The NVIDIA GeForce GTX 1080 & GTX 1070 Founders Editions Review: Kicking Off the FinFET Generation
by Ryan Smith on July 20, 2016 8:45 AM ESTAshes of the Singularity
Sorely missing from our benchmark suite for quite some time have been RTSes, which don’t enjoy quite the popularity they once did. As a result Ashes holds a special place in our hearts, and that’s before we talk about the technical aspects. Based on developer Oxide Games’ Nitrous Engine, Ashes has been designed from the ground up for low-level APIs like DirectX 12. As a result of all of the games in our benchmark suite, this is the game making the best use of DirectX 12’s various features, from asynchronous compute to multi-threadeded work submission and high batch counts. What we see can’t be extrapolated to all DirectX 12 games, but it gives us a very interesting look at what we might expect in the future.
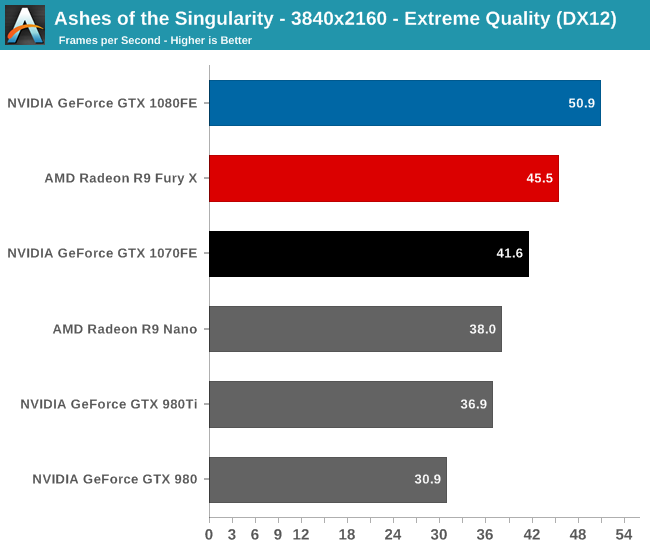
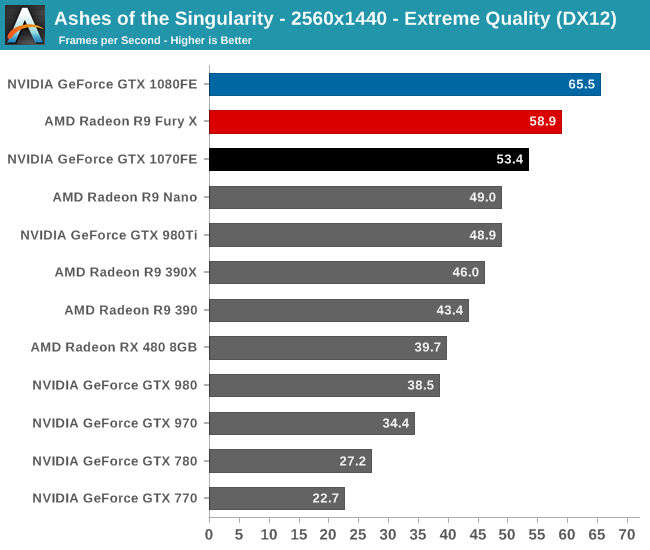

Once again the top spot is uncontested by the GTX 1080. However after that, things become more interesting. On the whole, Ashes is a game that favors AMD GPU over NVIDIA GPUs, and as a result the GTX 1070 does not get to lock in second place. Rather that goes to the last generation Fury X. AMD designs are very ALU-heavy, and I suspect Ashes is capable of putting those ALUs to good use, something most other games struggle with. That said, if we normalized this for price or power consumption, then the Pascal cards would be well in the lead, but it does show that on an absolute basis, GTX 1070 isn’t going to outrun the best of the last-gen cards all the time.
Meanwhile it’s interesting to note that one of the more unusual aspects of the engine behind Ashes is that it’s relatively resolution insensitive. That is, performance only drops moderately as we increase the resolution. This means that we need a GTX 1070 to sustain better than 60fps at 1080p, but that same card is still getting better than 40fps at 4K, a resolution with 4x the pixels.
