Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
Soft Machines
To put it succinctly, having a thread take resources from multiple cores - when the performance can be extracted - sounds like the long-desired solution to the problem making multi-core designs more useful in lightly-threaded scenarios. Having multiple threads use resources on a single core on the same clock cycle is an even bigger leap in the same direction. Now obviously Soft Machines didn’t come up with this overnight.

Soft Machines came out of stealth mode at the 2014 Linley Conference. Their main goal was to increase performance-per-watt using better IPC designs, which is often one of the better ways if you can keep a design fed with data. One big challenge to this is that IPC has been somewhat flat these past few years - we're seeing small sub-10% yearly increases from the big players using standard designs. Soft Machines were already six years old at the time, with $150M+ raised from investors that include Samsung Ventures, GlobalFoundries, AMD, Mubadala and others (with another $25M since). If those names all seem interlinked, it’s because they all have historic business or investment dealings with each other (AMD/GloFo, Samsung/GloFo, AMD/Mubadala etc.). The team at Soft Machines is 250+ strong, with ex Intel, ex Qualcomm, ex AMD engineers on staff from processor design to platform architects. Half the staff is currently located in California.
At the 2014 conference, aside from explaining what they were doing, Soft Machines also exhibited working silicon of their design. The first generation proof of concept was fabbed at 28nm at TSMC and running at 500 MHz.

