The NVIDIA GeForce GTX 1080 & GTX 1070 Founders Editions Review: Kicking Off the FinFET Generation
by Ryan Smith on July 20, 2016 8:45 AM ESTFast Sync & SLI Updates: Less Latency, Fewer GPUs
Since Kepler and the GTX 680 in 2012, one of NVIDIA’s side projects in GPU development has been cooking up ways to reduce input lag. Under the watchful eye of NVIDIA’s Distinguished Engineer (and all-around frontman) Tom Petersen, the company has introduced a couple of different technologies over the years to deal with the problem. Kepler introduced adaptive v-sync – the ability to dynamically disable v-sync when the frame rate is below the refresh rate – and of course in 2013 the company introduced their G-Sync variable refresh rate technology.
Since then, Tom’s team has been working on yet another way to bend the rules of v-sync. Rolling out with Pascal is a new v-sync mode that NVIDIA is calling Fast Sync, and it is designed to offer yet another way to reduce input lag while maintaining v-sync.
It’s interesting to note that Fast Sync isn’t a wholly new idea, but rather a modern and more consistent take on an old idea: triple buffering. While in modern times triple buffering is just a 3-deep buffer that is run through as a sequential frame queue, in the days of yore some games and video cards handled triple buffering a bit differently. Rather than using the 3 buffers as a sequential queue, they would instead always overwrite the oldest buffer. This small change had a potentially significant impact on input lag, and if you’re familiar with old school triple buffering, then you know where this is going.
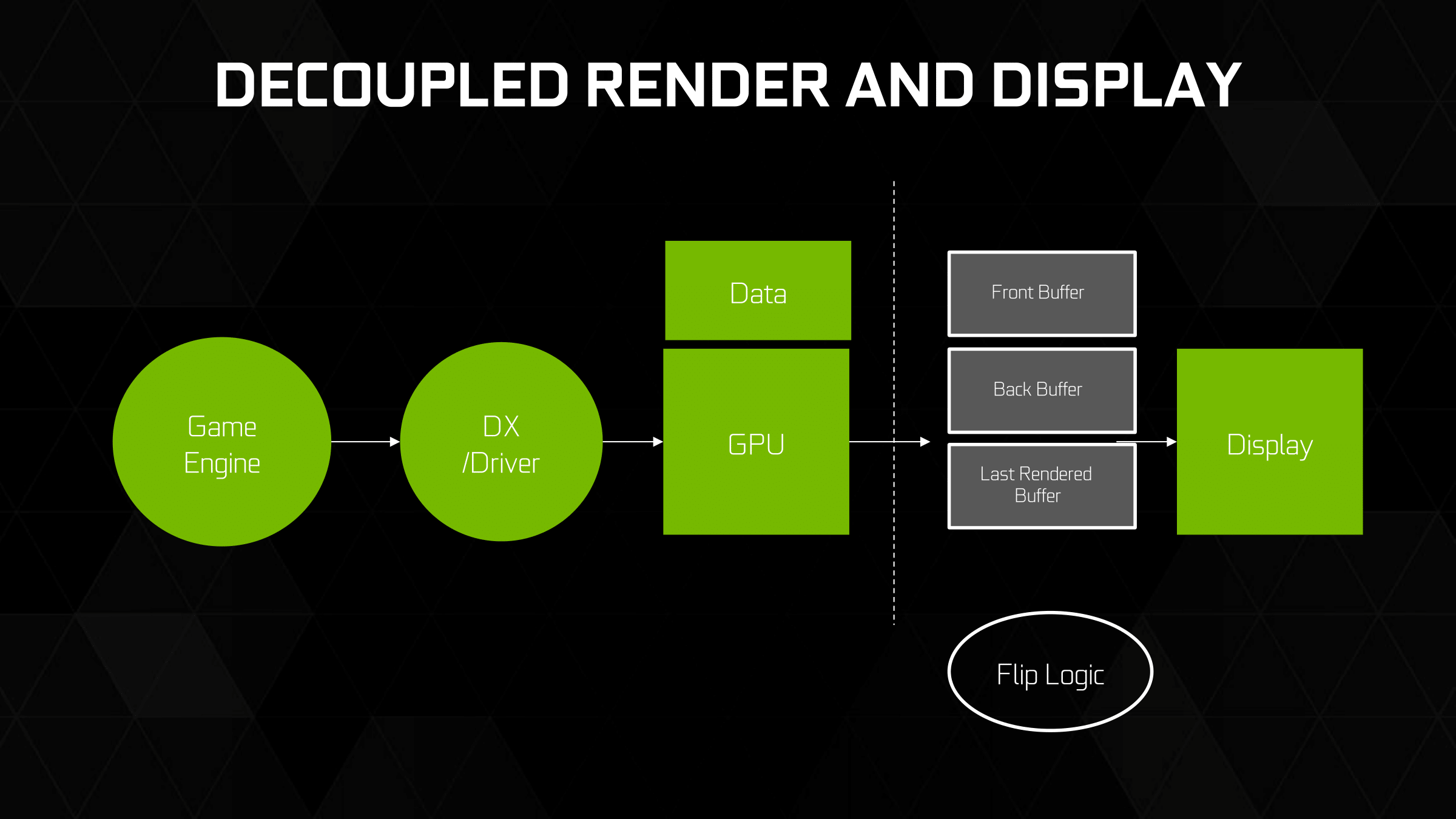
With Fast Sync, NVIDIA has implemented old school triple buffering at the driver level, once again making it usable with modern cards. The purpose of implementing Fast Sync is to reduce input lag in modern games that can generate a frame rate higher than the refresh rate, with NVIDIA specifically targeting CS:GO and other graphically simple twitch games.
But how does Fast Sync actually reduce input lag? To go into this a bit further, we have an excellent article on old school triple buffering from 2009 that I’ve republished below. Even 7 years later, other than the name the technical details are all still accurate to NVIDIA’s Fast Sync implementation.
