Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
Dealing with Guest ISAs and a Translation Layer
Going back to this architecture diagram, everything up to the global front end is another interesting story as well.
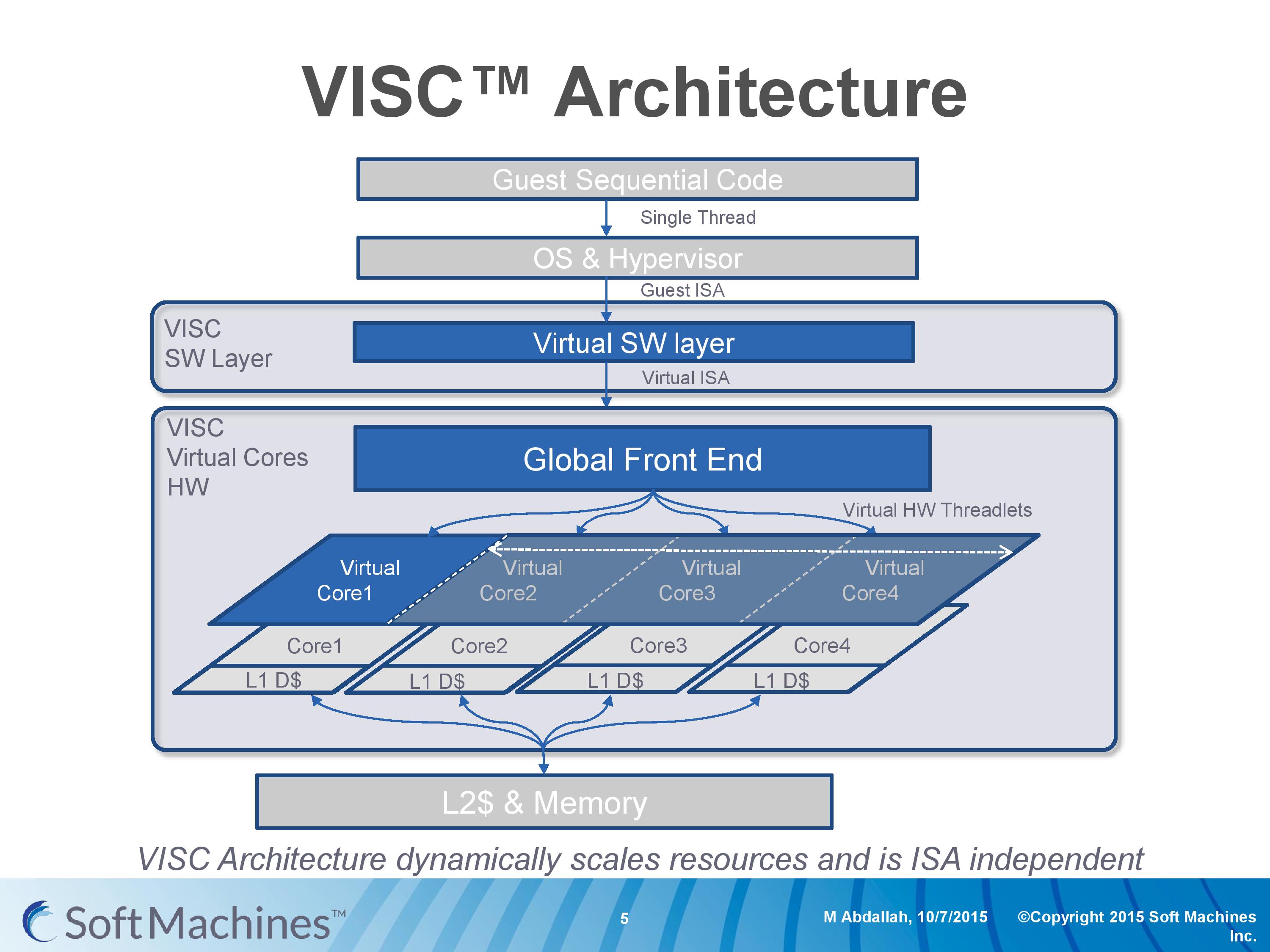
Part of Soft Machines' product package is a low level virtual software layer that will translate a guest instruction set and convert it into the VISC ISA. This is to allow VISC to be used with existing software, and to more easily integrate into current environments rather than trying to establish an ecosystem for a new architecture in 2016. Soft Machines tells us that two instruction sets are supported, one of which will be ARMv8. It was implied that x86 would be the other, although they were reluctant to outright confirm it (ed: x86 translation is likely not to be looked upon fondly by Intel). Meanwhile we were told that writing additional translation layers, while not trivial, can be done and that they plan to support other guest ISAs in future.
So for all intents and purposes, this is a translation layer converting from ARMv8 to VISC. Many companies over the past couple of decades have tried with translation layers – Intel with Itanium, Transmeta to x86, and one of the latest was NVIDIA with Denver, which translated ARM to a custom ISA. Mentioning Itanium, Transmeta and Denver, for those who have followed the industry, might bring a chill down the spine given the very limited success each of these platforms have had. Soft Machines’ CEO was keen to point out that the purpose of the translation layer for VISC is very different to these previous attempts.
