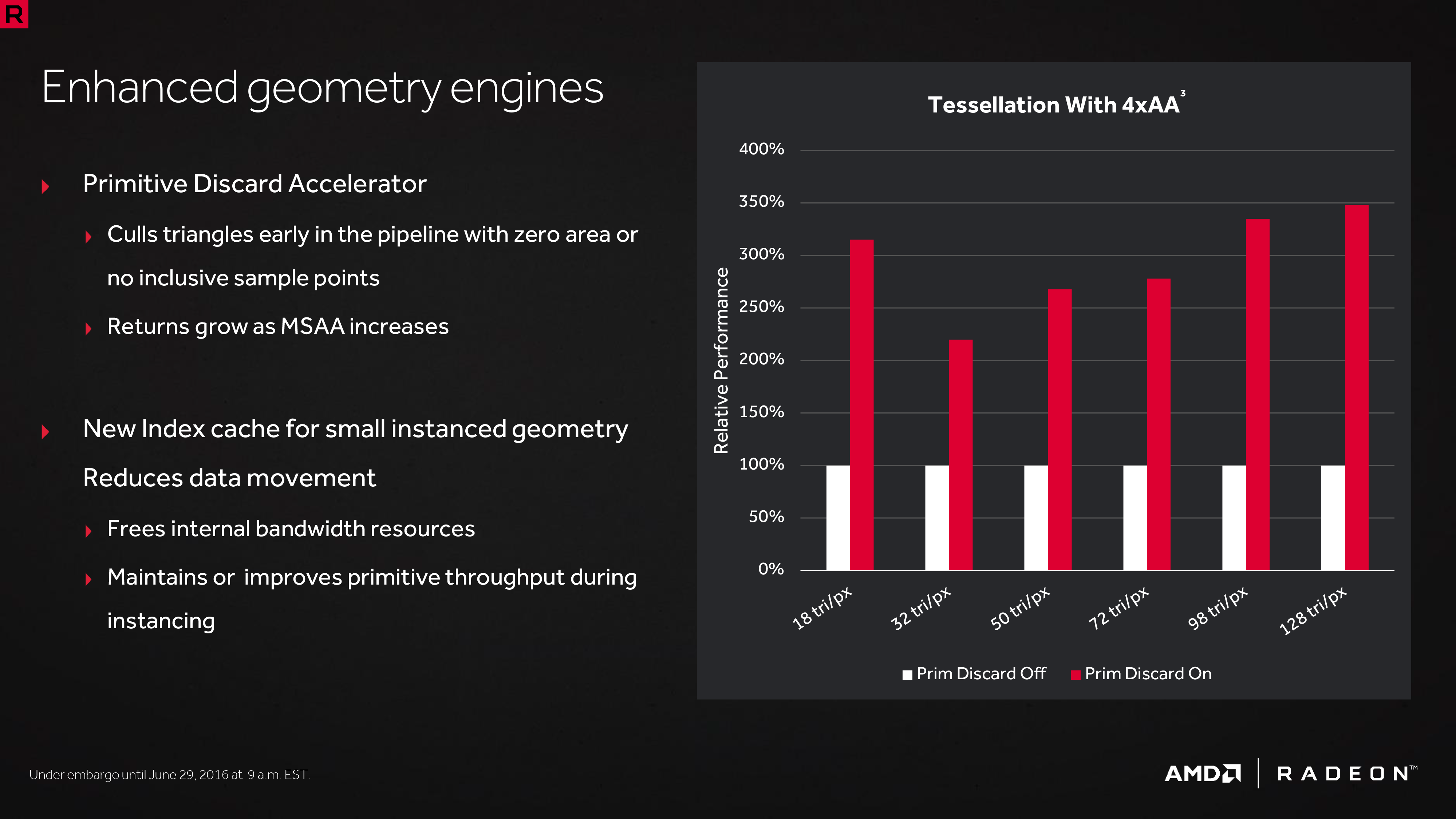
Outside of the shader cores themselves, AMD has also made enhancements to the graphics front-end for Polaris. AMD’s latest architecture integrates what AMD calls a Primative Discard Accelerator. True to its name, the job of the discard accelerator is to remove (cull) triangles that are too small to be used, and to do so early enough in the rendering pipeline that the rest of the GPU is spared from having to deal with these unnecessary triangles. Degenerate triangles are culled before they even hit the vertex shader, while small triangles culled a bit later, after the vertex shader but before they hit the rasterizer. There’s no visual quality impact to this (only triangles that can’t be seen/rendered are culled), and as claimed by AMD, the benefits of the discard accelerator increase with MSAA levels, as MSAA otherwise exacerbates the small triangle problem.
