The NVIDIA GeForce GTX 1080 & GTX 1070 Founders Editions Review: Kicking Off the FinFET Generation
by Ryan Smith on July 20, 2016 8:45 AM ESTGP104’s Architecture
Looking at an architecture diagram for GP104, Pascal ends up looking a lot like Maxwell, and this is not by chance. After making more radical changes to their architecture with Maxwell, for Pascal NVIDIA is taking a bit of a breather. Which is not to say that Pascal is Maxwell on 16nm – this is very much a major feature update – but when it comes to discussing the core SM architecture itself, there is significant common ground with Maxwell.

We’ll start with the GP104 SM. Simply named the SM for this generation – NVIDIA has ditched the generational suffix due to the potential for confusion with the used-elsewhere SMP – the GP104 SM is very similar to the Maxwell SM. We’re still looking at a single SM partially sub-divided into four pieces, each containing a single warp scheduler that’s responsible for feeding 32 CUDA cores, 8 load/store units, and 8 Special Function Units, backed by a 64KB register file. There are two dispatch ports per warp schedule, so when an instruction stream allows it, a warp scheduler can extract a limited amount of ILP with an instruction stream by issuing a second instruction to an unused resource.
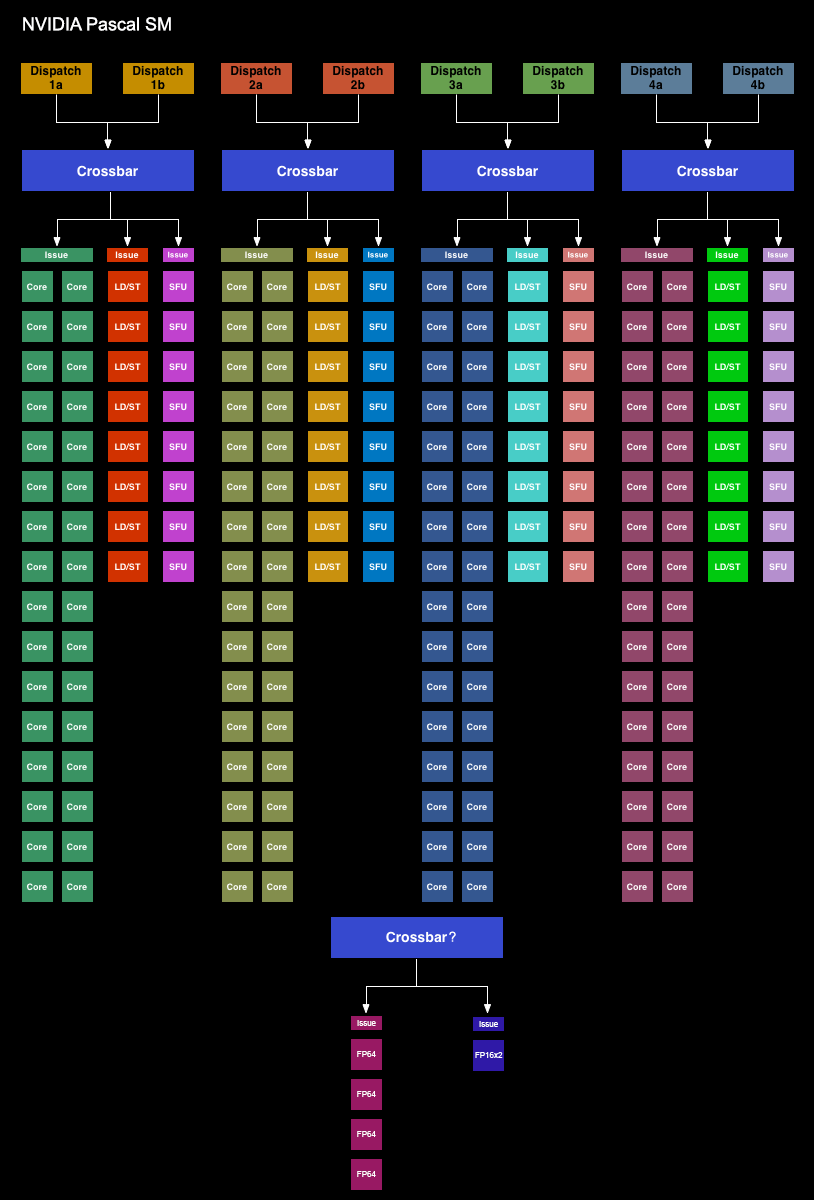
Meanwhile shared between every pair of sub-partitions is 4 texture units and the combined L1/texture cache, again unchanged from Maxwell. Finally, we have the resources shared throughout the whole SM: the 96KB shared memory, the instruction cache, and not pictured on NVIDIA’s diagrams, the 4 FP64 CUDA cores and 1 FP16x2 CUDA core.
