AMD Carrizo Part 2: A Generational Deep Dive into the Athlon X4 845 at $70
by Ian Cutress on July 14, 2016 9:00 AM ESTLegacy Benchmarks at 3 GHz
Some of our legacy benchmarks have followed AnandTech for over a decade, showing how performance changes when the code bases stay the same in that period. Some of this software is still in common use today.
All of our benchmark results can also be found in our benchmark engine, Bench.
3D Particle Movement v1
3DPM is a self-penned benchmark, taking basic 3D movement algorithms used in Brownian Motion simulations and testing them for speed. High floating point performance, MHz and IPC wins in the single thread version, whereas the multithread version has to handle the threads and loves more cores. This is the original version, written in the style of a typical non-computer science student coding up an algorithm for their theoretical problem, and comes without any non-obvious optimizations not already performed by the compiler, such as false sharing.
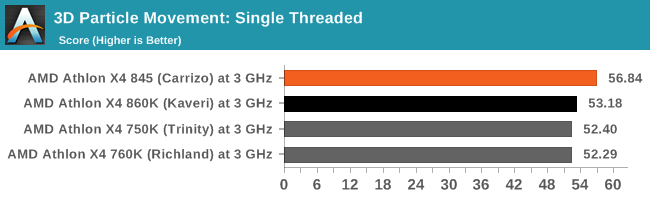
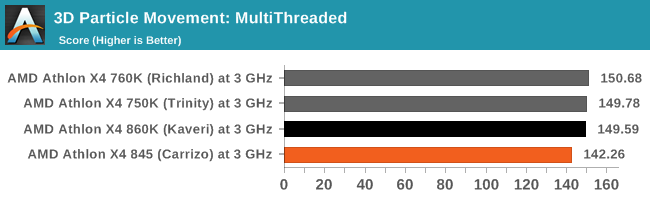
We ran 3DPM v2 earlier in the review, and it showed significant gains for Carrizo when running software that is not competing for data in shared cache lines. This older version of that benchmark still has those 'base CS' flaws that a non-CompSci science student might make, and while Carrizo has a small gain in single threaded mode, moving to multithreaded puts some strain on the caches, resulting in lower performance.
Cinebench 11.5 and 10
Cinebench is a widely known benchmarking tool for measuring performance relative to MAXON's animation software Cinema 4D. Cinebench has been optimized over a decade and focuses on purely CPU horsepower, meaning if there is a discrepancy in pure throughput characteristics, Cinebench is likely to show that discrepancy. Arguably other software doesn't make use of all the tools available, so the real world relevance might purely be academic, but given our large database of data for Cinebench it seems difficult to ignore a small five minute test. We run the modern version 15 in this test, as well as the older 11.5 and 10 due to our back data.
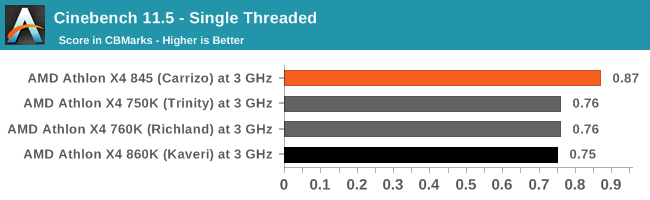
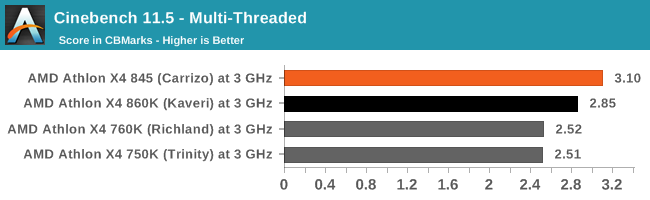
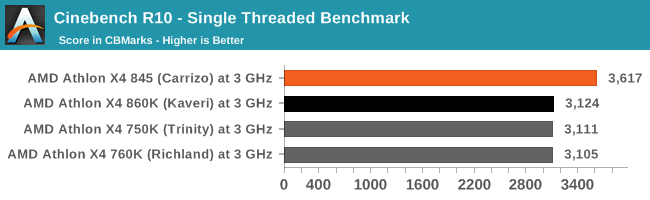
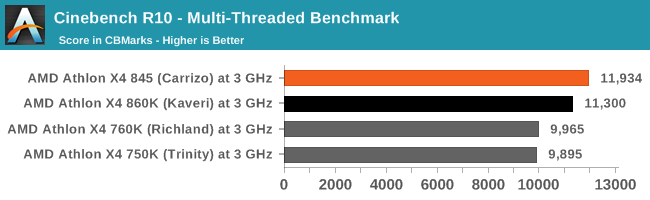
On the older versions of CineBench, like the newer ones, Carrizo has some notable microarchitectural advantages over Kaveri and previous versions of the Bulldozer microarchitecture.