It seems odd to say that it was done at TSMC, especially with Samsung and Global Foundries as investors. We were told that this was due to timing and positioning with IP more than anything else, and the same is true for the next generation at 16nm FF+, rather than 14nm.
VISC and Roadmaps
The first generation chip wasn’t perfect – there were some design flaws in silicon that required specific workarounds relating to cache flushing and various methods, but at the time it was compared to a single thread Cortex A15 running at a similar frequency in a Samsung processor. The results with SPEC2000, SPEC2006, Denbench and Kraken gave a corresponding IPC relative to A15 of 1.5x to 7x, or as Soft Machines likes to put it: 3-4x "on average." It was estimated that access to a second physical core improves performance by an average of 50-60%, or an average IPC of 1.3 per core compared to 0.71 for Cortex A15, which explains the 3-4x average.
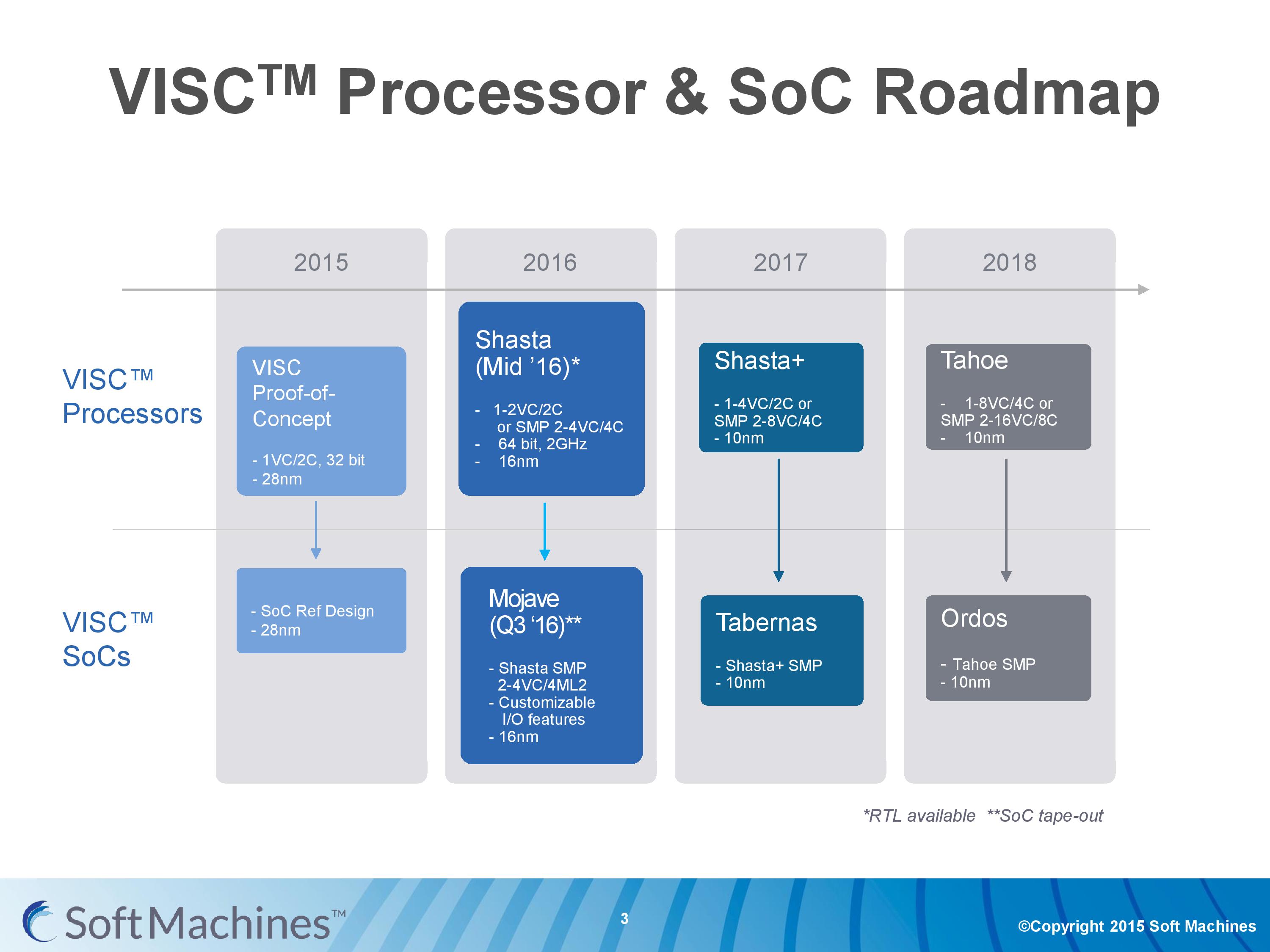
The roadmap for Soft Machines put their second generation VISC core, Shasta, in line for 2016. It was formally announced at the 2015 Linley Conference, with this month’s announcement being more about availability for licensing on 16FF+. The Shasta core on this node is designed as a 2C/2VC design, or two of these can be put together using a custom protocol interconnect to form a dual 2C/2VC design.
The custom interconnect fabric here is capable of over 200 GB/s, although in current designs only a single interface is present, allowing only two chips to be connected.
The dual processor design is going to be part of the Mojave IP as a fully integrated SoC.