What are Double Buffering, V-sync, and Triple Buffering?
When a computer needs to display something on a monitor, it draws a picture of what the screen is supposed to look like and sends this picture (which we will call a buffer) out to the monitor. In the old days there was only one buffer and it was continually being both drawn to and sent to the monitor. There are some advantages to this approach, but there are also very large drawbacks. Most notably, when objects on the display were updated, they would often flicker.
In order to combat the issues with reading from while drawing to the same buffer, double buffering, at a minimum, is employed. The idea behind double buffering is that the computer only draws to one buffer (called the "back" buffer) and sends the other buffer (called the "front" buffer) to the screen. After the computer finishes drawing the back buffer, the program doing the drawing does something called a buffer "swap." This swap doesn't move anything: swap only changes the names of the two buffers: the front buffer becomes the back buffer and the back buffer becomes the front buffer.
After a buffer swap, the software can start drawing to the new back buffer and the computer sends the new front buffer to the monitor until the next buffer swap happens. And all is well. Well, almost all anyway.
In this form of double buffering, a swap can happen anytime. That means that while the computer is sending data to the monitor, the swap can occur. When this happens, the rest of the screen is drawn according to what the new front buffer contains. If the new front buffer is different enough from the old front buffer, a visual artifact known as "tearing" can be seen. This type of problem can be seen often in high framerate FPS games when whipping around a corner as fast as possible. Because of the quick motion, every frame is very different, when a swap happens during drawing the discrepancy is large and can be distracting.
The most common approach to combat tearing is to wait to swap buffers until the monitor is ready for another image. The monitor is ready after it has fully drawn what was sent to it and the next vertical refresh cycle is about to start. Synchronizing buffer swaps with the Vertical refresh is called V-sync.
