Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
Dealing with Guest ISAs and a Translation Layer
Going back to this architecture diagram, everything up to the global front end is another interesting story as well.
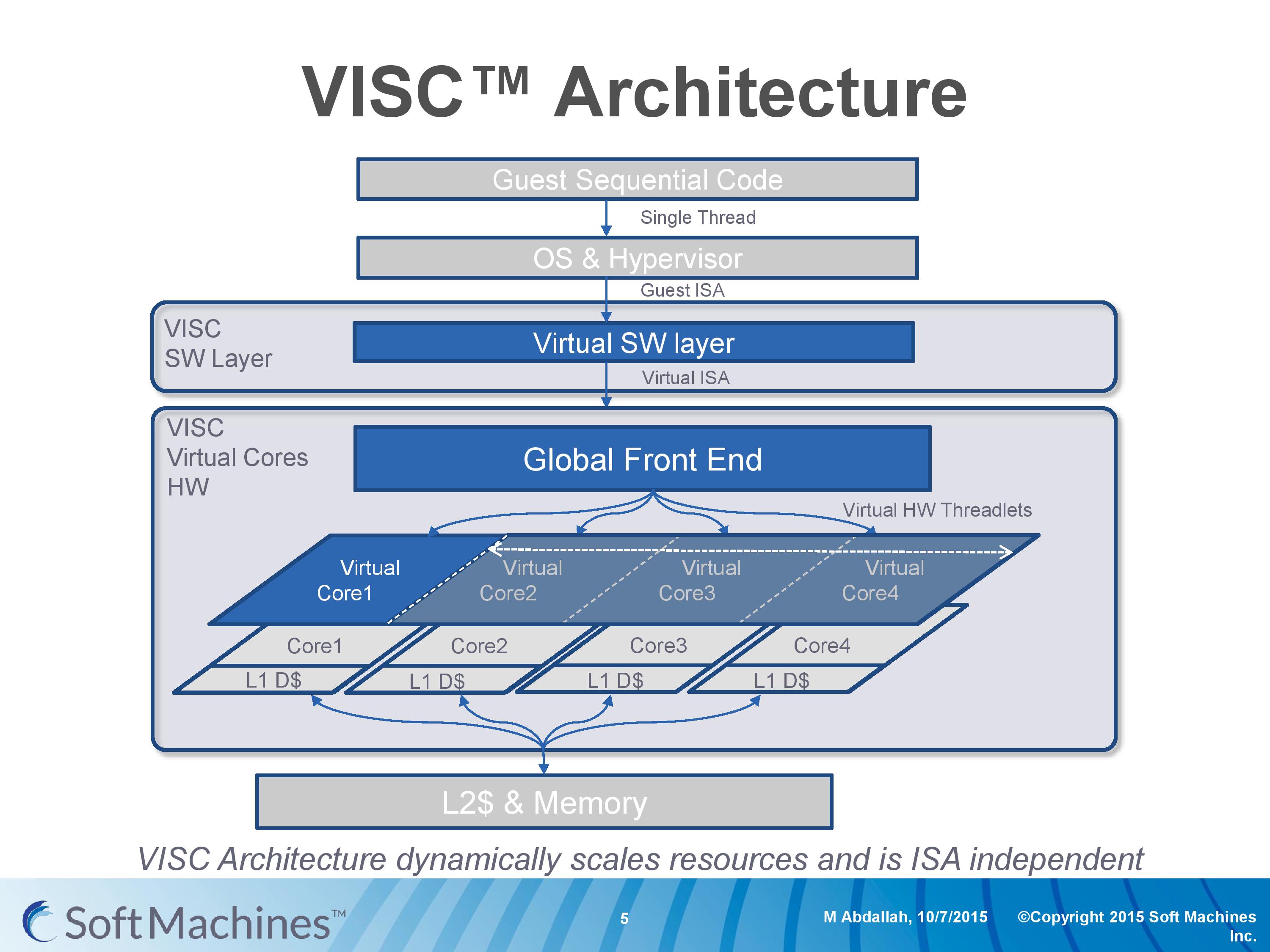
Part of Soft Machines' product package is a low level virtual software layer that will translate a guest instruction set and convert it into the VISC ISA. This is to allow VISC to be used with existing software, and to more easily integrate into current environments rather than trying to establish an ecosystem for a new architecture in 2016. Soft Machines tells us that two instruction sets are supported, one of which will be ARMv8. It was implied that x86 would be the other, although they were reluctant to outright confirm it (ed: x86 translation is likely not to be looked upon fondly by Intel). Meanwhile we were told that writing additional translation layers, while not trivial, can be done and that they plan to support other guest ISAs in future.
So for all intents and purposes, this is a translation layer converting from ARMv8 to VISC. Many companies over the past couple of decades have tried with translation layers – Intel with Itanium, Transmeta to x86, and one of the latest was NVIDIA with Denver, which translated ARM to a custom ISA. Mentioning Itanium, Transmeta and Denver, for those who have followed the industry, might bring a chill down the spine given the very limited success each of these platforms have had. Soft Machines’ CEO was keen to point out that the purpose of the translation layer for VISC is very different to these previous attempts.
