ADATA XPG V2 Review: 2x8 GB at DDR3-2400 C11-13-13 1.65 V
by Ian Cutress on November 11, 2013 1:00 PM ESTCPU Compute
One side I like to exploit on CPUs is the ability to compute and whether a variety of mathematical loads can stress the system in a way that real-world usage might not. For these benchmarks we are ones developed for testing MP servers and workstation systems back in early 2013, such as grid solvers and Brownian motion code. Please head over to the first of such reviews where the mathematics and small snippets of code are available.
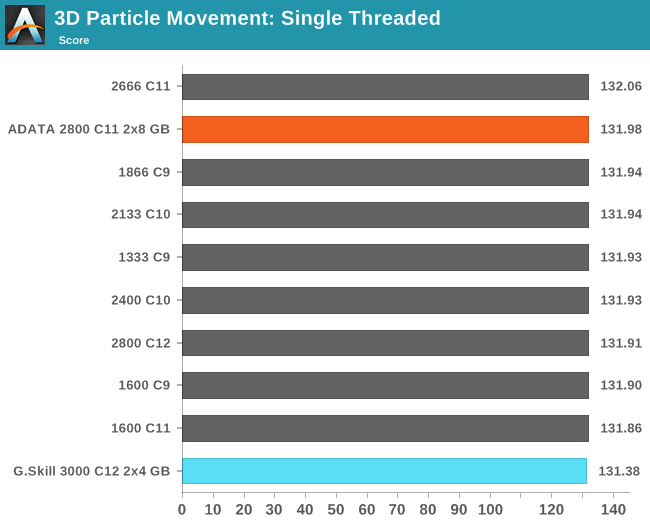
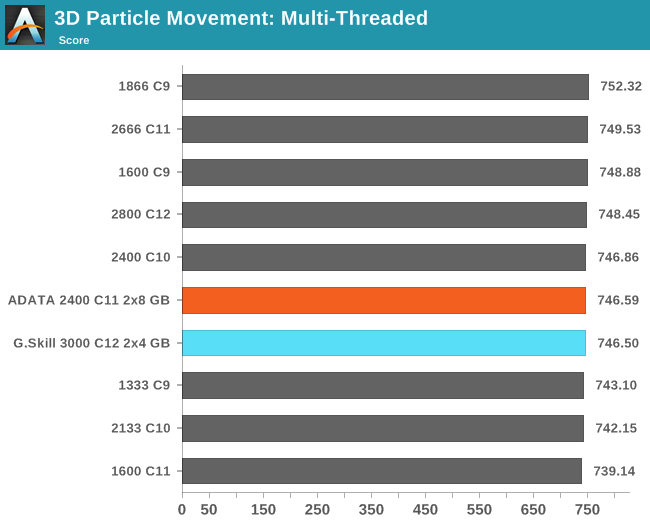
3D Movement Algorithm Test
The algorithms in 3DPM employ uniform random number generation or normal distribution random number generation, and vary in various amounts of trigonometric operations, conditional statements, generation and rejection, fused operations, etc. The benchmark runs through six algorithms for a specified number of particles and steps, and calculates the speed of each algorithm, then sums them all for a final score. This is an example of a real world situation that a computational scientist may find themselves in, rather than a pure synthetic benchmark. The benchmark is also parallel between particles simulated, and we test the single thread performance as well as the multi-threaded performance. Results are expressed in millions of particles moved per second, and a higher number is better.
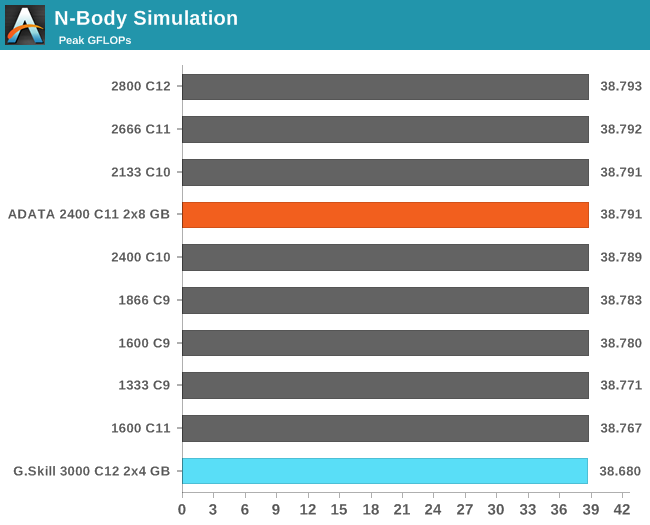
N-Body Simulation
When a series of heavy mass elements are in space, they interact with each other through the force of gravity. Thus when a star cluster forms, the interaction of every large mass with every other large mass defines the speed at which these elements approach each other. When dealing with millions and billions of stars on such a large scale, the movement of each of these stars can be simulated through the physical theorems that describe the interactions. The benchmark detects whether the processor is SSE2 or SSE4 capable, and implements the relative code. We run a simulation of 10240 particles of equal mass - the output for this code is in terms of GFLOPs, and the result recorded was the peak GFLOPs value.