While enabling V-sync does fix tearing, it also sets the internal framerate of the game to, at most, the refresh rate of the monitor (typically 60Hz for most LCD panels). This can hurt performance even if the game doesn't run at 60 frames per second as there will still be artificial delays added to effect synchronization. Performance can be cut nearly in half cases where every frame takes just a little longer than 16.67 ms (1/60th of a second). In such a case, frame rate would drop to 30 FPS despite the fact that the game should run at just under 60 FPS. The elimination of tearing and consistency of framerate, however, do contribute to an added smoothness that double buffering without V-sync just can't deliver.
Input lag also becomes more of an issue with V-sync enabled. This is because the artificial delay introduced increases the difference between when something actually happened (when the frame was drawn) and when it gets displayed on screen. Input lag always exists (it is impossible to instantaneously draw what is currently happening to the screen), but the trick is to minimize it.
Our options with double buffering are a choice between possible visual problems like tearing without V-sync and an artificial delay that can negatively affect both performance and can increase input lag with V-sync enabled. But not to worry, there is an option that combines the best of both worlds with no sacrifice in quality or actual performance. That option is triple buffering.
The name gives a lot away: triple buffering uses three buffers instead of two. This additional buffer gives the computer enough space to keep a buffer locked while it is being sent to the monitor (to avoid tearing) while also not preventing the software from drawing as fast as it possibly can (even with one locked buffer there are still two that the software can bounce back and forth between). The software draws back and forth between the two back buffers and (at best) once every refresh the front buffer is swapped for the back buffer containing the most recently completed fully rendered frame. This does take up some extra space in memory on the graphics card (about 15 to 25MB), but with modern graphics card dropping at least 512MB on board this extra space is no longer a real issue.
In other words, with triple buffering we get almost the exact same high actual performance and similar decreased input lag of a V-sync disabled setup while achieving the visual quality and smoothness of leaving V-sync enabled.
Note however that the software is still drawing the entire time behind the scenes on the two back buffers when triple buffering. This means that when the front buffer swap happens, unlike with double buffering and V-sync, we don't have artificial delay. And unlike with double buffering without V-sync, once we start sending a fully rendered frame to the monitor, we don't switch to another frame in the middle.
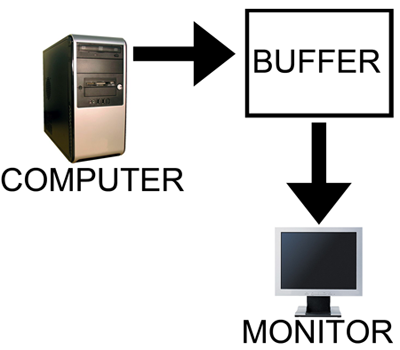
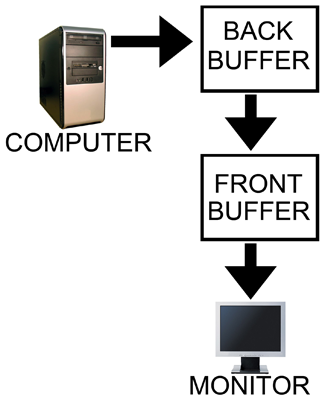
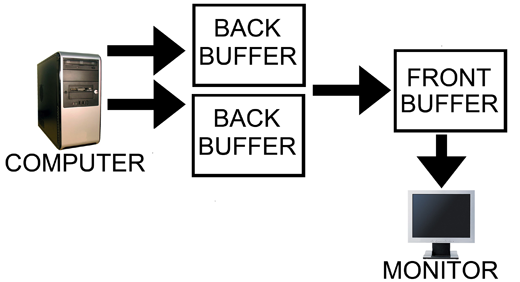

The end result of Fast Sync is that in the right cases we can have our cake and eat it too when it comes to v-sync and input lag. By constantly rendering frames as if v-sync was off, and then just grabbing the most recent frame and discarding the rest, Fast Sync means that v-sync can still be used to prevent tearing without the traditionally high input lag penalty it causes.
The actual input lag benefits will in turn depend on several factors, including frame rates and display refresh rates. The minimum input lag is still the amount of time it takes to draw a frame – just like with v-sync off – and then you have to wait for the next refresh interval to actually display the frame. Thanks to the law of averages, the higher the frame rate (the lower the frame rendering time), the better the odds that a frame is ready right before a screen refresh, reducing the average amount of input lag. This is especially true on 60Hz displays where there’s a full 16.7ms between frame draws and a traditional double buffered setup (or sequential frame queue).
