Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
Soft Machines
To put it succinctly, having a thread take resources from multiple cores - when the performance can be extracted - sounds like the long-desired solution to the problem making multi-core designs more useful in lightly-threaded scenarios. Having multiple threads use resources on a single core on the same clock cycle is an even bigger leap in the same direction. Now obviously Soft Machines didn’t come up with this overnight.

Soft Machines came out of stealth mode at the 2014 Linley Conference. Their main goal was to increase performance-per-watt using better IPC designs, which is often one of the better ways if you can keep a design fed with data. One big challenge to this is that IPC has been somewhat flat these past few years - we're seeing small sub-10% yearly increases from the big players using standard designs. Soft Machines were already six years old at the time, with $150M+ raised from investors that include Samsung Ventures, GlobalFoundries, AMD, Mubadala and others (with another $25M since). If those names all seem interlinked, it’s because they all have historic business or investment dealings with each other (AMD/GloFo, Samsung/GloFo, AMD/Mubadala etc.). The team at Soft Machines is 250+ strong, with ex Intel, ex Qualcomm, ex AMD engineers on staff from processor design to platform architects. Half the staff is currently located in California.
At the 2014 conference, aside from explaining what they were doing, Soft Machines also exhibited working silicon of their design. The first generation proof of concept was fabbed at 28nm at TSMC and running at 500 MHz.

It seems odd to say that it was done at TSMC, especially with Samsung and Global Foundries as investors. We were told that this was due to timing and positioning with IP more than anything else, and the same is true for the next generation at 16nm FF+, rather than 14nm.
VISC and Roadmaps
The first generation chip wasn’t perfect – there were some design flaws in silicon that required specific workarounds relating to cache flushing and various methods, but at the time it was compared to a single thread Cortex A15 running at a similar frequency in a Samsung processor. The results with SPEC2000, SPEC2006, Denbench and Kraken gave a corresponding IPC relative to A15 of 1.5x to 7x, or as Soft Machines likes to put it: 3-4x "on average." It was estimated that access to a second physical core improves performance by an average of 50-60%, or an average IPC of 1.3 per core compared to 0.71 for Cortex A15, which explains the 3-4x average.
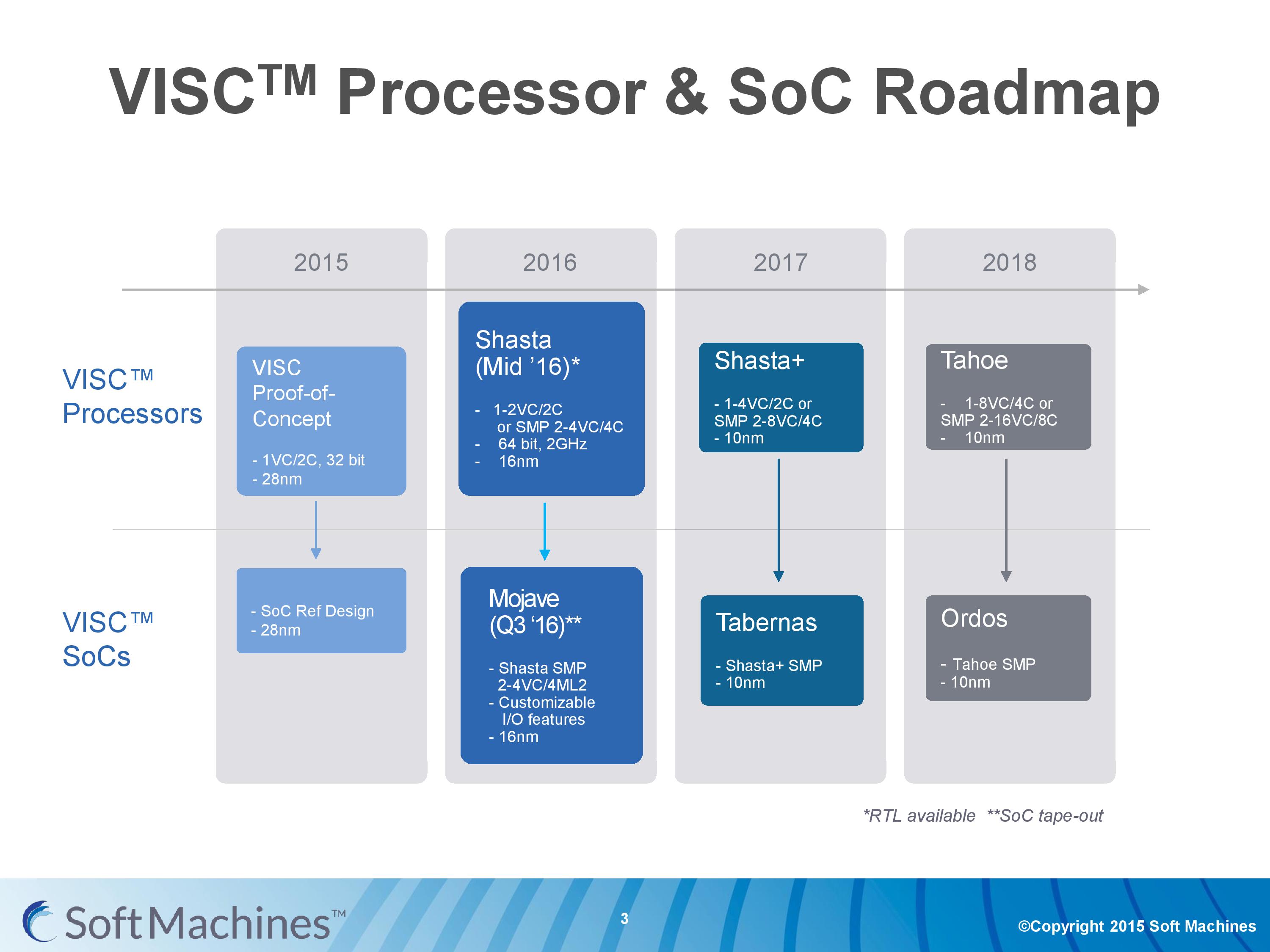
The roadmap for Soft Machines put their second generation VISC core, Shasta, in line for 2016. It was formally announced at the 2015 Linley Conference, with this month’s announcement being more about availability for licensing on 16FF+. The Shasta core on this node is designed as a 2C/2VC design, or two of these can be put together using a custom protocol interconnect to form a dual 2C/2VC design.