Overall then at the diagram level the GP104 SM looks almost identical to the Maxwell SM, but with one exception: the PolyMorph Engine. Although the distinction is largely arbitrary for GP104, the PolyMorph Engine has been moved up a level; it’s no longer part of the SM, but rather part of the newly re-introduced TPC, which itself sits between the GPC and the SM.
The TPC exists because although GP104 still has a 1:1 ratio between PolyMorph Engines and SMs, the Pascal architecture itself allows for different SM configurations, which is in turn used on GP100 to allow it to have multiple smaller SMs of 64 CUDA Cores. For GP100 the TPC allows for multiple SMs to share a PolyMorph Engine, but for GP104 there’s no sharing involved. To that end the TPC as an organizational unit technically exists across all Pascal parts, but it has no real significance for GP104. In fact it doesn’t even have a real name; NVIDIA reused the acronym from earlier DX10 architectures, where the TPC was the name assigned to the Texture Processor Cluster.

Looking at the bigger picture of the complete GP104 GPU, the similarities continue between GP104 and GM204. GP104’s SMs are clustered five-a-piece inside of the GPC, with each cluster sharing a single Raster Engine. Overall there are 4 such GPCs, giving us 20 SMs altogether. Compared to GM204 then, we’re looking at the same number of GPCs, with each GPC having gained 1 SM.
Things get more interesting when we look at the back end of the rendering/execution pipeline, which is comprised of the L2 cache, ROPs, and memory controllers. The ROP/L2 count has not changed relative to GM204 – we still have 64 ROPs paired up with a total of 2MB of L2 cache – however the memory controller count has. And with it the logical configuration of the ROP/L2 blocks have changed as well.
Whereas GM204 had 4 64bit GDDR5 memory controllers, each connected to 2 or 4 memory chips, GP104 breaks that down further to 8 32bit GDDR5X memory controllers, each of which is connected to 1 memory chip on GTX 1080. I’ll go into greater detail on GDDR5X a bit later, but the significance of this backend organizational change has to do with the introduction of GDDR5X. Because GDDR5X reads and writes data in 64B amounts (versus 32B amounts on GDDR5), NVIDIA has reorganized the memory controllers to ensure that each memory controller still operates on the same amount of data. With GDDR5 they teamed up two GDDR5 channels to get 64B operations, whereas with GDDR5X this can be accomplished with a single memory channel.
This in turn is where the ROP reorganization comes from. As there’s a 1:1 relationship between ROP partitions and memory controllers, the 64 ROPs are now broken up into 8 partitions for GP104, as opposed to 4 partitions on GM204. There are some performance tradeoffs that come from having more ROP partitions, but to the best of my knowledge these should not be significant.
Meanwhile the new GDDR5X memory controllers are also backwards compatible with traditional GDDR5, which in turn is used to drive the GTX 1070 with its 8Gbps GDDR5. The difference in operation between GDDR5 and GDDR5X does make the ROP situation a bit trickier overall for NVIDIA’s architects – now they need to be able to handle two different memory access patterns – though for NVIDIA this isn’t a wholly new problem. Previous generation architectures have supported both GDDR5 and DDR3, the two of which have their own differences in memory access patterns.
In a by-the-numbers comparison then, Pascal does not bring any notable changes in throughput relative to Maxwell. CUDA cores, texture units, PolyMorph Engines, Raster Engines, and ROPs all have identical theoretical throughput-per-clock as compared to Maxwell. So on a clock-for-clock, unit-for-unit basis, Pascal is not any faster on paper. And while NVIDIA does not disclose the size/speed of most of their internal datapaths, so far I haven’t seen anything to suggest that these have radically changed. This continuity means that outside of its new features, GP104 behaves a lot like GM204. Though it should be noted that real world efficiency isn’t quite as cut and dry, as various factors such as the increased SM count and changes in memory technology can greatly influence this.








