Gigabyte GA-7PESH1 Review: A Dual Processor Motherboard through a Scientist’s Eyes
by Ian Cutress on January 5, 2013 10:00 AM EST- Posted in
- Motherboards
- Gigabyte
- C602
Gigabyte GA-7PESH1 Software
Typically when a system integrator buys a server motherboard from Gigabyte, a full retail package comes with it including manuals, utility CDs and SATA cables. Gigabyte have told me that this will be improved in the future, with SAS cables, header accessories and GPU bridges for CF/SLI. But due to the nature of my review sample, there was no retail package as such. When I received a sample from Gigabyte, there was no retail box with extras, nor were there driver CDs or a user guide and manual. Good job then that all these can be found on the Gigabyte website under the download section for the GA-7PESH1. In my case, this involves downloading the Intel .inf files, the ASPEED 2300 drivers, and the Intel LAN drivers. Also available on the website are the LSI SAS RAID drivers, and the SATA RAID driver.
When it comes to software available to download, the river has run dry. There is literally not one piece of software available to the user – nothing relating to monitoring, or fan controls or the like. The only thing that approaches a software tool is the Advocent Server Management Interface, which is accessed via the browser of another computer connected to the same network when the system has the third server management NIC connection activated.
When the system is connected to the power supply, and the power supply is switched on, the motherboard takes around 30 seconds to prepare itself before the power button on the board itself can be pushed. There is a green light physically on the board that turns from a solid light to a flashing light when this button can be pushed - the board then takes another 60 seconds or so to POST. During this intermediate state when the light is flashing, the server management software can be accessed through the web interface.
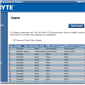
The default username and password are admin and password for this interface, and when logged in we get a series of options relating to the management of the motherboard:
The interface implements a level of security in accessing the management software, as well as keeping track of valid user accounts, web server settings, and active interface sessions.


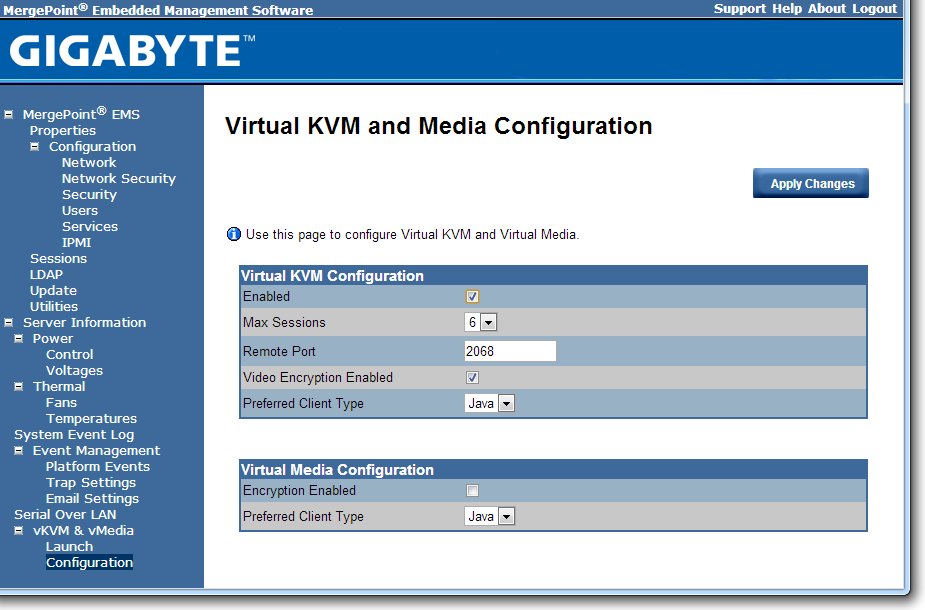
The software also provides options to update the firmware, and to offer full control as to the on/off state of the motherboard with access to all voltages, fan speeds and temperatures the software has access to.