Along these lines, Polaris also implements a new index cache, again meant to improve geometry performance. The index cache is designed specifically to accelerate geometry instancing performance, allowing small instanced geometry to stay close by in the cache, avoiding the power and bandwidth costs of shuffling this data around to other caches and VRAM.
Finally, at the back-end of the GPU, the ROP/L2/Memory controller partitions have also received their own updates. Chief among these is that Polaris implements the next generation of AMD’s delta color compression technology, which uses pattern matching to reduce the size and resulting memory bandwidth needs of frame buffers and render targets. As a result of this compression, color compression results in a de facto increase in available memory bandwidth and decrease in power consumption, at least so long as buffer is compressible. With Polaris, AMD supports a larger pattern library to better compress more buffers more often, improving on GCN 1.2 color compression by around 17%.
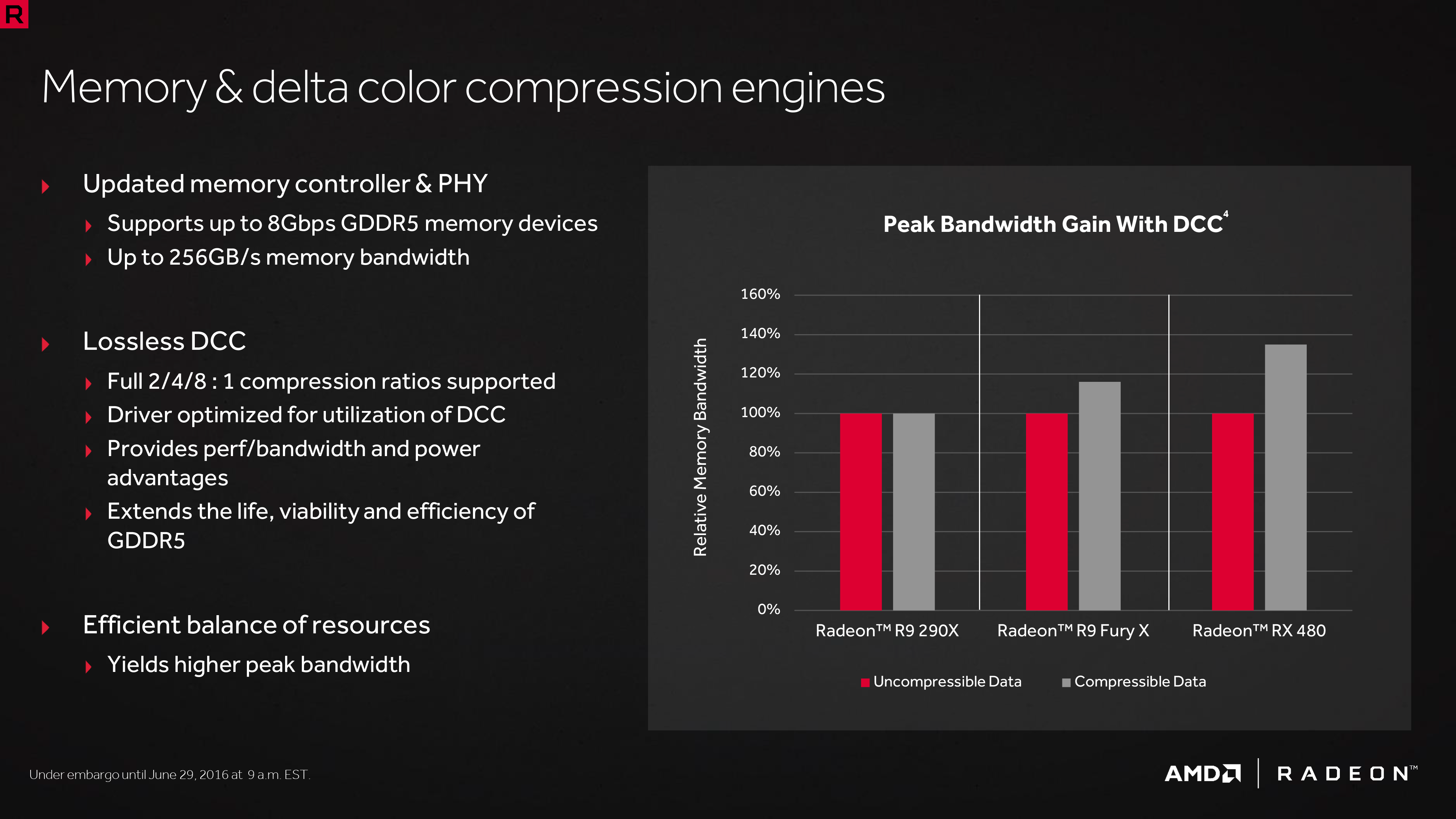
Otherwise we’ve already covered the increased L2 cache size, which is now at 2MB. Paired with this is AMD’s latest generation memory controller, which can now officially go to 8Gbps, and even a bit more than that when oveclocking.








449 Comments
View All Comments
Drumsticks - Wednesday, June 29, 2016 - link
I have heard this is true, but what does Anandtech (and many others) measure by? Most reviews show the 480 and the 970 very close in power draw.Polaris definitely appears to be a little bit more efficient than Maxwell, but likely less a good bit less efficient than Pascal. It's definitely better than the 3XX vs Maxwell days though.
looncraz - Wednesday, June 29, 2016 - link
Compared to the 970, the RX 480 has better power consumption for the performance, yes. Not by much, but that value should increase with AIB versions as the reference runs rather warm and has a less than efficient VRM.Only time will tell how that consumption changes with clock speeds and how much overclocking can be genuinely achieved from the chip, but at this point, stock vs stock, the RX480 is a better buy than the 970.
