The NVIDIA GeForce GTX 1080 & GTX 1070 Founders Editions Review: Kicking Off the FinFET Generation
by Ryan Smith on July 20, 2016 8:45 AM ESTSLI: The Abridged Version
Not to be outdone by their efforts to reduce input lag, for Pascal NVIDIA is also rolling out some fairly important changes to SLI. These operate at both the hardware level and the software level, and for gamers fortunate enough to be able to own multiple Pascal cards, they will want to pay close attention to this.
On the hardware side of matters, NVIDIA is boosting the speed of the SLI connection. Previously with Maxwell 2 it operated at up to 400MHz, but with Pascal it can now operate at up to 650MHz. This is a substantial 63% increase in link speed.
However to actually get the faster link speed, in many cases new(er) SLI bridges are needed. The older bridges, particularly the flexible bridges, are not rated nor capable of supporting 650MHz. Only the more recent (and relatively rare) LED bridge, and NVIDIA’s brand new High Bandwidth (HB) bridge are capable of 650MHz.

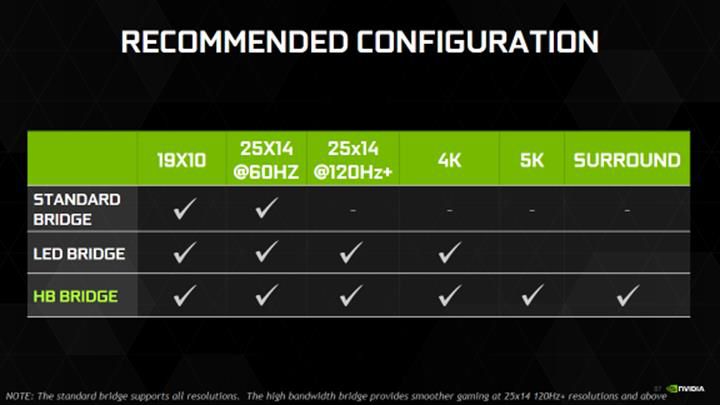
And while the older LED Bridge is 650MHz capable, NVIDIA is still going to be phasing it out in favor of the new HB Bridge. The reason why is because it adds support for Pascal’s second SLI hardware feature: SLI link teaming.
With previous GPU generations, a GPU could only use a single SLI link to communicate with another GPU. The purpose of including multiple SLI links on a high-end card then was to allow it to communicate with multiple (3+) cards. But if you had a more basic 2-way SLI setup, then the second link on each card would go unused.
Pascal changes this up by allowing the SLI links to be teamed. Now two cards can connect to each other over two links, almost doubling the amount of bandwidth between the cards. Combined with the higher frequency of the SLI link itself, and the effective increase in bandwidth between cards in a 2-way SLI setup is 170%, or just short of a 3x increase in bandwidth.
The purpose of teaming SLI links is that even though the bandwidth boost from the higher link frequency is significant, for the highest resolutions and refresh rates it’s still not enough. By NVIDIA’s own admittance, SLI performance at better than 1440p60 was subpar, as the SLI interface would get saturated. The faster link gets NVIDIA enough bandwidth to comfortably handle 2-way SLI at 1440p120 and 4Kp60, but that’s it. Once you go past that, to configurations that essentially require DisplayPort 1.3+ (4Kp120, 5Kp60, and multi-monitor surround), then even a single 650MHz link isn’t enough. Ergo NVIDIA has started link teaming to get yet more bandwidth.

Getting back to the new HB bridge then, the new bridge is being introduced to provide a bridge suitable for link teaming. Previous bridges simply weren’t wired two have multiple links connect the same video cards – the cards didn’t support such a thing – whereas HB bridges are. Meanwhile as these are fixed (PCB) bridges, NVIDIA is offering their reference bridges in 3 sizes: 2 (40mm), 3 (60mm), and 4 (80mm) slot spacing, to mesh with cards that are either directly next to each other, have 1 empty slot between them, or 2 empty slots between them. NVIDIA is selling the new HB bridge for $40 over on their store, and NVIDIA’s partners are also preparing their own custom bridges. EVGA has announced a LED-let HB bridge, as the LED bridges proved rather popular with both system builders and customers looking for a bit more flare for their windowed cases.
Meanwhile, on a brief aside, I asked NVIDIA why they were still using SLI bridges instead of just routing everything over PCI Express. While I doubt they mind selling $40 bridges, the technical answer is that all things considered, this gave them more bandwidth. Rather than having to share potentially valuable PCIe bandwidth with CPU-GPU communication, the SLI links are dedicated links, eliminating any contention and potentially making them more reliable. The SLI links are also directly routed to the display controller, so there’s a bit more straightforward (lower latency) path as well.
Deprecated: 3-Way & 4-Way SLI
These aforementioned hardware updates to SLI are also having a major impact on the kinds of SLI configurations NVIDIA is going to be able (and willing) to support in the future. With both available SLI links on a Pascal card now teamed together for a single card, it’s not possible to do 3-way/4-way SLI and link teaming at the same time, as there aren’t enough links for both. As a result, NVIDIA is going to be deprecating 3-way and 4-way SLI.
Until shortly after the GTX 1080 launch, NVIDIA’s plans here were actually a bit more complex – involving a feature the company called an Enthusiast Key – but thankfully things have been simplified some. As it stands, NVIDIA is not going to be eliminating support for 3-way and 4-way SLI entirely; if you have a 3/4–way bridge, you can still setup a 3+ card configuration, bandwidth limitations and all. But for the Pascal generation there are going to be focusing their development resources on 2-way SLI, hence making 3-way and 4-way SLI deprecated.
In practice the way this will work is that NVIDIA will only be supporting 3 and 4-way SLI for a small number of programs – things like Unigine and 3DMark that are used by competitive benchmarkers/overclockers, so that they may continue their practices. For actual gamer use they are strongly discouraging anything over 2-way SLI, and in fact NVIDIA will not be enabling 3+ card configurations in their drivers for the vast majority of games (unless a developer specifically comes to them and asks). This all but puts an end to 3-way and 4-way SLI on consumer gaming setups.
As for why NVIDIA would want to do this, the answer boils down to two factors. The first of course is the introduction of SLI link teaming, while the second has to deal with games themselves. As we’ve discussed in the past, game engines are increasingly becoming AFR-unfriendly, which is making it harder and harder to get performance benefits out of SLI. 2-way SLI is hard enough, never mind 3/4-way SLI where upwards of 4 frames need to be rendered concurrently. Consequently, with greater bandwidth requirements necessitating link teaming, Pascal is as good a point as any to deprecate larger SLI card configurations.
Now with all of that said, however. DirectX 12 makes the picture a little more complex still. Because DirectX 12 adds new multi-GPU modes – some of which radically change how mGPU works – NVIDIA’s own changes only impact specific scenarios. All DX9/10/11 games are impacted by the new 2-way SLI limit. However whether a DX12 game is impacted depends on the mGPU mode used.