The system log helps identify when sensors are tripped (such as temperature and fans) as well as failed boots and software events.
Both Java KVM and Have VM environments are supported, with options relating to these in the corresponding menus.
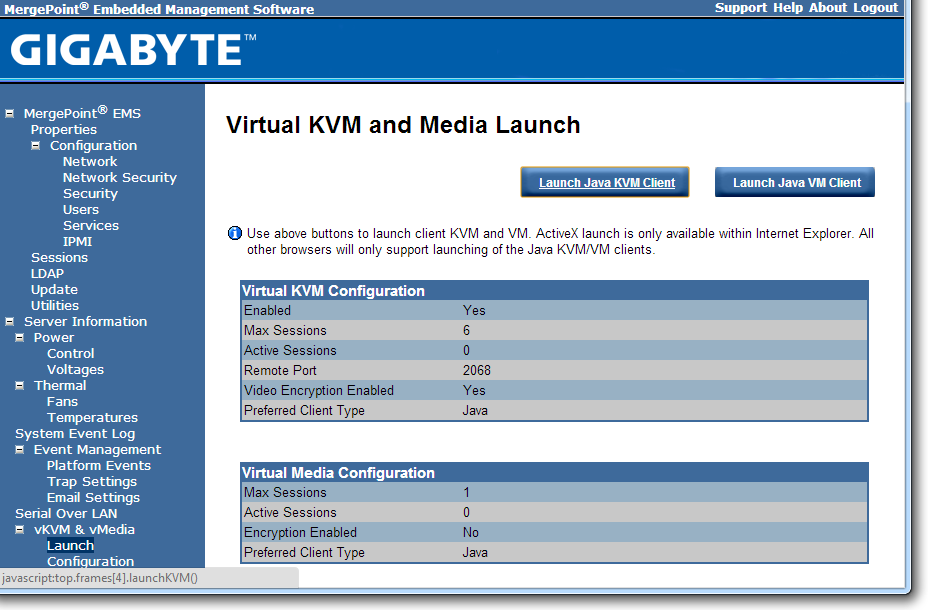
It should also be noted that during testing, we found the system to be unforgiving when changing discrete GPUs. If an OS was installed while attached to a GTX580 and NVIDIA drivers were installed, the system would not boot if the GTX580 was removed and a HD7970 was put in its place. The same thing happens if the OS is installed under the HD7970 and the AMD drivers installed.








64 Comments
View All Comments
Hulk - Saturday, January 5, 2013 - link
I had no idea you were so adept with mathematics. "Consider a point in space..." Reading this brought me back to Finite Element Analysis in college! I am very impressed. Being a ME I would have preferred some flow models using the Navier-Stokes equations, but hey I like chemistry as well.IanCutress - Saturday, January 5, 2013 - link
I never did any FEM so wouldn't know where to start. The next angle of testing would have been using a C++ AMP Fluid Dynamics Simulation and adjusting the code from the SDK example like with the n-Body testing. If there is enough interest, I could spend a few days organising it for the normal motherboard reviews :)Ian
mayankleoboy1 - Saturday, January 5, 2013 - link
How the frick did you get the i7-3770K to *5.4GHZ* ? :shock:How the frick did you get the i7-3770K to *5.0GHZ* ? :shock:
IanCutress - Saturday, January 5, 2013 - link
A few members of the Overclock.net HWBot team helped testing by running my benchmark while they were using DICE/LN2/Phase Change for overclocking contests (i.e. not 24/7 runs). The i7-3770K will go over 7 GHz if (a) you get a good chip, (b) cool it down enough, and (c) know what you are doing. If you're interested in competitive overclocking, head over to HWBot, Xtreme Systems or Overclock.net - there are plenty of people with info to help you get started.Ian
JlHADJOE - Tuesday, January 8, 2013 - link
The incredible performance of those overclocked Ivy bridge systems here really hammers home the importance of raw IPC. You can spend a lot of time optimizing code, but IPC is free speed when it's available.jd_tiger - Saturday, January 5, 2013 - link
http://www.youtube.com/watch?v=Ccoj5lhLmSQsmonsees - Saturday, January 5, 2013 - link
You might try modifying your algorithm to pin the data to a specific core (therefore cache) to keep the thrashing as low as possible. Google "processor affinity c++". I will admit this adds complexity to your straightforward algorithm. In C#, I would use a parallel loop with a range partition to do it as a starting point: http://msdn.microsoft.com/en-us/library/dd560853.a...nickgully - Saturday, January 5, 2013 - link
Mr. Cutress,Do you think with all the virtualized CPU available, researchers will still build their own system as it is something concrete to put into a grant application, versus the power-by-the-hour of cloud computing?
Thanks.
IanCutress - Saturday, January 5, 2013 - link
We examined both scenarios. Our university had cluster time to buy, and there is always the Amazon cloud. In our calculation, getting a 16 thread machine from Dell paid for itself in under six months of continuous running, and would not require a large adjustment in the way people were currently coding (i.e. staying in Windows rather than moving to Linux), and could also be passed down the research group when newer hardware is released.If you are using production level code and manipulating it each time to get results, and you can guarantee the results will be good each time, then power-by-the-hour could work. As we were constantly writing and testing new code for different scenarios, the build/buy your own workstation won out. Having your own system also helps in building GPU codes, if you want to buy a better GPU card it is easier to swap out rather than relying on a cloud computing upgrade.
Ian
jtv - Sunday, January 6, 2013 - link
One big consideration is who the researchers are. I work in x-ray spectroscopy (as a computational theorist). Experimentalists in this field use some of our codes without wanting to bother with having big computational resources. We have looked at trying to provide some of our codes through some cloud-based service so that it can be used on demand.Otherwise I would agree with Ian's reply. When I'm improving code, debugging code, or trying to implement new theoretical approaches I absolutely want my own hardware to do it on.