POV-Ray 3.7
POV-Ray is a common ray-tracing tool used to generate realistic looking scenes. We've used POV-Ray in its various guises over the years as a good benchmark for performance, as well as a tool on the march to ray-tracing limited immersive environments. We use the built-in multithreaded benchmark.
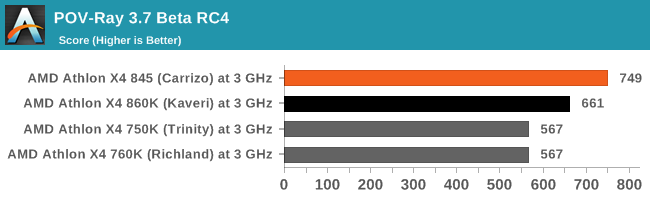
For our base ray tracing benchmark in Windows, again Carrizo pulls out a lead. This time it's around 13% over Kaveri or 32% over Trinity/Richland.
TrueCrypt 7.1
Before its discontinuation, TrueCrypt was a popular tool for WindowsXP to offer software encryption to a file system. The version we use for our tests, 7.1, is still widely used however the developers have stopped supporting it since the introduction of encrypted disk support in Windows 8/7/Vista from 5/2014, and as such any new security issues are unfixed. The benchmark itself is a good representation of microarchitectural advantages for base encryption methods.
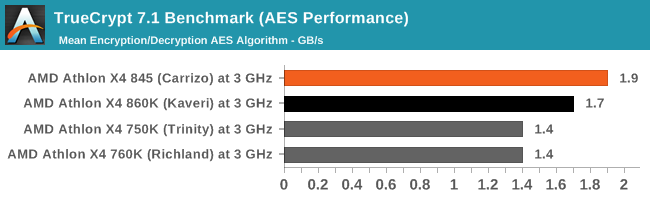
The AES performance for Carrizo is notably above Trinity/Richland, and pulls a 12% gain over Kaveri as well.
x264 HD 3.0
Similarly, the x264 HD 3.0 package we use here is also kept for historic regressional data. The latest version is 5.0.1, and encodes a 1080p video clip into a high quality x264 file. Version 3.0 only performs the same test on a 720p file, and in most circumstances the software performance hits its limit on high end processors, but still works well for mainstream and low-end. Also, this version only takes a few minutes, whereas the latest can take over 90 minutes to run.
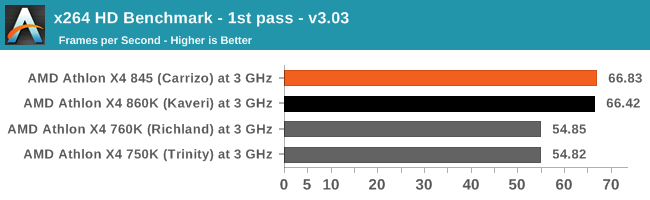
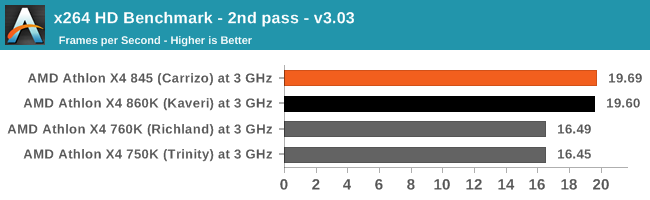
Using slightly older conversion tools shows that Carrizo and Kaveri, when the frames are small, are essentially neck and neck for performance (but still 20% over Trinity/Richland).
7-zip
7-Zip is a freeware compression/decompression tool that is widely deployed across the world. We run the included benchmark tool using a 50MB library and take the average of a set of fixed-time results.
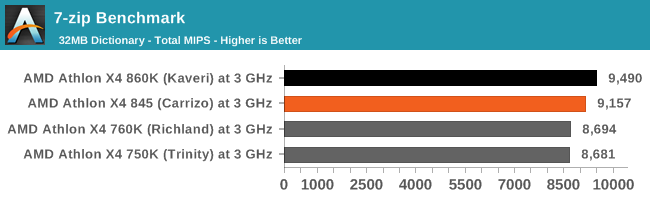
The 2MB of L2 cache for Carrizo hurts here. It makes we wonder how much more performance a 4MB cache would provide.