The VISC translation layer is designed to be a thin and lean implementation whose main role is to maintain compatibility to the VISC ISA, not to extract performance. Taking Denver as the most recent example, the translation layer there is designed to adjust the ARM instructions into Denver’s ISA and extract instruction level parallelism into the 7-wide design. For VISC, we are told, there is no need to go after performance at this level. The main point at which the VISC design increases performance is at threadlet generation, not in translation and making instruction sequences better fit the VISC hardware. This allows the ARM translation layer to have a less than 5% overhead, according to Soft Machines, and releases a point of contention with previous translation layer designs. As long as the translation layer is 100% compatible, the performance can in principle be extracted at the threadlet level.
This also means, again according to Soft Machines, that any specific compiler enhancement offered by others can also be used when translated. We put it to them that in the case of x86 certain codes are accelerated better on Intel’s compiler than say GCC (a question that arose out of the results we’ll go into later), and we were told that those instruction enhancements by ICC should translate well into the VISC ISA after going through the translation layer.
We asked about the VISC ISA, but were told that more information about this and the core design would be released at a later date as designs progress. We were told that it is a relatively small ISA (as to us sounds like a RISC, which is easier to extract ILP at lower power) with smaller instructions in comparison to ARM and x86. I would assume that this means they are fixed length, but this was not confirmed.








97 Comments
View All Comments
xdrol - Saturday, February 13, 2016 - link
The Cruzoe was (and Denver is) a VLIW design, it needed software translation to run *anything*, telling what pipeline ports to schedule (a hard optimization problem). Here the translation is supposedly just an ARMv8 to internal ISA mapping, scheduling is still done by hardware like with a normal superscalar design.Jtaylor1986 - Friday, February 12, 2016 - link
Excellent article Ian. Thanksjjj - Friday, February 12, 2016 - link
1 more thing.Any clue about thermal management? Can they turn off individual physical cores or they just lower clocks? Being able to do both would be interesting.
matt321 - Friday, February 12, 2016 - link
This would make sense for someone like Apple to buy/invest/license the technology for their own processor development. They could have common cores with translations for both ARM and x86 (for iOS and OS X respectively) with the long-term goal of migrating completely to VISC ISA.extide - Friday, February 12, 2016 - link
This is interesting, because I have thought of doing a processor design somewhat like this for a long time. Remember when BD was coming out, there were rumors of "reverse Hyperthreading" well this is kinda that.I had thought that someone should make a suuuper wide cpu, like 20 or 30 wide, put TONS of execution resources on it, and then put a bunch of hyperthreads. That way a single thread could use all 20-30 execution resources, if possible, or you could have multiple threads sharing all that. Like instead of a quad core, with 2 threads/core have like a super core with 8+ threads, and then maybe a couple of those.
extide - Friday, February 12, 2016 - link
Although, I had always thought that engineers had thought of this already, and that maybe it was a bad idea due to some reason I don't understand, and that's why we haven't ever seen a design like that. Well, this is pretty similar to my idea, except they aren't making a super core, they are allowing a thread to use resources from several cores, if it needs.Exophase - Friday, February 12, 2016 - link
The problem is that going wider decreases efficiency and slows down critical paths. So the processor that's N * 2 wide will have to be a lot slower and/or less efficient than the one that's N wide. If software can rarely extract enough parallelism to go beyond N wide then the N * 2 wide version will almost always be worse. There's a good balance point to be found here.Some components in the CPU even scale worse than linearly as they increase in width. The wiring can increase quadratically or even exponentially.
In practice, a lot of the code that you could realistically extract a ton of ILP from is the type of code that's easiest to vectorize or thread (and a lot of vector + thread friendly can run well on GPUs). What remains, outside of some benchmarks anyway, is mostly a lot of code that has fairly limited ILP due to eventually hitting mispredicted branches or from very long dependency chains. Branch mispredictions are particularly bad on a CPU that has a ton of instructions in flight due to being very wide because that much more energy is wasted on failed speculation.
Oxford Guy - Friday, February 12, 2016 - link
So why wasn't Prescott really great (narrow and deep) versus the G5 (very wide and shallow)?Exophase - Saturday, February 13, 2016 - link
It's like I said, "there's a good balance point to be found here."Faster clocks need higher voltage which scales super-linearly with power consumption. They require longer pipelines which have worse branch misprediction penalties. They take more cycles to talk to other components that don't scale with CPU clock like RAM. More transistors (more space, power) are thrown at these things to try to compensate, like better branch predictors and more reordering, more aggressive prefetching, etc.
So there's a balancing act between two extremes and what makes the most sense will depend on the manufacturing process, target market and various other things.
G5 was actually not very wide and shallow anyway. It was a 2.7GHz processor in 2003 and was supposed to hit 3GHz. It had a 16-21 stage pipeline with up to > 200 instructions in flight. That's not shallow at all. 4 wide decode with 2x ALU + 2x L/S is not really that wide either.
AlexTi - Friday, February 12, 2016 - link
If algorithm is developed which can split current single-threaded code into "threadlets", which can be run in parallel, why can't it be used in compilers to make multi-threaded code to run on existing architecture? Especially in enviroments which use JIT?