The NVIDIA GeForce GTX 1080 & GTX 1070 Founders Editions Review: Kicking Off the FinFET Generation
by Ryan Smith on July 20, 2016 8:45 AM ESTThe Witcher 3
The third game in CD Projekt RED’s expansive RPG series, The Witcher 3 is our RPG benchmark of choice. Utilizing the company’s in-house engine, REDengine 3, The Witcher makes use of an array of DirectX 11 features, all of which combine to make the game both stunning and surprisingly GPU-intensive. Our benchmark is based on an action-heavy in-engine cutscene early in the game, and Hairworks is disabled.
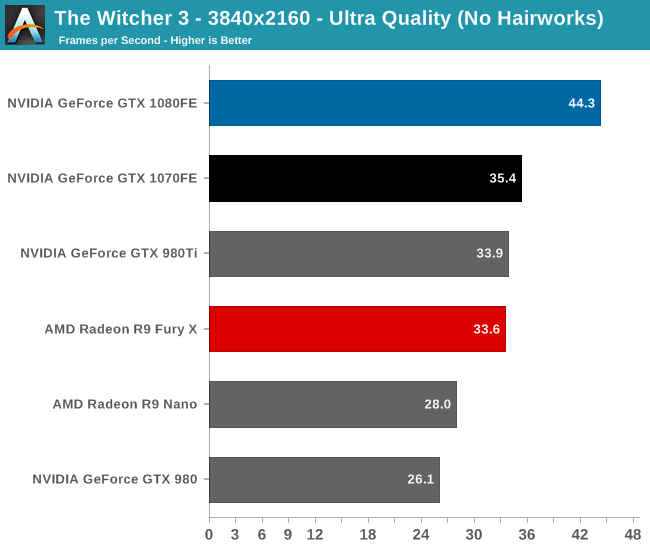

The GTX 1080 never doesn’t lead in our benchmarks, but The Witcher 3 is another strong showing for the card. At 44fps for 4K, it’s three-quarters of the way to 60fps, with gives us a reasonably playable framerate even at these high quality settings. However to get 60fps you’ll still have to back off on the quality settings or resolution. Meanwhile the GTX 1070, although capable of better than 30fps at 4K, is more at home at 1440p, where the card just cracks 60fps.
Looking at the generational comparisons, the Pascal cards are about average under The Witcher 3. GTX 1080 leads GTX 980 by an average of 66%, and GTX 1070 leads GTX 970 by 58%. Similarly, the gap between the two Pascal cards is pretty typical at 24% in favor of the GTX 1080.
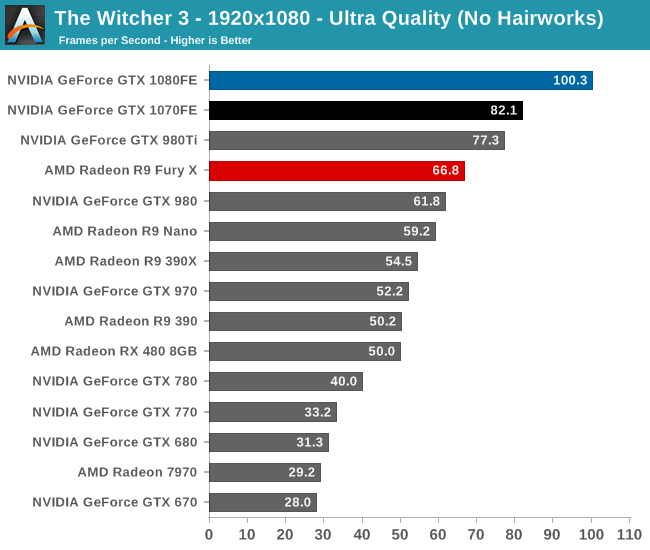
Finally, checking in on poor Kepler, we find GTX 680 at 31.3fps at 1080p, as compared to GTX 1080’s 100.3fps. This gives NVIDIA’s latest flagship a 3.2x advantage over its 4 year old predecessor.








200 Comments
View All Comments
patrickjp93 - Wednesday, July 20, 2016 - link
That doesn't actually support your point...Scali - Wednesday, July 20, 2016 - link
Did I read a different article?Because the article that I read said that the 'holes' would be pretty similar on Maxwell v2 and Pascal, given that they have very similar architectures. However, Pascal is more efficient at filling the holes with its dynamic repartitioning.
mr.techguru - Wednesday, July 20, 2016 - link
Just Ordered the MSI GeForce GTX 1070 Gaming X , way better than 1060 / 480. NVidia Nail it :)tipoo - Wednesday, July 20, 2016 - link
" NVIDIA tells us that it can be done in under 100us (0.1ms), or about 170,000 clock cycles."Is my understanding right that Polaris, and I think even earlier with late GCN parts, could seamlessly interleave per-clock? So 170,000 times faster than Pascal in clock cycles (less in total time, but still above 100,000 times faster)?
Scali - Wednesday, July 20, 2016 - link
That seems highly unlikely. Switching to another task is going to take some time, because you also need to switch all the registers, buffers, caches need to be re-filled etc.The only way to avoid most of that is to duplicate the whole register file, like HyperThreading does. That's doable on an x86 CPU, but a GPU has way more registers.
Besides, as we can see, nVidia's approach is fast enough in practice. Why throw tons of silicon on making context switching faster than it needs to be? You want to avoid context switches as much as possible anyway.
Sadly AMD doesn't seem to go into any detail, but I'm pretty sure it's going to be in the same ballpark.
My guess is that what AMD calls an 'ACE' is actually very similar to the SMs and their command queues on the Pascal side.
Ryan Smith - Wednesday, July 20, 2016 - link
Task switching is separate from interleaving. Interleaving takes place on all GPUs as a basic form of latency hiding (GPUs are very high latency).The big difference is that interleaving uses different threads from the same task; task switching by its very nature loads up another task entirely.
Scali - Thursday, July 21, 2016 - link
After re-reading AMD's asynchronous shader PDF, it seems that AMD also speaks of 'interleaving' when they switch a graphics CU to a compute task after the graphics task has completed. So 'interleaving' at task level, rather than at instruction level.Which would be pretty much the same as NVidia's Dynamic Load Balancing in Pascal.
eddman - Thursday, July 21, 2016 - link
The more I read about async computing in Polaris and Pascal, the more I realize that the implementations are not much different.As Ryan pointed out, it seems that the reason that Polaris, and GCN as a whole, benefit more from async is the architecture of the GPU itself, being wider and having more ALUs.
Nonetheless, I'm sure we're still going to see comments like "Polaris does async in hardware. Pascal is hopeless with its software async hack".
Matt Doyle - Wednesday, July 20, 2016 - link
Typo in the lead sentence of HPC vs. Consumer: Divergence paragraph: "Pascal in an architecture that...""is" instead of "in"
Matt Doyle - Wednesday, July 20, 2016 - link
Feeding Pascal page, "GDDR5X uses a 16n prefetch, which is twice the size of GDDR5’s 8n prefect."Prefect = prefetch