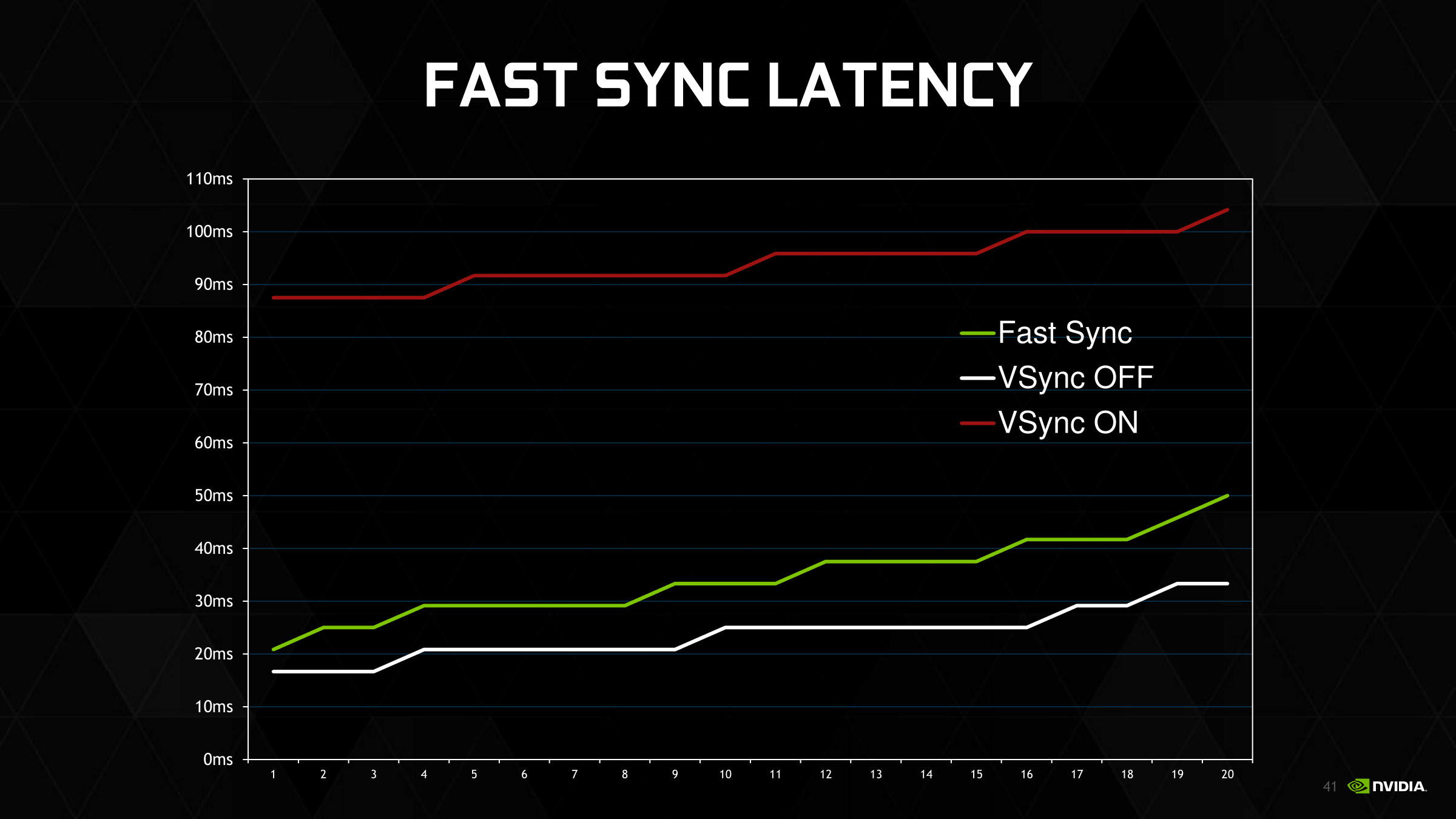
NVIDIA’s own example numbers are taken from monitoring CS:GO with a high speed camera. I can’t confirm these numbers – and as with most marketing efforts it’s like a best-case scenario – but their chart isn’t unreasonable, especially if their v-sync example uses a 3-deep buffer. Input lag will be higher than without v-sync, but lower (potentially much so) than with v-sync on. Overall the greatest benefits are with a very high framerate, which is why NVIDIA is specifically targeting games like CS:GO, as a frame rate multiple times higher than the refresh rate will produce the best results.
