GeForce + Radeon: Previewing DirectX 12 Multi-Adapter with Ashes of the Singularity
by Ryan Smith on October 26, 2015 10:00 AM ESTA Brief History on Multi-GPU with Dissimilar GPUs
Before we dive into our results, let’s talk briefly about the history of efforts to render games with multiple, dissimilar GPUs. After the development of PCI Express brought about the (re)emergence of NVIDIA’s SLI and AMD’s CrossFire, both companies eventually standardized their multi-GPU rendering efforts across the same basic technology. Using alternate frame rendering (AFR), NVIDIA and AMD would have the GPUs in a multi-GPU setup each render a separate frame. With the drivers handing off frames to each GPU in an alternating manner, AFR was the most direct and most compatible way to offer multi-GPU rendering as it didn’t significantly disrupt the traditional game rendering paradigms. There would simply be two (or more) GPUs rendering frames instead of one, with much of the work abstracted by the GPU drivers.
Using AFR allowed for relatively rapid multi-GPU support, but it did come with tradeoffs as well. Alternating frames meant that inter-frame dependencies needed to be tracked and handled, which in turn meant that driver developers had to add support for games on a game-by-game basis. Furthermore the nature of distributing the work meant that care needed to be taken to ensure each GPU rendered at an even pace so that the resulting in-game motion was smooth, a problem AMD had to face head-on in 2013. Finally, because AFR had each GPU rendering whole frames, it worked best when GPUs were as identical as possible in performance; a performance gap would at best require a faster card to spend some time waiting on the slower card, and at worse exacerbate the aforementioned frame pacing issues. As a result NVIDIA only allows identical cards to be paired up in SLI, and AMD only allows a slightly wider variance (typically cards using the same GPU).

In 2010 LucidLogix set out to do one better, leveraging their graphics expertise to develop their Hydra technology. By using a combination of a hardware and software, Hydra could intercept DirectX and OpenGL calls and redistribute them to split up rendering over multiple, and for the first time, dissimilar GPUs. Long a dream within the PC gaming space (and subject of a few jokes), the possibilities for using dissimilar GPUs via Hydra were immense – pairing up GPUs not only from different vendors, but of differing performance as well – resolving some of AFR’s shortcomings while allowing gamers to do things such as reuse old video cards and still receive a performance benefit.
However in the long run the Hydra technology failed to catch on. The process of splitting up API calls, having multiple GPUs render them, and compositing them back together to a single frame proved to be harder than LucidLogix expected, and as a result Hydra’s compatibility was poor and performance gains were limited. Coupled with the cost of the hardware, the licensing, and the fact that Hydra boards were never SLI certified (preventing typical NVIDIA SLI operation) meant that Hydra had a quick exit from motherboards.
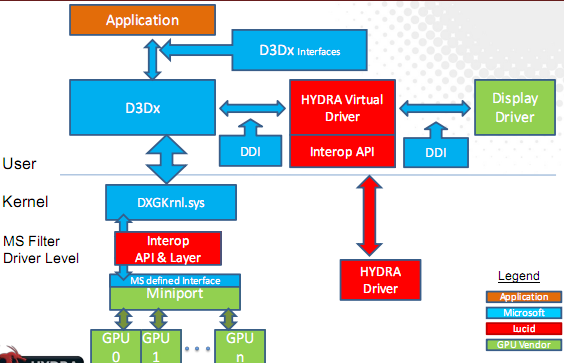
In the end what LucidLogix was attempting was a valiant effort, but in retrospect one that was misguided. Working at the back-end of the rendering chain and manipulating API calls can work, but it is a massive amount of effort and it has hardware developers aiming at a moving target, requiring constant effort to keep up with new games. AMD and NVIDIA’s driver-level optimizations don’t fare too much better in this respect; there are vendor-specific shortcuts such as NVAPI that simplify this some, but even AMD and NVIDIA have to work to keep up with new games. This is why they need to issue driver updates and profile updates so frequently in order to get the best performance out of CrossFire and SLI.
But what if there was a better way to manage multiple GPUs and assign work to them? Would it be possible to do a better job working from the front-end of the rendering chain? This is something DirectX 12 sets out to answer with its multi-adapter modes.
DirectX 12 Multi-GPU
In DirectX 12 there are technically three different modes for multi-adapter operation. The simplest of these modes is what Microsoft calls Implicit Multi-Adapter. Implicit Multi-Adapter is essentially the lowest rung of multi-adapter operation, intended to allow developers to use the same AFR-friendly techniques as they did with DirectX 11 and before. This model retains the same limited ability for game developers to control the multi-GPU rendering process, which limits the amount of power they have, but also limits their responsibilities as well. Consequently, just as with DirectX 11 mutli-GPU, in implicit mode much of the work is offloaded to the drivers (and practically speaking, AMD and NVIDIA).