The 1060 is another matter altogether. It will certainly use less power and clock better than the RX 480, so we can assume that it will perform better as well - with nVidia simply tweaking its default clocks to best the RX 480. Still, it looks like the 1060 will have only 3GB or 6GB of RAM, so the cheaper RX 480 will fair better in RAM-heavy scenarios than the cheaper 1060.
just4U - Wednesday, June 29, 2016 - link
There is no guarantees on the 1060.. especially if it's 128bit. The 960 was a little on the disappointing side. Especially considering what you had to pay for it. (I know.. I own a 960 4G and a 380..)fanofanand - Thursday, June 30, 2016 - link
I wouldn't know how disappointing the 960 was, seeing as Anandtech never thought it worthy of review. *zing*gnawrot - Wednesday, June 29, 2016 - link
I am pretty sure that AMD can deliver Vega in 2017 if they want to. In the mean time they will release their server CPUs (more profitable market). They cannot launch that many products at the same time.Michael Bay - Wednesday, June 29, 2016 - link
Their server CPUs which nobody even wants. This particular battle was lost a decade ago.Domaldel - Thursday, June 30, 2016 - link
Not really if what we've heard about Zen is correct.32 cores and 64 threads with each core roughly matching Broadwell clock for clock at a lower price point?
While all of that could of course be bull there's also potential here for some serious disruption in the CPU market.
And Zen is probably higher priority for AMD then the GPU market as a whole.
Gigaplex - Thursday, June 30, 2016 - link
I doubt they'll match Broadwell clock for clock. They'll probably fall in the Nehalem to Sandy Bridge range. That should be enough though to cause some disruption in the CPU market if the price is right.mikato - Friday, July 29, 2016 - link
So are you saying, Michael Bay, that if they released a CPU that was competitive or better price-performance-efficiency and Intel's then it wouldn't be successful? It sounds like that is what you are saying.r@ven - Wednesday, June 29, 2016 - link
What are you stupid? The R9 390 was already made in the time to compete the 970. And even faster in 1440P.