With all of the above said, I should note that Fast Sync is purely about input lag and doesn’t address smoothness. In fact it may make things a little less smooth because it’s essentially dropping frames, and the amount of simulation time between frames can vary. But at high framerates this shouldn’t be an issue. Meanwhile Fast Sync means losing all of the power saving benefits of v-sync; rather than the GPU getting a chance to rest and clock down between frames, it’s now rendering at full speed the entire time as if v-sync was off.
Finally, it’s probably useful to clarify how Fast Sync fits in with NVIDIA’s other input lag reduction technologies. Fast Sync doesn’t replace either Adaptive V-Sync or G-Sync, but rather compliments them.
- Adaptive V-Sync: reducing input lag when framerates are below the refresh rate by selectively disabling v-sync
- G-Sync: reducing input lag by refreshing the screen when a frame is ready, up to the display’s maximum refresh rate
- Fast Sync: reducing input lag by not stalling the GPU when the framerate hits the display’s refresh rate
Fast Sync specifically deals with the case where frame rates exceed the display’s refresh rate. If the frame rate is below the refresh rate, then Fast Sync does nothing since it takes more than a refresh interval to render a single frame to begin with. And this is instead where Adaptive Sync would come in, if desired.
Meanwhile when coupled with G-Sync, Fast Sync again only matters when the frame rate exceeds the display’s maximum refresh rate. For most G-Sync monitors this is 120-144Hz. Previously the options with G-Sync above the max refresh rate were to tear (no v-sync) or to stall the GPU (v-sync), so this provides a tear-free lower input lag option for G-Sync as well.








200 Comments
View All Comments
grrrgrrr - Wednesday, July 20, 2016 - link
Solid review! Some nice architecture introductions.euskalzabe - Wednesday, July 20, 2016 - link
The HDR discussion of this review was super interesting, but as always, there's one key piece of information missing: WHEN are we going to see HDR monitors that take advantage of these new GPU abilities?I myself am stuck at 1080p IPS because more resolution doesn't entice me, and there's nothing better than IPS. I'm waiting for HDR to buy my next monitor, but being 5 years old my Dell ST2220T is getting long in the teeth...
ajlueke - Wednesday, July 20, 2016 - link
Thanks for the review Ryan,I think the results are quite interesting, and the games chosen really help show the advantages and limitations of the different architectures. When you compare the GTX 1080 to its price predecessor, the 980 Ti, you are getting an almost universal ~25%-30% increase in performance.
Against rival AMDs R9 Fury X, there is more of a mixed bag. As the resolutions increase the bandwidth provided by the HBM memory on the Fury X really narrows the gap, sometimes trimming the margin to less that 10%,s specifically in games optimized more for DX12 "Hitman, "AotS". But it other games, specifically "Rise of the Tomb Raider" which boasts extremely high res textures, the 4Gb memory size on the Fury X starts to limit its performance in a big way. On average, there is again a ~25%-30% performance increase with much higher game to game variability.
This data lets a little bit of air out of the argument I hear a lot that AMD makes more "future proof" cards. While many Nvidia 900 series users may have to upgrade as more and more games switch to DX12 based programming. AMD Fury users will be in the same boat as those same games come with higher and higher res textures, due to the smaller amount of memory on board.