While the implicit model has the most limitations, the lack of developer responsibilities also means it’s the easiest to implement. In an era where multi-platform games are common, even after developers make the switch to DirectX 12 they may not want to undertake the effort to support Explicit Multi-Adapter, as the number of PC owners with multiple high-powered GPU is a fraction of the total PC gaming market. And in that case, with help from driver developers, implicit is the fastest path towards supporting multiple GPUs.

What’s truly new to DirectX 12 then are its Explicit Multi-Adapter (EMA) modes. As implied by the name, these modes require game developers to explicitly program for multi-GPU operation, specifying how work will be assigned to each GPU, how memory will be allocated, how the GPUs will communicate, etc. By giving developers explicit control over the process, they have the best chance to extract the most multi-GPU performance out of a system, as they have near-absolute control over both the API and the game, allowing them to work with more control and more information than any of the previously discussed multi-GPU methods. The cost of using explicit mode is resources: with great power comes great responsibility, and unlike implicit mode, game developers must put in a fair bit of work to make explicit mode work, and more work yet to make it work well.
Within EMA there are two different ways to address GPUs: linked mode and unlinked mode. Unlinked mode is essentially the baseline mode for EMA, and offers the bulk of EMA’s features. Linked mode on the other hand builds unlinked that by offering yet more functionality in exchange for much tighter restrictions on what adapters can be used.

The ultimate purpose of unlinked mode is to allow developers to take full advantage of all DirectX 12 capable GPU resources in a system, at least so long as they are willing to do all of the work required to manage those resources. Unlinked mode, as opposed to linked mode and implicit multi-adapter, can work with DX12 GPUs from any vendor, providing just enough abstraction to allow GPUs to exchange data but putting everything else in the developer’s hands. Depending on what developers want to do, unlinked mode can be used for anything from pairing up two dGPUs to pairing up a dGPU with an iGPU, with the GPUs being a blank slate of sort for developers to use as they see fit for whatever algorithms and technologies they opt to use.
As the base mode for DirectX 12 multi-GPU, unlinked mode presents each as its own device, with its own memory, its own command processor, and more, accurately representing the layout of the physical hardware. What DirectX 12’s EMA brings to the table that’s new is that it allows developers to exchange data between GPUs, going beyond just finished, rendered images and potentially exchanging partially rendered frames, buffers, and other forms of data. It’s the ability to exchange multiple data types that gives EMA its power and its flexibility, as without it, it wouldn’t be possible to implement much more than AFR. EMA is the potential for multiple GPUs to work together, be it similar or disparate; no more and no less.
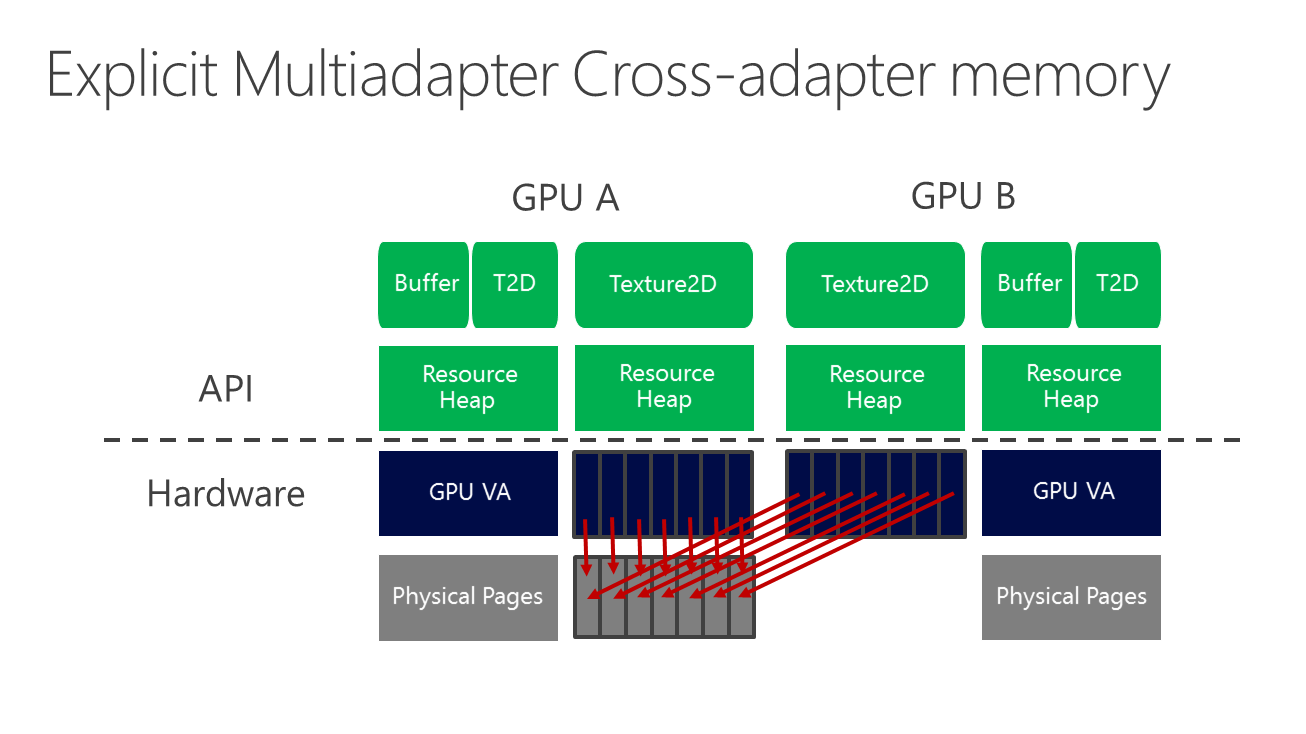
If this sounds very vague that’s because it is, and that in turn is because the explicit API outstrips what today’s hardware is capable of. Compared to on-board memory, any operations taking place over PCI Express are relatively slow and high latency. Some GPUs in turn handle this better than others, but at the end of the day the PCIe bus is still a bottleneck at a fraction of the speed of local memory. That means while GPUs can work together, they must do so intelligently, as we’re not yet at the point where GPUs can quickly transfer large amounts of data from each other.
Because EMA is a blank slate, it ultimately falls to developers to put it to good use; DirectX 12 just supplies the tools. Traditional AFR implementations are one such option, and so are splitting up workloads in other fashions such as split-frame rendering (SFR), or even methods where one GPU doesn’t render a complete frame or fractions of a complete frame, passing off frames at different stages to different GPUs.
But practically speaking, a lot of the early focus on EMA development and promotion is on dGPU + iGPU, and this is because the vast majority of PCs with a dGPU also have an iGPU. Relative to even a $200 dGPU, an iGPU is going to offer a fraction of the performance, but it’s also a GPU resource that is otherwise going unused. Epic Games has been experimenting with using EMA to have iGPUs do post-processing, as finished frames are relatively small (1080p60 with an FP32 frame is only 2GB/sec, a fraction of PCIe 3.0 x16’s bandwidth), post-processing is fairly lightweight in resource requirements, and it typically has a predictable processing time.

