Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
Dealing with Guest ISAs and a Translation Layer
Going back to this architecture diagram, everything up to the global front end is another interesting story as well.
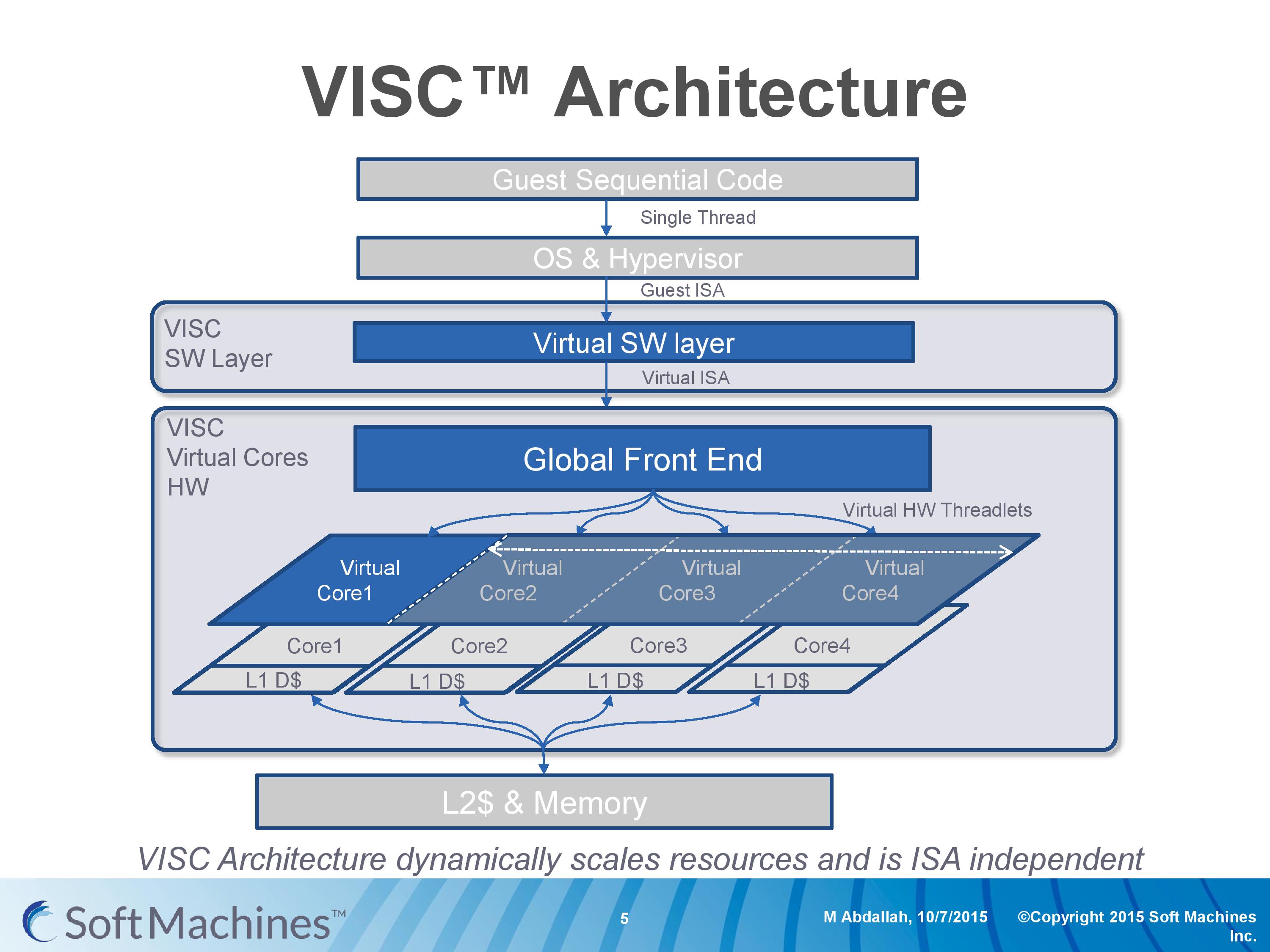
Part of Soft Machines' product package is a low level virtual software layer that will translate a guest instruction set and convert it into the VISC ISA. This is to allow VISC to be used with existing software, and to more easily integrate into current environments rather than trying to establish an ecosystem for a new architecture in 2016. Soft Machines tells us that two instruction sets are supported, one of which will be ARMv8. It was implied that x86 would be the other, although they were reluctant to outright confirm it (ed: x86 translation is likely not to be looked upon fondly by Intel). Meanwhile we were told that writing additional translation layers, while not trivial, can be done and that they plan to support other guest ISAs in future.
So for all intents and purposes, this is a translation layer converting from ARMv8 to VISC. Many companies over the past couple of decades have tried with translation layers – Intel with Itanium, Transmeta to x86, and one of the latest was NVIDIA with Denver, which translated ARM to a custom ISA. Mentioning Itanium, Transmeta and Denver, for those who have followed the industry, might bring a chill down the spine given the very limited success each of these platforms have had. Soft Machines’ CEO was keen to point out that the purpose of the translation layer for VISC is very different to these previous attempts.
The VISC translation layer is designed to be a thin and lean implementation whose main role is to maintain compatibility to the VISC ISA, not to extract performance. Taking Denver as the most recent example, the translation layer there is designed to adjust the ARM instructions into Denver’s ISA and extract instruction level parallelism into the 7-wide design. For VISC, we are told, there is no need to go after performance at this level. The main point at which the VISC design increases performance is at threadlet generation, not in translation and making instruction sequences better fit the VISC hardware. This allows the ARM translation layer to have a less than 5% overhead, according to Soft Machines, and releases a point of contention with previous translation layer designs. As long as the translation layer is 100% compatible, the performance can in principle be extracted at the threadlet level.