200 Comments
View All Comments
Ranger1065 - Thursday, July 21, 2016 - link
Your unwavering support for Anandtech is impressive.I too have a job that keeps me busy, yet oddly enough I find the time to browse (I prefer that word to "trawl") a number of sites.
I find it helps to form objective opinions.
I don't believe in early adoption, but I do believe in getting the job done on time, however if you are comfortable with a 2 month delay, so be it :)
Interesting to note that architectural deep dives concern your art and media departments so closely in their purchasing decisions. Who would have guessed?
It's true (God knows it's been stated here often enough) that
Anandtech goes into detail like no other, I don't dispute that.
But is it worth the wait? A significant number seem to think not.
Allow me to leave one last issue for you to ponder (assuming you have the time in your extremely busy schedule).
Is it good for Anandtech?
catavalon21 - Thursday, July 21, 2016 - link
Impatient as I was at the first for benchmarks, yes, I'm a numbers junkie, since it's evident precious few of us will have had a chance to buy one of these cards yet (or the 480), I doubt the delay has caused anyone to buy the wrong card. Can't speak for the smart phone review folks are complaining about being absent, but as it turns out, what I'm initially looking for is usually done early on in Bench. The rest of this, yeah, it can wait.mkaibear - Saturday, July 23, 2016 - link
Job, house, kids, church... more than enough to keep me sufficiently busy that I don't have the time to browse more than a few sites. I pick them quite carefully.Given the lifespan of a typical system is >5 years I think that a 2 month delay is perfectly reasonable. It can often take that long to get purchasing signoff once I've decided what they need to purchase anyway (one of the many reasons that architectural deep dives are useful - so I can explain why the purchase is worthwhile). Do you actually spend someone else's money at any point or are you just having to justify it to yourself?
Whether or not it's worth the wait to you is one thing - but it's clearly worth the wait to both Anandtech and to Purch.
razvan.uruc@gmail.com - Thursday, July 21, 2016 - link
Excellent article, well deserved the wait!giggs - Thursday, July 21, 2016 - link
While this is a very thorough and well written review, it makes me wonder about sponsored content and product placement.The PG279Q is the only monitor mentionned, making sure the brand appears, and nothing about competing products. It felt unnecessary.
I hope it's just a coincidence, but considering there has been quite a lot of coverage about Asus in the last few months, I'm starting to doubt some of the stuff I read here.
Ryan Smith - Thursday, July 21, 2016 - link
"The PG279Q is the only monitor mentionned, making sure the brand appears, and nothing about competing products."There's no product placement or the like (and if there was, it would be disclosed). I just wanted to name a popular 1440p G-Sync monitor to give some real-world connection to the results. We've had cards for a bit that can drive 1440p monitors at around 60fps, but GTX 1080 is really the first card that is going to make good use of higher refresh rate monitors.
giggs - Thursday, July 21, 2016 - link
Fair enough, thank you for responding promptly. Keep up the good work!arh2o - Thursday, July 21, 2016 - link
This is really the gold standard of reviews. More in-depth than any site on the internet. Great job Ryan, keep up the good work.Ranger1065 - Thursday, July 21, 2016 - link
This is a quality article.timchen - Thursday, July 21, 2016 - link
Great article. It is pleasant to read more about technology instead of testing results. Some questions though:1. higher frequency: I am kind of skeptical that the overall higher frequency is mostly enabled by FinFET. Maybe it is the case, but for example when Intel moved to FinFET we did not see such improvement. RX480 is not showing that either. It seems pretty evident the situation is different from 8800GTX where we first get frequency doubling/tripling only in the shader domain though. (Wow DX10 is 10 years ago... and computation throughput is improved by 20x)
2. The fastsync comparison graph looks pretty suspicious. How can Vsync have such high latency? The most latency I can see in a double buffer scenario with vsync is that the screen refresh just happens a tiny bit earlier than the completion of a buffer. That will give a delay of two frame time which is like 33 ms (Remember we are talking about a case where GPU fps>60). This is unless, of course, if they are testing vsync at 20hz or something.