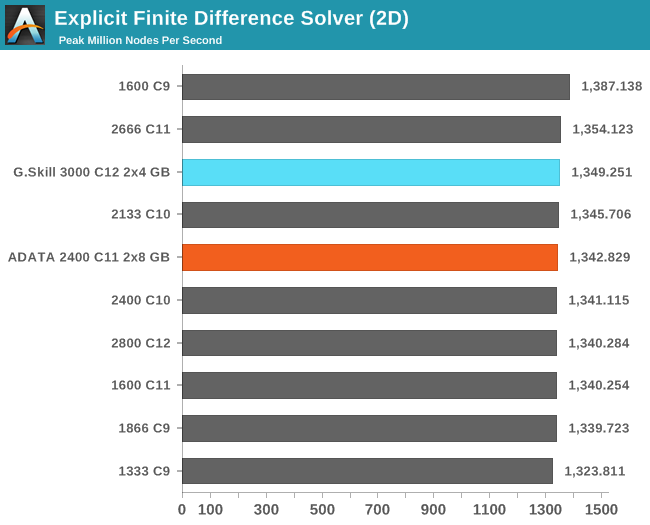
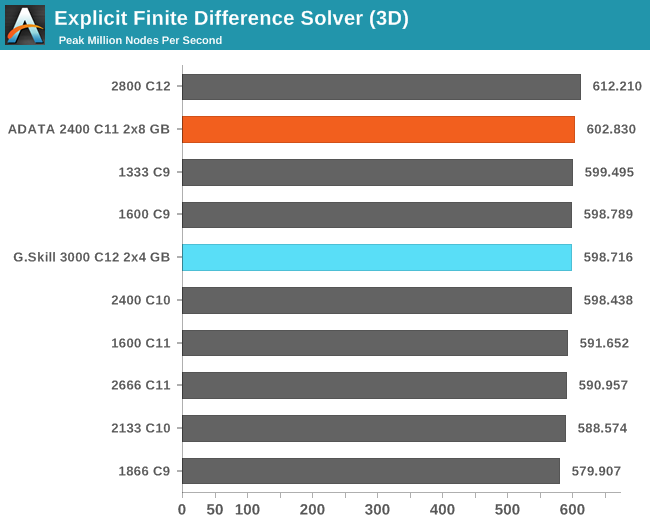
Grid Solvers - Explicit Finite Difference
For any grid of regular nodes, the simplest way to calculate the next time step is to use the values of those around it. This makes for easy mathematics and parallel simulation, as each node calculated is only dependent on the previous time step, not the nodes around it on the current calculated time step. By choosing a regular grid, we reduce the levels of memory access required for irregular grids. We test both 2D and 3D explicit finite difference simulations with 2n nodes in each dimension, using OpenMP as the threading operator in single precision. The grid is isotropic and the boundary conditions are sinks. We iterate through a series of grid sizes, and results are shown in terms of ‘million nodes per second’ where the peak value is given in the results – higher is better.
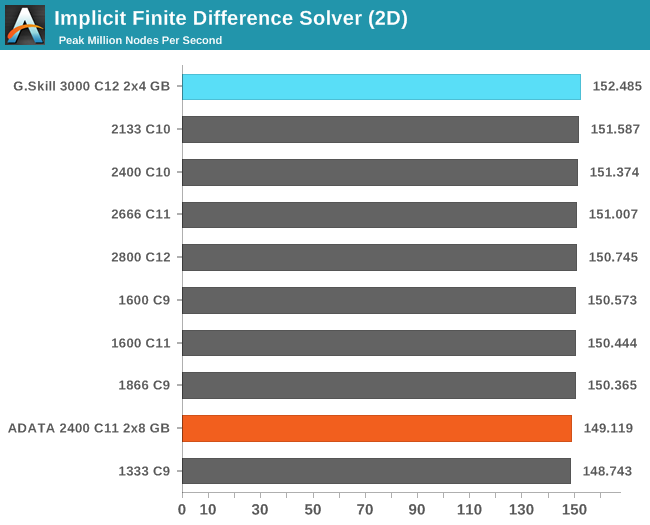
Grid Solvers - Implicit Finite Difference + Alternating Direction Implicit Method
The implicit method takes a different approach to the explicit method – instead of considering one unknown in the new time step to be calculated from known elements in the previous time step, we consider that an old point can influence several new points by way of simultaneous equations. This adds to the complexity of the simulation – the grid of nodes is solved as a series of rows and columns rather than points, reducing the parallel nature of the simulation by a dimension and drastically increasing the memory requirements of each thread. The upside, as noted above, is the less stringent stability rules related to time steps and grid spacing. For this we simulate a 2D grid of 2n nodes in each dimension, using OpenMP in single precision. Again our grid is isotropic with the boundaries acting as sinks. We iterate through a series of grid sizes, and results are shown in terms of ‘million nodes per second’ where the peak value is given in the results – higher is better.