This also means, again according to Soft Machines, that any specific compiler enhancement offered by others can also be used when translated. We put it to them that in the case of x86 certain codes are accelerated better on Intel’s compiler than say GCC (a question that arose out of the results we’ll go into later), and we were told that those instruction enhancements by ICC should translate well into the VISC ISA after going through the translation layer.
We asked about the VISC ISA, but were told that more information about this and the core design would be released at a later date as designs progress. We were told that it is a relatively small ISA (as to us sounds like a RISC, which is easier to extract ILP at lower power) with smaller instructions in comparison to ARM and x86. I would assume that this means they are fixed length, but this was not confirmed.








97 Comments
View All Comments
KAlmquist - Sunday, February 14, 2016 - link
If I understand the article correctly, the difference between VISC and SMT is that in SMT there is a single scheduler which manages all of the execution units. VISC implements a two stage scheduling algorithm. In the first stage, an operation is assigned to a core. In the second stage, the scheduler for that core assigns the operation to an execution unit.The downside of SMT is that the amount of silicon required to implement the scheduler grows faster than the number of execution units. So as you add more threads and more execution units, it becomes harder and harder to keep the cost of the scheduler to a reasonable level.
In the second stage of VISC, you have multiple schedulers, each feeding a small number of execution units, which keeps these schedulers simple. In the first stage, the schedulers require at least some awareness of all the execution units. For example, if you have an integer multiply instruction, you want to send it to a core that doesn't have other integer multiply operations outstanding rather than just chosing the core with the smallest total number of outstanding operations. What may keep the first stage scheduling reasonably simple is that it doesn't appear to do any instruction reordering (though it does have to do the bookwork to keep track of which instructions have been retired).
In short, VISC appears to be intended to scale better than SMT as you add more threads and execution units.
What is strange, then, is that Soft Machines isn't talking about building an 8 thread device like IBM's POWER8. Instead, they have a two and four thread designs, and are mostly talking about the former. A two thread VISC design makes sense only if you believe that the SMT approach is already hitting its limits with two threads.
My sense is that VISC is not going to be a game changer, but Soft Machines could be successful if ARM Holdings screws up. If ARM has has a major screw up technologically (like AMD did with Bulldozer), Soft Machines could end up with a superior product. Conversely, if ARM screws up on customer relations, all Soft Machines would need is something close to technological parity with ARM to win customers.
Shadowmaster625 - Monday, February 15, 2016 - link
When Intel purchased Altera I immediately began to visualize all sorts of great potential breakthroughs in single threaded IPC. I imagine that within 5 years, we will have at least a modest number of FPGA cells integrated within Intel CPU cores. These cells will be programmed on-the-fly with application specific DSPs that will be capable of completing commonly used combinations of instructions MUCH faster than the general x86 instruction set would allow. I expect this to be the singularly largest breakthrough in computing of the last 20 years. Within 10 years, I expect the CPU itself to create its own DSP code on the fly as it profiles its own instruction loading in real time. The potential here is utterly massive. Think about what ASICs have done for bitcoin mining... Soon they will be able to do that for javascript!FunBunny2 - Monday, February 15, 2016 - link
-- capable of completing commonly used combinations of instructions MUCH faster than the general x86 instruction set would allow. I expect this to be the singularly largest breakthrough in computing of the last 20 years.that's what the real cpu/RISC core/micro-architecture has done for decades. twerked continually.
-- I imagine that within 5 years, we will have at least a modest number of FPGA cells integrated within Intel CPU cores.
done: http://www.extremetech.com/extreme/184828-intel-un...
"This new Xeon+FPGA chip will fit in the standard E5 LGA2011 socket, but the integrated FPGA will allow each chip to be customized to specific workloads."
Shadowmaster625 - Monday, February 15, 2016 - link
That's not what I mean. That is of course a good start, but what I'm talking about is programmable logic linked tightly to the actual execution units of the CPU core. Smaller blocks, probably only a square millimeter or perhaps even less. But many of them. Just like Skylake has 6 execution units. One of these programmable blocks would be only about the same size as one of those existing execution units. They would have direct access to the prefetcher and scheduler and instruction/data caches. They would be power gated.dustwalker13 - Saturday, February 20, 2016 - link
yes it looks good on paper ... but up to now that is all that it does.silicon existing at HQ is so much smoke and mirrors until some independant source has an actual go at it and publishes results.
it looks promising, but so did a million other things that ended up as just another failiur or worse scam.
i will keep an eye on this one but for now there simply is nothing to see than mirror images produced by a lot of hot air.
mikato - Saturday, February 20, 2016 - link
So why did they come out of stealth mode?TruePath - Saturday, April 16, 2016 - link
I've been curious for a long time why more wasn't done to use parallel resouces to extract instruction level parrelism.However, what puzzles me is why do so much of the work on the fly at run time. Sure, one needs to be able to respond to dynamic performance information like failed speculation but it seems like there is substantial overhead in translating the host ISA into native instructions and (I assume) encoding information into the native instructions about resource needs and dependencies.
Even before a program is run knowledge of the exact processor would enable software to translate the ISA (targeting the exact chip), hint at resources needs and perform a degree of instruction reordering (over a larger window than in hardware).
So why not push as much of this into the software as possible. One can even cache the results of software ISA translation. Is it just a desire to be totally hardware compatible?