131 Comments
View All Comments
The_Countess - Tuesday, July 19, 2016 - link
actually bulldozer on 14nm would have been a completely different beast. it would have allowed AMD to use far more transistors per core while still making it way smaller in terms of size. that would have allowed AMD to create a far wider execution core, eliminating most of its bottlenecks.the high latency cache would probably still means it wouldn't be great for games but for everything else it would be a far more competitive design.
it is also 14nm that will allow zen to make such a massive leap in IPC's as it will be a very wide Core, while still being pretty small, something that just can't be done on 28nm.
bulldozer might not have been the best idea, but being stuck on 32/28nm for so long made all it's issues infinitely worse.
nandnandnand - Thursday, July 14, 2016 - link
"Well better late than never for Andantech,"There was no point in Adanantech writing this review, because it is a chip for those people too stupid to wait until Zen. Zen is the only thing that matters.
BurntMyBacon - Friday, July 15, 2016 - link
@nandnandnand: "There was no point in Adanantech writing this review, because it is a chip for those people too stupid to wait until Zen. Zen is the only thing that matters."Now, because this review exists, people as yet uninformed have concrete data to avoid decisions that might make them look (as you put it) stupid. There is very much a point.
Byte - Thursday, July 14, 2016 - link
Zen will probably be the RX480 in the CPU world. Better performance, still trounced by the competition, but competently priced.looncraz - Friday, July 15, 2016 - link
That would be an improvement on the current situation. AMD is pricing their CPUs quite poorly right now.An Intel Celeron G3900 is $50 right now. AMD's closest competition is the A6-7400k - at $55.
Both are dual cores, both are 65W, both have middling (but usable) graphics performance... quite similar at first glance... except the Intel runs at 2.8Ghz and the AMD runs at 3.5Ghz w/ 3.9Ghz turbo and can rather easily exceed 4Ghz when overclocked.
Sounds like AMD should be taking home the gold on that one, until you find that the Celeron is nearly 25% faster in single threaded programs and is ~40% faster in multi-threaded programs... Bad deal going for the AMD... especially since the same board that hosts the Celeron can accept much faster CPUs and the AMD board simply doesn't have notably more powerful options available - you can upgrade to a quad core, but you won't be getting better single threaded performance no matter how hard you try. You might break even around 5Ghz, if you can manage it...
AMD has a 40% clock-speed advantage out the gate, but loses by a large margin.
bananaforscale - Friday, July 15, 2016 - link
You know what's funny? The fact that if I want to get a CPU that's faster than the FX-6100 I bought almost 5 years ago I still have to pay more than what I paid for it. Sure, Intel gives better single thread performance but I'd get fewer cores and no overclockability. Then there's the fact that I've been running that original Bulldozer with a 20% OC and it seems more stable than at stock clocks.Comparing single data points tells nobody a thing. Anyway, isn't that A6 in your comparison unlocked? :P
wumpus - Friday, July 15, 2016 - link
I'm sure you missed an FX-8320 sale, or you really nailed the low point. Unfortunately Intel can match AMD's performance at nearly the same price, and is cutting off AMD's air supply that way.artk2219 - Monday, July 18, 2016 - link
Whats crazy is that Microcenter sells the FX 8320E's for $89.99. They also have a motherboard bundle option that you can get for $125 to $170 depending on which board you choose. Theoretically you can get a processor, motherboard, cooler, and memory for the price of a non-K core I5, or just a motherboard and processor for the price of an I3. The unfortunate thing is that not everyone has a microcenter near them, but for the ones that do you can get quite the deal, especially since those 8320E's will easily OC to FX 8350 levels, and more likely 4.2 to 4.6 from a stock clock of 3.2BlueBlazer - Friday, July 15, 2016 - link
From the leaks plus AMD's vague announcements, all points to AMD's Zen is going to be quite late (right into 2017). Why put use 28nm "placeholder" for AM4 if Zen is due soon? Also Global Foundries only has 14nm LPP which is a low power process. That may mean the frequency is going to be low (just look at the chips made on 14nm LPP like Qualcomm's Snapdragon 820, or even AMD's latest Radeon RX480). Reference http://semiengineering.com/high-performance-and-lo... quote "The “LP” processes are optimized for low power and feature design rules targeted for the lowest leakage, support lower operative voltages, and tend to have the slowest transistors of the three options".wiboonsin - Sunday, November 12, 2017 - link
I have read your article, it is very informative and helpful for me.I admire the valuable information you offer in your articles. Thanks for posting http://www.fanaticrunningwear.com/