While Pascal still doesn't show the jump in DX12 versus DX11 that AMD's GPUs enjoy, it does at least show an increase or at least remain at parity.
So what you have is a card that wins in every single game tested, at every resolution over the price predecessors from both companies, all while consuming less power. That is a win pretty much any way you slice it. But there are elements of Nvidia’s strategy and the card I personally find disappointing.
I understand Nvidia wants to keep features specific to the higher margin professional cards, but avoiding HBM2 altogether in the consumer space seems to be a missed opportunity. I am a huge fan of the mini ITX gaming machines. And the Fury Nano, at the $450 price point is a great card. With an NVMe motherboard and NAS storage the need for drive bays in the case is eliminated, the Fury Nano at only 6” leads to some great forward thinking, and tiny designs. I was hoping to see an explosion of cases that cut out the need for supporting 10-11” cards and tons of drive bays if both Nvidia and AMD put out GPUs in the Nano space, but it seems not to be. HBM2 seems destined to remain on professional cards, as Nvidia won’t take the risk of adding it to a consumer Titan or GTX 1080 Ti card and potentially again cannibalize the higher margin professional card market. Now case makers don’t really have the same incentive to build smaller cases if the Fury Nano will still be the only card at that size. It’s just unfortunate that it had to happen because NVidia decided HBM2 was something they could slap on a pro card and sell for thousands extra.
But also what is also disappointing about Pascal stems from the GTX 1080 vs GTX 1070 data Ryan has shown. The GTX 1070 drops off far more than one would expect based off CUDA core numbers as the resolution increases. The GDDR5 memory versus the GDDR5X is probably at fault here, leading me to believe that Pascal can gain even further if the memory bandwidth is increased more, again with HBM2. So not only does the card limit you to the current mini-ITX monstrosities (I’m looking at you bulldog) by avoiding HBM2, it also very likely is costing us performance.
Now for the rank speculation. The data does present some interesting scenarios for the future. With the Fury X able to approach the GTX 1080 at high resolutions, most specifically in DX12 optimized games. It seems extremely likely that the Vega GPU will be able to surpass the GTX 1080, especially if the greatest limitation (4 Gb HBM) is removed with the supposed 8Gb of HBM2 and games move more and more the DX12. I imagine when it launches it will be the 4K card to get, as the Fury X already acquits itself very well there. For me personally, I will have to wait for the Vega Nano to realize my Mini-ITX dreams, unless of course, AMD doesn’t make another Nano edition card and the dream is dead. A possibility I dare not think about.
eddman - Wednesday, July 20, 2016 - link
The gap getting narrower at higher resolutions probably has more to do with chips' designs rather than bandwidth. After all, Fury is the big GCN chip optimized for high resolutions. Even though GP104 does well, it's still the middle Pascal chip.P.S. Please separate the paragraphs. It's a pain, reading your comment.
Eidigean - Wednesday, July 20, 2016 - link
The GTX 1070 is really just a way for Nvidia to sell GP104's that didn't pass all of their tests. Don't expect them to put expensive memory on a card where they're only looking to make their money back. Keeping the card cost down, hoping it sells, is more important to them.If there's a defect anywhere within one of the GPC's, the entire GPC is disabled and the chip is sold at a discount instead of being thrown out. I would not buy a 1070 which is really just a crippled 1080.
I'll be buying a 1080 for my 2560x1600 desktop, and an EVGA 1060 for my Mini-ITX build; which has a limited power supply.
mikael.skytter - Wednesday, July 20, 2016 - link
Thanks Ryan! Much appreciated.chrisp_6@yahoo.com - Wednesday, July 20, 2016 - link
Very good review. One minor comment to the article writers - do a final check on grammer - granted we are technical folks, but it was noticeable especially on the final words page.madwolfa - Wednesday, July 20, 2016 - link
It's "grammar", though. :)Eden-K121D - Thursday, July 21, 2016 - link
Oh the ironychrisp_6@yahoo.com - Thursday, July 21, 2016 - link
oh snap, that is some funny stuff right there