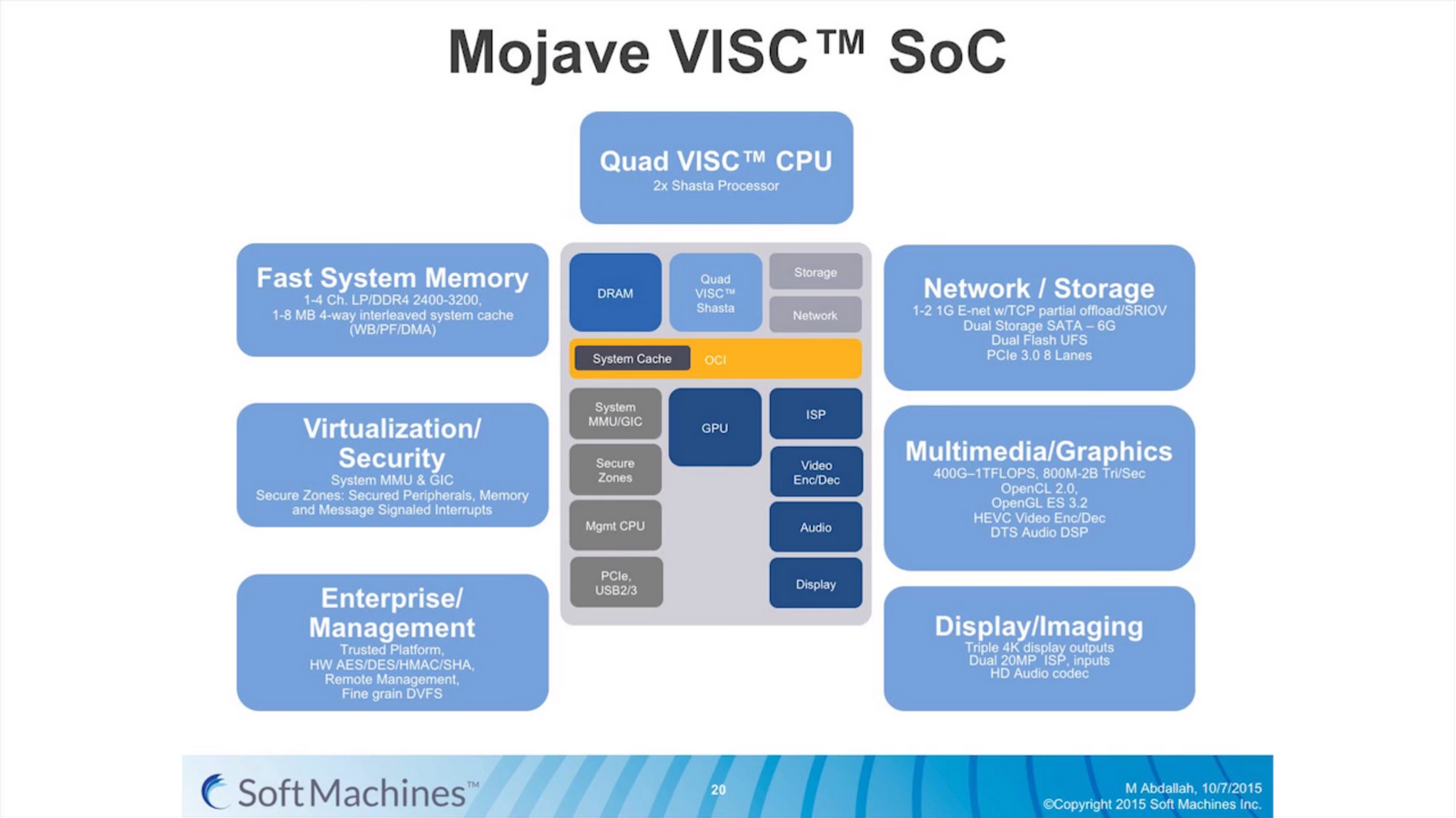
Along with the requisite VISC cores, the Mojave SoC includes PowerVR graphics, a DDR4 memory controller, virtualization management, a PCIe root complex capable of eight lanes of PCIe 3.0, USB ports, support for SATA, UFS, OpenCL 2.0 and other standards.
Looking forward, Soft Machines would like to see production move to 10nm in 2017 to take advantage of further power and area scaling. Meanwhile along that same timeframe they also want to expand the Shasta design to allow for four virtual cores per two physical cores, essentially allowing more threads to be in flight at one time and fully use the resources better. 2018 sees the move to four physical cores and eight virtual cores per design, while still supporting SMP and SoC designs as well.








97 Comments
View All Comments
Bleakwise - Tuesday, March 14, 2017 - link
I mean IBM does this with the POWER8 very successfully.Bleakwise - Tuesday, March 14, 2017 - link
If you would like to know how an Superscaler CPU can beat an in-order CPU....https://en.wikipedia.org/wiki/Instruction-level_pa...
https://en.wikipedia.org/wiki/Superscalar_processo...
https://en.wikipedia.org/wiki/Instruction-level_pa...