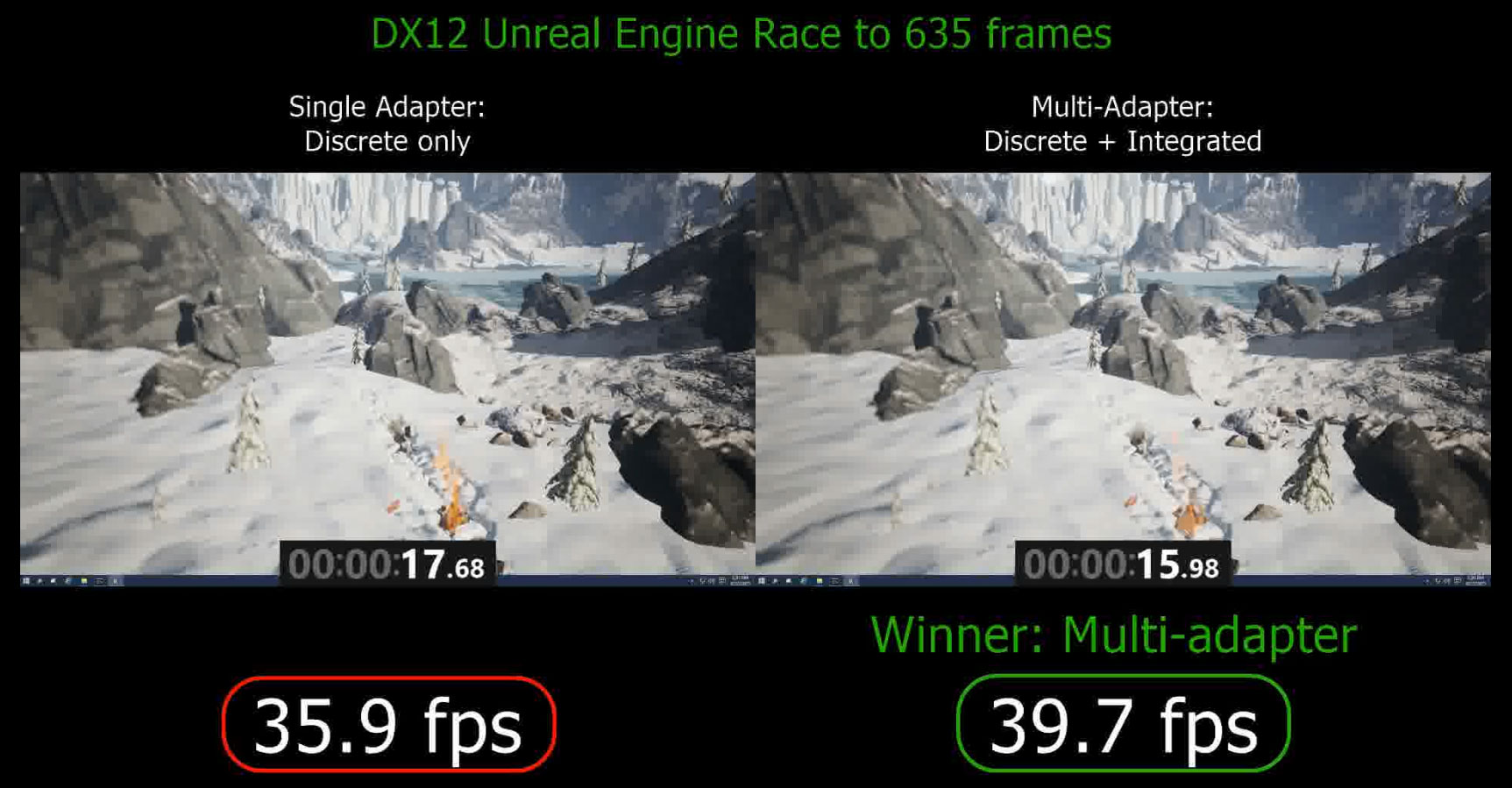
Moving on, building on top of unlinked mode is EMA’s linked mode. Linked mode is by and large the equivalent of SLI/CrossFire for EMA, and is designed for systems where all GPUs being used are near-identical. Within linked mode all of the GPUs are pooled and presented to applications as a single GPU, just with multiple command processors and multiple memory pools due to the limits of the PCIe bus. Because linked mode is restricted to similar GPUs, developers gain even more power and control, as linked GPUs will be from the same vendor and use the same data formats at every step.