In implicit mode, which essentially recreates DX11 style mGPU under DX12, the 2-way SLI limit is in play. This mode is, by design, under the control of the GPU vendor and relies on all of the same mGPU technologies as are already in use today. This means traffic passes over the SLI bridge, and NVIDIA will only be working to optimize mGPU for 2-way SLI.
However with explicit mode, the 2-way limit is lifted. In explicit mode it’s the game developer that has control over how mGPU works – NVIDIA has no responsibility here – and it’s up to them to decide if they want to support more than 2 GPUs. In unlinked explicit mode this is all relatively straightforward, with the game addressing each GPU separately and working over the PCIe bus.
Meanwhile in explicit linked mode, where the relevant GPUs are presented as a single linked adapter, the GPU limit is still up to the developer. In this mode developers can even use the SLI bridge if they want – though again keeping in mind the bandwidth limitations – and it’s the most powerful mode for matching GPUs.
As for whether developers will actually want to support 3+ GPUs using DX12 explicit multiadapter, this remains to be seen. So far of the small number of games to even use it, none support 3+ GPUs, and as with NVIDIA-managed mGPU, the larger the number of GPUs the harder the task of keeping them all productive. We will have to see what developers decide to do, but outside of dedicated benchmarks (e.g. 3DMark) I would be a bit surprised to see developers support anything more than 2 GPUs.








200 Comments
View All Comments
Robalov - Tuesday, July 26, 2016 - link
Feels like it took 2 years longer than normal for this review :Dextide - Wednesday, July 27, 2016 - link
The venn diagram is wrong -- for GP104 it says 1:64 speed for FP16 -- it is actually 1:1 for FP16 (ie same speed as FP32) (NOTE: GP100 has 2:1 FP16 -- meaning FP16 is twice as fast as FP32)extide - Wednesday, July 27, 2016 - link
EDIT: I might be incorrect about this actually as I have seen information claiming both .. weird.mxthunder - Friday, July 29, 2016 - link
its really driving me nuts that a 780 was used instead of a 780ti.yhselp - Monday, August 8, 2016 - link
Have I understood correctly that Pascal offers a 20% increase in memory bandwidth from delta color compression over Maxwell? As in a total average of 45% over Kepler just from color compression?flexy - Sunday, September 4, 2016 - link
Sorry, late comment. I just read about GPU Boost 3.0 and this is AWESOME. What they did, is expose what previously was only doable with bios modding - eg assigning the CLK bins different voltages. The problem with overclocking Kepler/Maxwell was NOT so much that you got stuck with the "lowest" overclock as the article says, but that simply adding a FIXED amount of clocks across the entire range of clocks, as you would do with Afterburner etc. where you simply add, say +120 to the core. What happened here is that you may be "stable" at the max overclock (CLK bin), but since you added more CLKs to EVERY clock bin, the assigned voltages (in the BIOS) for each bin might not be sufficient. Say you have CLK bin 63 which is set to 1304Mhz in a stock bios. Now you use Afterburner and add 150 Mhz, now all of a sudden this bin amounts to 1454Mhz BUT STILL at the same voltage as before, which is too low for 1454Mhz. You had to manually edit the table in the BIOS to shift clocks around, especially since not all Maxwell cards allowed adding voltage via software.Ether.86 - Tuesday, November 1, 2016 - link
Astonishing review. That's the way Anandtech should be not like the mobile section which sucks...Warsun - Tuesday, January 17, 2017 - link
Yeah looking at the bottom here.The GTX 1070 is on the same level as a single 480 4GB card.So that graph is wrong.http://www.hwcompare.com/30889/geforce-gtx-1070-vs...
Remember this is from GPU-Z based on hardware specs.No amount of configurations in the Drivers changes this.They either screwed up i am calling shenanigans.
marceloamaral - Thursday, April 13, 2017 - link
Nice Ryan Smith! But, my question is, is it truly possible to share the GPU with different workloads in the P100? I've read in the NVIDIA manual that "The GPU has a time sliced scheduler to schedule work from work queues belonging to different CUDA contexts. Work launched to the compute engine from work queues belonging to different CUDA contexts cannot execute concurrently."marceloamaral - Thursday, April 13, 2017 - link
Nice Ryan Smith! But, my question is, is it truly possible to share the GPU with different workloads in the P100? I've read in the NVIDIA manual that "The GPU has a time sliced scheduler to schedule work from work queues belonging to different CUDA contexts. Work launched to the compute engine from work queues belonging to different CUDA contexts cannot execute concurrently."