The custom interconnect fabric here is capable of over 200 GB/s, although in current designs only a single interface is present, allowing only two chips to be connected.
The dual processor design is going to be part of the Mojave IP as a fully integrated SoC.
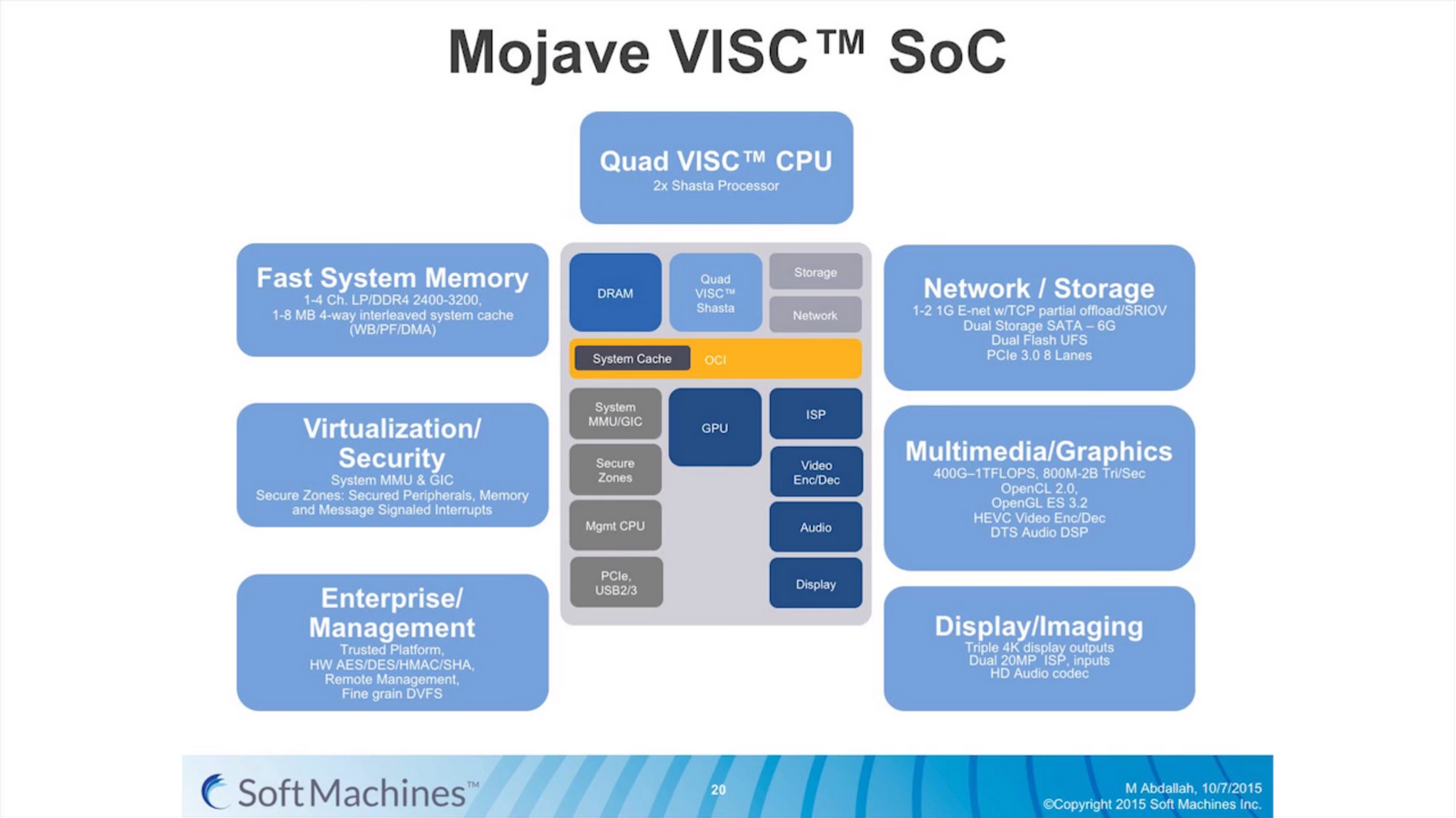
Along with the requisite VISC cores, the Mojave SoC includes PowerVR graphics, a DDR4 memory controller, virtualization management, a PCIe root complex capable of eight lanes of PCIe 3.0, USB ports, support for SATA, UFS, OpenCL 2.0 and other standards.