So a Processor with 6 pipelines can do
1*2*3*4*5*6 in one instructoin
a processor with 12 piplines can do
1*2*3*4*5*6*7*8*9*10*11*12
in one clock cycle
This is the opposite of hyper threading, which allows my 4770k with 5 pipelines to do
1*2*3*4*5
or
1*2*3 and 4*5
or
1*2 and 3*4*5
all in one clock cycle.
jjj - Friday, February 12, 2016 - link
What they do with A72 in their slides is a huge red flag. They clock it above 3GHz on 16ff to make it look bad. When you don't need to distort the truth why do it? Was excited about them but they lost all credibility with this.vs ARM it will be hard for them ,assuming ARM will have yearly updates and a broader range of cores. Area will also matter a lot Ofc vs ARM the proper math when it comes to perf, power, thermal and area would be to include dark silicon. ARM is at 8-10 cores in 2-3 clusters but we might see even more than that (i would add a gaming cluster, as GPU perf is a rather complicated problem right now).
Hope we do get to see them in commercial products and i wonder about their longer term plans. Would be interesting if they would aim for a lot more cores at very low power and even cooler if they would aim to use different types of cores - as undoable as all that might be lol. For glasses we need a huge step forward that process and packaging might fail to enable soon enough and even server might find such a path preferable. Would love to see 1T 32PC at 50-100mW on 5nm. Or ,to just go crazy, would be great if they could reach low enough power (thermal) to stack logic and go monolithic 3D since folks are not quite able to do that , for now.
Guess , it would be great if you could ask them how far they think they can push with the number of cores in a thread.
gamerk2 - Friday, February 12, 2016 - link
Odds are, Soft Machines gets acquired by Intel (who want a low-power core for mobile. And hey, ARM support to eliminate the lack of mobile X86 software to boot) or NVIDIA (who want a CPU core, and hey, already have ARM based tablets. X86 support is a bonus an could allow full NVIDIA branded PCs).jjj - Friday, February 12, 2016 - link
It would be easier for Intel or ARM to just copy. Additionally, a sale to Intel would be difficult with Samsung and AMD as investors in SM.fiodhkf - Friday, February 12, 2016 - link
I don't understand these results. How are skylake specint and spefp scores so low? On spec.org the weakest skylake part I could quickly find is Celeron G3900 at 2.8 GHz and 2MB L3 (and huge power consumption, but let's ignore that for now). It has CINT2006 of ~45 and CFP2006 of ~61. Can i5-6200U be that much slower?extide - Friday, February 12, 2016 - link
Because those are NOT the results of a skylake chip, those are their adjusted results of a chip that is equivalent to skylake, but with 1MB L2, no L3, and made on TSMC's 16nmFF+, which is a chip that will NEVER exist in the wild and is POINTLESS to compare to as these guys will never be competing against a made up chip, only the actual stuff released by Intel, and other people.fiodhkf - Friday, February 12, 2016 - link
In the second Performance/Watt comparisonfigure the blue curve is supposed to(?) show the true unscaled-for-cache skylake (power is probably scaled to TSMC 16nmFF+, but surely they're not scaling the performance as well). Even there the skylake spec scores are only about half of what they should be according to results on spec.org.Exophase - Friday, February 12, 2016 - link
The spec.org scores are using ICC, which has optimizations that game a few SPEC2006 subtests like crazy. They also apply auto-par and pointer compression optimizations that aren't applied in GCC. There's also some extra optimizations for peak if you're looking at that but it doesn't make a huge difference in the overall score.All of this adds up to big differences in SPEC score.
fiodhkf - Friday, February 12, 2016 - link
Thanks, that was pretty much what I guessed would be one explanation for the difference. Still, I'm a bit surprised with the low skylake scores even when compared to some (old) AMD processors where spec.org scores used open64. But I don't care quite enough to try myself.