Finally, looking at our NVIDIA cards on a generational basis, even without their commanding lead, the two Pascal cards show the expected generational gains. GTX 1080 improves on GTX 980 by between 65% and 70%, and GTX 1070 improves on GTX 970 by between 53% and 58%.








200 Comments
View All Comments
Ryan Smith - Friday, July 22, 2016 - link
2) I suspect the v-sync comparison is a 3 deep buffer at a very high framerate.lagittaja - Sunday, July 24, 2016 - link
1) It is a big part of it. Remember how bad 20nm was?The leakage was really high so Nvidia/AMD decided to skip it. FinFET's helped reduce the leakage for the "14/16"nm node.
That's apples to oranges. CPU's are already 3-4Ghz out of the box.
RX480 isn't showing it because the 14nm LPP node is a lemon for GPU's.
You know what's the optimal frequency for Polaris 10? 1Ghz. After that the required voltage shoots up.
You know, LPP where the LP stands for Low Power. Great for SoC's but GPU's? Not so much.
"But the SoC's clock higher than 2Ghz blabla". Yeah, well a) that's the CPU and b) it's freaking tiny.
How are we getting 2Ghz+ frequencies with Pascal which so closely resembles Maxwell?
Because of the smaller manufacturing node. How's that possible? It's because of FinFET's which reduced the leakage of the 20nm node.
Why couldn't we have higher clockspeeds without FinFET's at 28nm? Because power.
28nm GPU's capped around the 1.2-1.4Ghz mark.
20nm was no go, too high leakage current.
16nm gives you FinFET's which reduced the leakage current dramatically.
What does that enable you to do? Increase the clockspeed..
Here's a good article
http://www.anandtech.com/show/8223/an-introduction...
lagittaja - Sunday, July 24, 2016 - link
As an addition to the RX 480 / Polaris 10 clockspeedGCN2-GCN4 VDD vs Fmax at avg ASIC
http://i.imgur.com/Hdgkv0F.png
timchen - Thursday, July 21, 2016 - link
Another question is about boost 3.0: given that we see 150-200 Mhz gpu offset very common across boards, wouldn't it be beneficial to undervolt (i.e. disallow the highest voltage bins corresponding to this extra 150-200 Mhz) and offset at the same time to maintain performance at lower power consumption? Why did Nvidia not do this in the first place? (This is coming from reading Tom's saying that 1060 can be a 60w card having 80% of its performance...)AnnonymousCoward - Thursday, July 21, 2016 - link
NVIDIA, get with the program and support VESA Adaptive-Sync already!!! When your $700 card can't support the VESA standard that's in my monitor, and as a result I have to live with more lag and lower framerate, something is seriously wrong. And why wouldn't you want to make your product more flexible?? I'm looking squarely at you, Tom Petersen. Don't get hung up on your G-sync patent and support VESA!AnnonymousCoward - Thursday, July 21, 2016 - link
If the stock cards reach the 83C throttle point, I don't see what benefit an OC gives (won't you just reach that sooner?). It seems like raising the TDP or under-voltaging would boost continuous performance. Your thoughts?modeless - Friday, July 22, 2016 - link
Thanks for the in depth FP16 section! I've been looking forward to the full review. I have to say this is puzzling. Why put it on there at all? Emulation would be faster. But anyway, NVIDIA announced a new Titan X just now! Does this one have FP16 for $1200? Instant buy for me if so.Ryan Smith - Friday, July 22, 2016 - link
Emulation would be faster, but it would not be the same as running it on a real FP16x2 unit. It's the same purpose as FP64 units: for binary compatibility so that developers can write and debug Tesla applications on their GeForce GPU.hoohoo - Friday, July 22, 2016 - link
Excellent article, Ryan, thank you!Especially the info on preemption and async/scheduling.
I expected the preemption mght be expensive in some circumstances, but I didn't quite expect it to push the L2 cache though! Still this is a marked improvement for nVidia.
hoohoo - Friday, July 22, 2016 - link
It seems like the preemption is implemented in the driver though? Are there actual h/w instructions to as it were "swap stack pointer", "push LDT", "swap instruction pointer"?