The NVIDIA GeForce GTX 1080 & GTX 1070 Founders Editions Review: Kicking Off the FinFET Generation
by Ryan Smith on July 20, 2016 8:45 AM ESTSynthetics
Though we’ve covered bits and pieces of synthetic performance when discussing aspects of the Pascal architecture, before we move on to power testing I want to take a deeper look at synthetic performance. Based on what we know about the Pascal architecture we should have a good idea of what to expect, but these tests none the less serve as a canary for any architectural changes we may have missed.

Starting off with tessellation performance, we find that the GTX 1080 further builds on NVIDIA’s already impressive tessellation performance. Unrivaled at this point, GTX 1080 delivers a 63% increase in tessellation performance here, and maintains a 24% lead over GTX 1070. Suffice it to say, the Pascal cards will have no trouble keeping up with geometry needs in games for a long time to come.
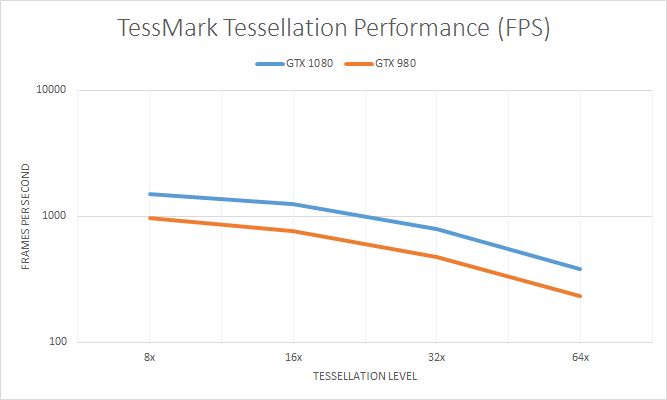
Breaking down performance by tessellation level to look at the GTX 980 and GTX 1080 more closely on a logarithmic scale, what we find is that there’s a rather consistent advantage for the GTX 1080 at all tessellation levels. Even 8x tessellation is still 56% faster. This indicates that NVIDIA hasn’t made any fundamental changes to their geometry hardware (PolyMorph Engines) between Maxwell 2 and Pascal. Everything has simply been scaled up in clockspeed and scaled out in the total number of engines. Though I will note that the performance gains are less than the theoretical maximum, so we're not seeing perfect scaling by any means.
Up next, we have SteamVR’s Performance Test. While this test is based on the latest version of Valve’s Source engine, the test itself is purely synthetic, designed to test the suitability of systems for VR, making it our sole VR-focused test at this time. It should be noted that the results in this test are not linear, and furthermore the score is capped at 11. Of particular note, cards that fail to reach GTX 970/R9 290 levels fall off of a cliff rather quickly. So test results should be interpreted a little differently.

With the minimum recommended GTX 970 and Radeon R9 290 cards get in the mid-to-high 6 range, NVIDIA’s new Pascal cards max out the score at 11. Which for the purposes of this test means that both cards exceed Valve’s recommended specifications, making them capable of running Valve’s VR software at maximum quality with no performance issues.
Finally, for looking at texel and pixel fillrate, for 2016 we have switched from the rather old 3DMark Vantage to the Beyond3D Test Suite. This test offers a slew of additional tests – many of which use behind the scenes or in our earlier architectural analysis – but for now we’ll stick to simple pixel and texel fillrates.
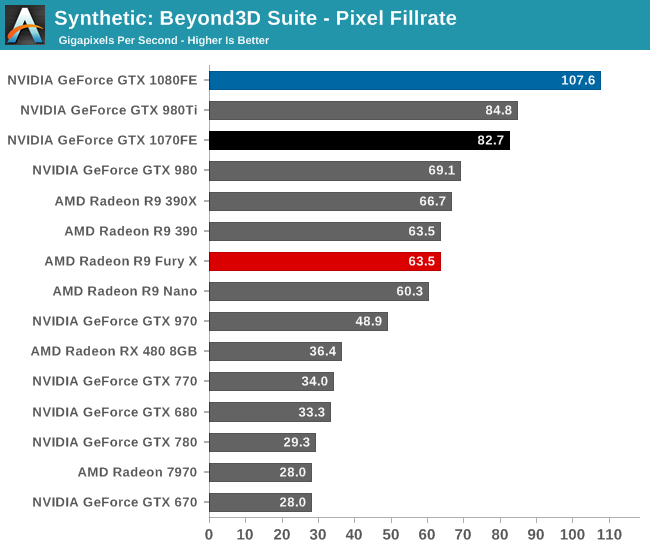
Starting with pixel fillrate, the GTX 1080 is well in the lead. While at 64 ROPs GP104 has fewer ROPs than the GM200 based GTX 980 Ti, it more than makes up for the difference with significantly higher clockspeeds. Similarly, when it comes to feeding those ROPs, GP104’s narrower memory bus is more than offset with the use of 10Gbps GDDR5X. But even then the two should be closer than this on paper, so the GTX 1080 is exceeding expectations.
As we discovered in 2014 with Maxwell 2, NVIDIA’s Delta Color Compression technology has a huge impact on pixel fillrate testing. So most likely what we’re seeing here is Pascal’s 4th generation DCC in action, helping GTX 1080 further compress its buffers and squeeze more performance out of the ROPs.
Though with that in mind, it’s interesting to note that even with an additional generation of DCC, this really only helps NVIDIA keep pace. The actual performance gains here versus GTX 980 are 56%, not too far removed from the gains we see in games and well below the theoretical difference in FLOPs. So despite the increase in pixel throughput due to architectural efficiency, it’s really only enough to help keep up with the other areas of the more powerful Pascal GPU.
As for GTX 1070, things are a bit different. The card has all of the ROPs of GTX 1080 and 80% of the memory bandwidth, however what it doesn’t have is GP104’s 4th GPC. Home of the Raster Engine responsible for rasterization, GTX 1070 can only setup 48 pixels/clock to begin with, despite the fact that the ROPs can accept 64 pixels. As a result it takes a significant hit here, delivering 77% of GTX 1080’s pixel throughput. With all of that said, the fact that in-game performance is closer than this is a reminder to the fact that while pixel throughput is an important part of game performance, it’s often not the bottleneck.