Looking forward, Soft Machines would like to see production move to 10nm in 2017 to take advantage of further power and area scaling. Meanwhile along that same timeframe they also want to expand the Shasta design to allow for four virtual cores per two physical cores, essentially allowing more threads to be in flight at one time and fully use the resources better. 2018 sees the move to four physical cores and eight virtual cores per design, while still supporting SMP and SoC designs as well.








97 Comments
View All Comments
kgardas - Saturday, February 13, 2016 - link
Market is not dominated by excellent technology, but by average or mediocre in fact. "Good enough" is enemy of any excellence.Also in comparison with AMD64 which is just pile of hacks to prolong x86 architecture life, IA-64 was clean design on green field and its really a pity Intel can't push that further -- also due to AMD64 existence in the market.
Alexvrb - Monday, February 15, 2016 - link
That kind of thinking is what lead to the Itanic, the unsinkable chip. Too bad they ran afoul of a giant costberg.But no, you're right, everyone should switch to a new ISA because Intel says it's better, even though it means switching to an Intel-exclusive ISA that will cost you dearly now, and even more dearly later when you become dependent on a product that only Intel can produce.
If Intel's only desire was a better design for everyone, they would have worked with AMD and freely extended licensing agreements to IA-64 to them so they could both produce IA-64 chips. The outcome could have very well been different in that scenario. But that is not what they did, and they paid for it. Of course, Intel is such a giant that they can afford to take such failures in stride. AMD can not afford another flop - Zen, Polaris, and eventually a ZenPolaris APU have to achieve at least a significant degree of success.
FunBunny2 - Monday, February 15, 2016 - link
-- Of course, Intel is such a giant that they can afford to take such failures in stride.the irony, of course, is that Intel got where it is just because, in ~1980, Intel had one foot in chapter 7 and one foot on a banana peel. IOW, an easy controlled peon for IBM to abuse, thus the 8088 came to be. if IBM had secured the BIOS, life for both would have turned out rather differently, I suspect.
Alexvrb - Monday, February 15, 2016 - link
Yeah that is ironic. Intel was trying to avoid making a similar mistake, and in doing so they screwed up - but the SIZE of the failure was tiny in comparison. One thing about Intel is that they have better foresight and planning than IBM. IBM always was caught up in their own world. Intel probably was working on backup plans for Itanium failure before it even launched, regardless of how high they thought its chances were.diediealldie - Friday, February 12, 2016 - link
Thanks for great article.Anyway, I'd wait for actual working silicon with high frequency(Not .5Ghz) to figure out if it's real or not.
Since they're making abstraction layer with real silicon, demonstrating it on slow chip will not enough to convince industry experts(Hardware will be complicated so making it work on very high frequency is also big challenge).
High freqency chips requires more pipeline thus latencies and cache efficiency gets worse, hardware blocks not working...etc. so high frequeny chip is what Shasta really have to demonstrate.
dcbronco - Friday, February 12, 2016 - link
Interesting that AMD are switching to SMT with Zen and are one of the big financers of Soft Machines and VISC works well with SMT. I also wonder if an OS written for VISC would give a boost to APUs or would the bottlenecks kill any advantage.zodiacfml - Saturday, February 13, 2016 - link
Interesting as numerous patents created can be beneficial to other CPU makers but for them creating a compelling chip that could sell would be miraculous.haplo602 - Saturday, February 13, 2016 - link
Lots of marketing and even more estimates and projections. Looks like a very long road ahead to actual working chip with peripherals. And a lot of obstacles still to clear.While the idea is interesting, it is highly impractical. The higher frequency they'll go, the more the final compositing overhead will bite them. There's a cost traversing the layers of the design from thread to CPU and back with results. I do not see that explained anywhere.
Another point is, I think this is not a new idea. It is fairly obvious an extension so expect Intel already went that route and met a dead-end.
vladx - Sunday, February 14, 2016 - link
Intel are too conservative to come with such ideas, they'd rather milk the cow as long as possible.hMunster - Sunday, February 14, 2016 - link
There's one important question I don't see addressed, how do you run at higher IPCs when you have a conditional branch every few instructions? A 16-wide virtual CPU using 4 physical cores is all nice and dandy, but 16 instructions will, in normal x85 code, contain at least 2 branches. I can't see them doing a lot of speculative execution because that drives up the power consumption. So how do they solve this?