Broadly speaking, linked mode will be both easier and harder for developers to use relative to unlinked mode. Unlike unlinked mode there are certain assumptions that can be made about the hardware and what it’s capable of, and developers won’t need to juggle the complications of using GPUs from multiple vendors at once. On the other hand this is the most powerful mode because of all of the options it presents developers, with more complex rendering techniques likely to be necessary to extract the full performance benefit of linked mode.
Ultimately, one point that Microsoft and developers have continually reiterated in their talks is that explicit multi-adapter is that like so many other low-level aspects of DirectX 12, it’s largely up to the developers to put the technology to good use. The API provides a broad set of capabilities – tempered a bit by hardware limitations and how quickly GPUs can exchange data – but unlike DirectX 11 and implicit multi-adapter, it’s developers that define how GPUs should work together. So whether a game supports any kind of EMA operation and whether this means combining multiple dGPUs from the same vendor, multiple dGPUs from different vendors, or a dGPU and an iGPU is a question of software more than it is of hardware.








180 Comments
View All Comments
jardows2 - Monday, October 26, 2015 - link
Time to go Team Orange!hans_ober - Monday, October 26, 2015 - link
That moment when you unintentionally perform better together with your competition compared to your own homies.medi03 - Monday, October 26, 2015 - link
I've missed why they didn't compare vs SLI/Crossfire for older cards.Ryan Smith - Monday, October 26, 2015 - link
To be clear, that would require Ashes to support implicit multi-adapter, which it does not.wishgranter - Monday, October 26, 2015 - link
and how it scales with 3-4+ cars in a system ? or its limited to dual card config right now ??willis936 - Monday, October 26, 2015 - link
I think you mean team yellow if it's additive or team brown if it's subtractive.rituraj - Tuesday, October 27, 2015 - link
+1pogostick - Tuesday, October 27, 2015 - link
So, team spotted banana then.BurntMyBacon - Tuesday, October 27, 2015 - link
Clever analogy, but this worked way to well to be associated with a overripe banana. How about yellow banana for the the ATi + nVidia combo (since it seems to be a good amount of ripe for both setups) and brown banana for the nVidia + ATi combo (Since its performance was a little rotten for the older card setup).On a more serious note, I wonder what the results would be if you used a less powerful ATi card and a more powerful nVidia card for the older setup. Maybe an HD7950 + GTX780 and vice versa.
pogostick - Tuesday, October 27, 2015 - link
Hey, it was still better than team turds with corn.