As for INT8 texel fillrates, the results are much more straightforward. GTX 1080’s improvement over GTX 980 in texel throughput almost perfectly matches the theoretical improvement we’d expect based on the specifications (if not slightly exceeding it), delivering an 85% boost. As a result it’s now the top card in our charts for texel throughput, dethroning the still-potent Fury X. Meanwhile GTX 1070 backs off a bit from these gains, as we’d expect, as a consequence of having only three-quarters the number of texture units.








200 Comments
View All Comments
patrickjp93 - Wednesday, July 20, 2016 - link
That doesn't actually support your point...Scali - Wednesday, July 20, 2016 - link
Did I read a different article?Because the article that I read said that the 'holes' would be pretty similar on Maxwell v2 and Pascal, given that they have very similar architectures. However, Pascal is more efficient at filling the holes with its dynamic repartitioning.
mr.techguru - Wednesday, July 20, 2016 - link
Just Ordered the MSI GeForce GTX 1070 Gaming X , way better than 1060 / 480. NVidia Nail it :)tipoo - Wednesday, July 20, 2016 - link
" NVIDIA tells us that it can be done in under 100us (0.1ms), or about 170,000 clock cycles."Is my understanding right that Polaris, and I think even earlier with late GCN parts, could seamlessly interleave per-clock? So 170,000 times faster than Pascal in clock cycles (less in total time, but still above 100,000 times faster)?
Scali - Wednesday, July 20, 2016 - link
That seems highly unlikely. Switching to another task is going to take some time, because you also need to switch all the registers, buffers, caches need to be re-filled etc.The only way to avoid most of that is to duplicate the whole register file, like HyperThreading does. That's doable on an x86 CPU, but a GPU has way more registers.
Besides, as we can see, nVidia's approach is fast enough in practice. Why throw tons of silicon on making context switching faster than it needs to be? You want to avoid context switches as much as possible anyway.
Sadly AMD doesn't seem to go into any detail, but I'm pretty sure it's going to be in the same ballpark.
My guess is that what AMD calls an 'ACE' is actually very similar to the SMs and their command queues on the Pascal side.
Ryan Smith - Wednesday, July 20, 2016 - link
Task switching is separate from interleaving. Interleaving takes place on all GPUs as a basic form of latency hiding (GPUs are very high latency).The big difference is that interleaving uses different threads from the same task; task switching by its very nature loads up another task entirely.
Scali - Thursday, July 21, 2016 - link
After re-reading AMD's asynchronous shader PDF, it seems that AMD also speaks of 'interleaving' when they switch a graphics CU to a compute task after the graphics task has completed. So 'interleaving' at task level, rather than at instruction level.Which would be pretty much the same as NVidia's Dynamic Load Balancing in Pascal.
eddman - Thursday, July 21, 2016 - link
The more I read about async computing in Polaris and Pascal, the more I realize that the implementations are not much different.As Ryan pointed out, it seems that the reason that Polaris, and GCN as a whole, benefit more from async is the architecture of the GPU itself, being wider and having more ALUs.
Nonetheless, I'm sure we're still going to see comments like "Polaris does async in hardware. Pascal is hopeless with its software async hack".
Matt Doyle - Wednesday, July 20, 2016 - link
Typo in the lead sentence of HPC vs. Consumer: Divergence paragraph: "Pascal in an architecture that...""is" instead of "in"
Matt Doyle - Wednesday, July 20, 2016 - link
Feeding Pascal page, "GDDR5X uses a 16n prefetch, which is twice the size of GDDR5’s 8n prefect."Prefect = prefetch