The VISC translation layer is designed to be a thin and lean implementation whose main role is to maintain compatibility to the VISC ISA, not to extract performance. Taking Denver as the most recent example, the translation layer there is designed to adjust the ARM instructions into Denver’s ISA and extract instruction level parallelism into the 7-wide design. For VISC, we are told, there is no need to go after performance at this level. The main point at which the VISC design increases performance is at threadlet generation, not in translation and making instruction sequences better fit the VISC hardware. This allows the ARM translation layer to have a less than 5% overhead, according to Soft Machines, and releases a point of contention with previous translation layer designs. As long as the translation layer is 100% compatible, the performance can in principle be extracted at the threadlet level.
This also means, again according to Soft Machines, that any specific compiler enhancement offered by others can also be used when translated. We put it to them that in the case of x86 certain codes are accelerated better on Intel’s compiler than say GCC (a question that arose out of the results we’ll go into later), and we were told that those instruction enhancements by ICC should translate well into the VISC ISA after going through the translation layer.
We asked about the VISC ISA, but were told that more information about this and the core design would be released at a later date as designs progress. We were told that it is a relatively small ISA (as to us sounds like a RISC, which is easier to extract ILP at lower power) with smaller instructions in comparison to ARM and x86. I would assume that this means they are fixed length, but this was not confirmed.








97 Comments
View All Comments
kgardas - Saturday, February 13, 2016 - link
Market is not dominated by excellent technology, but by average or mediocre in fact. "Good enough" is enemy of any excellence.Also in comparison with AMD64 which is just pile of hacks to prolong x86 architecture life, IA-64 was clean design on green field and its really a pity Intel can't push that further -- also due to AMD64 existence in the market.
Alexvrb - Monday, February 15, 2016 - link
That kind of thinking is what lead to the Itanic, the unsinkable chip. Too bad they ran afoul of a giant costberg.But no, you're right, everyone should switch to a new ISA because Intel says it's better, even though it means switching to an Intel-exclusive ISA that will cost you dearly now, and even more dearly later when you become dependent on a product that only Intel can produce.
If Intel's only desire was a better design for everyone, they would have worked with AMD and freely extended licensing agreements to IA-64 to them so they could both produce IA-64 chips. The outcome could have very well been different in that scenario. But that is not what they did, and they paid for it. Of course, Intel is such a giant that they can afford to take such failures in stride. AMD can not afford another flop - Zen, Polaris, and eventually a ZenPolaris APU have to achieve at least a significant degree of success.
FunBunny2 - Monday, February 15, 2016 - link
-- Of course, Intel is such a giant that they can afford to take such failures in stride.the irony, of course, is that Intel got where it is just because, in ~1980, Intel had one foot in chapter 7 and one foot on a banana peel. IOW, an easy controlled peon for IBM to abuse, thus the 8088 came to be. if IBM had secured the BIOS, life for both would have turned out rather differently, I suspect.
Alexvrb - Monday, February 15, 2016 - link
Yeah that is ironic. Intel was trying to avoid making a similar mistake, and in doing so they screwed up - but the SIZE of the failure was tiny in comparison. One thing about Intel is that they have better foresight and planning than IBM. IBM always was caught up in their own world. Intel probably was working on backup plans for Itanium failure before it even launched, regardless of how high they thought its chances were.diediealldie - Friday, February 12, 2016 - link
Thanks for great article.Anyway, I'd wait for actual working silicon with high frequency(Not .5Ghz) to figure out if it's real or not.
Since they're making abstraction layer with real silicon, demonstrating it on slow chip will not enough to convince industry experts(Hardware will be complicated so making it work on very high frequency is also big challenge).
High freqency chips requires more pipeline thus latencies and cache efficiency gets worse, hardware blocks not working...etc. so high frequeny chip is what Shasta really have to demonstrate.
dcbronco - Friday, February 12, 2016 - link
Interesting that AMD are switching to SMT with Zen and are one of the big financers of Soft Machines and VISC works well with SMT. I also wonder if an OS written for VISC would give a boost to APUs or would the bottlenecks kill any advantage.zodiacfml - Saturday, February 13, 2016 - link
Interesting as numerous patents created can be beneficial to other CPU makers but for them creating a compelling chip that could sell would be miraculous.haplo602 - Saturday, February 13, 2016 - link
Lots of marketing and even more estimates and projections. Looks like a very long road ahead to actual working chip with peripherals. And a lot of obstacles still to clear.While the idea is interesting, it is highly impractical. The higher frequency they'll go, the more the final compositing overhead will bite them. There's a cost traversing the layers of the design from thread to CPU and back with results. I do not see that explained anywhere.
Another point is, I think this is not a new idea. It is fairly obvious an extension so expect Intel already went that route and met a dead-end.
vladx - Sunday, February 14, 2016 - link
Intel are too conservative to come with such ideas, they'd rather milk the cow as long as possible.hMunster - Sunday, February 14, 2016 - link
There's one important question I don't see addressed, how do you run at higher IPCs when you have a conditional branch every few instructions? A 16-wide virtual CPU using 4 physical cores is all nice and dandy, but 16 instructions will, in normal x85 code, contain at least 2 branches. I can't see them doing a lot of speculative execution because that drives up the power consumption. So how do they solve this?