23 Comments
View All Comments
Rick83 - Monday, November 11, 2013 - link
So running memory on a 22nm CPU at 1.65 volts (or more, for the OC) has suddenly become acceptable again? Last I heard everyone clamoring to only get 1.5V memory, so as not to fry the IMC before its time.At $200, the key point is that by taking a $100 kit and putting those $100 dollars toward more memory or toward extra CPU performance would probably be better. Going with IB-E instead of with Haswell could probably done with that extra money - and you get double the memory channels to play with as a result.
IanCutress - Monday, November 11, 2013 - link
Most DDR3 memory past 1866 C9 is at 1.65 volts. These IMCs are sturdy enough, almost all will take 2x8 GB 2933 C12 without breaking a sweat. When did it ever become unacceptable? I've never seen any issues except taking Sandy above 2400 MHz, because the IMC wasn't particularly built for it. Ivy kicked it up a notch and Haswell accepts most of what I throw at it as long as you're reasonable and the memory itself can handle it.owan - Monday, November 11, 2013 - link
There was a LOT of talk when SB released about using 1.5v ram instead of 1.65v due to the IMC supposedly not tolerating higher voltages well. I don't know how true it was, but I thought this was common knowledge.hoboville - Monday, November 11, 2013 - link
Yes, there has been (and still is concern) that over-volting RAM can have a negative impact on the memory controller, because it is on the CPU die. RAM voltages and power do have an impact on the memory controller, of that there is no doubt. In fact, Registered Memory (also known as Fully Buffered or just Buffered Memory) was a design that came about when the IMC had to interface with large amounts of RAM (and power), particularly servers where 8+ slots is not uncommon.http://en.wikipedia.org/wiki/Registered_memory
The Von Matrices - Monday, November 11, 2013 - link
Well, according to Intel (http://www.intel.com/support/processors/sb/CS-0299..."Intel recommends using memory that adheres to the Jedec memory specification for DDR3 memory which is 1.5 volts, plus or minus 5%. Anything more than this voltage can damage the processor or significantly reduce the processor life span."
However, I have not seen anyone who had a processor fail explicitly due to 1.65V memory. Granted, this might be hard to tell because many of the failed processors with 1.65V memory also have core overclocking and overvolting, and separating the actual cause of failure is impossible without an electron microscope.
I run my Hawswell system at 1.65V DDR3-2400, and I am not worried about 1.65V killing the processor. What's more concerning to me is that my Mushkin Blackline memory's XMP profile adjusts the system agent voltage +0.3V, which is far too much for me. I forced it back to default voltage and the memory works fine.
jabber - Tuesday, November 12, 2013 - link
It may be that Intel's research determined that running at 1.65v could reduce the life of the CPU from 30 years to 28 years.freedom4556 - Tuesday, November 12, 2013 - link
Yeah, I love that there is a huge difference between the statistical and colloquial meaning of the word "significant" that always seems to be abused by marketers and misused by media.kishorshack - Monday, November 11, 2013 - link
This is an Anandtech Reviewhoboville - Monday, November 11, 2013 - link
A quick suggestion: could you do a ranking of performance index as related to price, displaying performance per dollar?For gamers, the biggest point is how much time the GPU spends asking the RAM for data. Games that are more heavily CPU bound will probably see some benefit from faster RAM. It is worth noting that Dirt 3 seems to benefit the most from lower timings, as the lowest timings see the highest FPS. Undoubtedly, each GPU is waiting for information from RAM, and in turn, longer RAM latency means that each GPU has to wait for its chunk of data. Better titles will rely less on CPU and more on GPU, maybe Mantle will have some effect on this with reduced draw calls?
Anyway, the price scaling on these "performance" RAM is so large that I couldn't in good conscience ever recommend anyone buying them when they would be better off spending it on a: dGPU, better dGPU, second dGPU.
freedom4556 - Monday, November 11, 2013 - link
"Games that are more heavily CPU bound will probably see some benefit from faster RAM."Not according to nearly every review I've ever read on memory. Most reviews have all results within about 5 fps of each other regardless of game. Only synthetics really benefit. See articles like:
http://anandtech.com/show/7364/memory-scaling-on-h...
http://www.techpowerup.com/reviews/Avexir/Core_Ser...
http://www.tomshardware.com/reviews/low-voltage-dd...