The Xeon Phi at work at TACC
by Johan De Gelas on November 14, 2012 1:44 PM EST- Posted in
- Cloud Computing
- CPUs
- IT Computing
- Intel
- Larrabee
- Xeon
- Xeon Phi
The Xeon Phi card comes on a PCIe card, much like a GPU. Given the architecture's origins as a GPU, the form factor should't come as a surprise. Like modern HPC GPUs however, the Xeon Phi card has no display output - its role is strictly for compute.
The Xeon Phi acts as a multi-core system on chip running its own operating system, a modified Linux kernel. Each Xeon Phi card has its own IP address however, the Xeon Phi can not operate on its own. A "normal" Xeon will be be the host CPU, the Xeon Phi card is a coprocessor, similar to the way your CPU and GPU work together.
Below you can see the SKUs that Intel will offer.
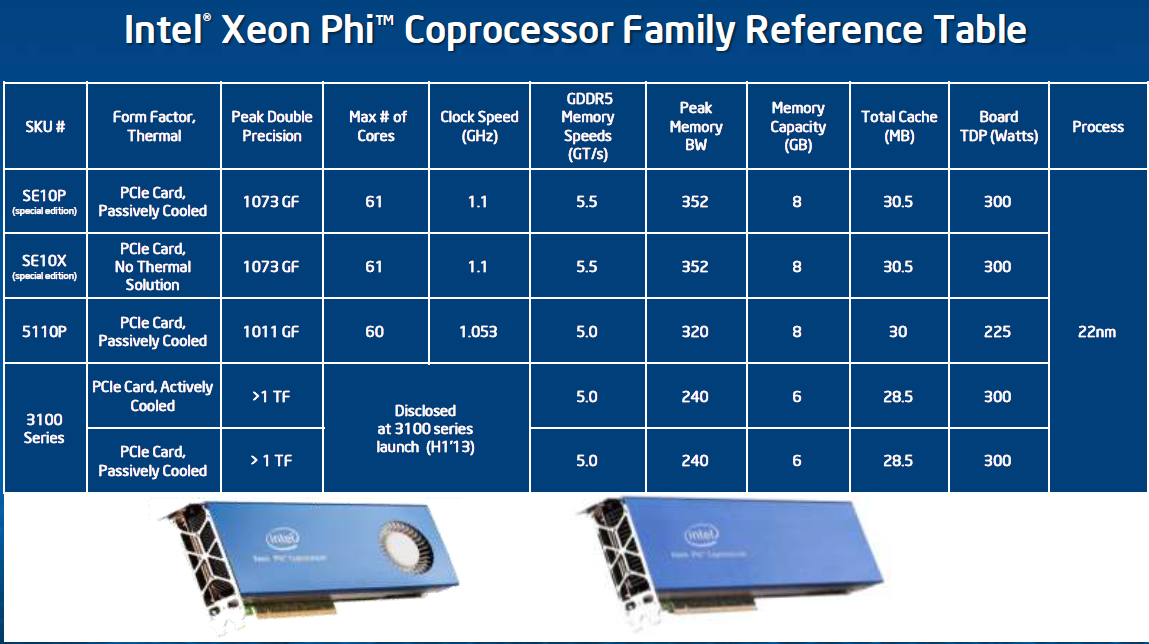
The Xeon Phi inside the Stampede are special edition Xeon Phis.These special editions get 61 cores and run at a slightly higher clockspeed (1.1 GHz).
The commercially avialable 5110P has one core and 50 MHz less than the special edition Phi but comes with 8 GB of ECC memory. The P-suffix indicates that it's passively cooled, relying on the host server for airflow. The 5110P is not cheap at $2699, but it's still more affordable than NVIDIA's Tesla K20 ($3199). The Xeon Phi 5100 series is really intended for more memory bandwidth bound applications thanks to the use of 5GHz GDDR5 and a fully populated 512-bit memory interface.
For compute bound applications however, Intel will offer the Xeon Phi 3100 series in the first half of next year for less than $2000. The Xeon Phi 3100 will come with 6GB of GDDR5 (5GHz data rate) and only a 384-bit memory interface. Core clock should be higher, delivering over 1TFLOP of DP FP performance.
The Xeon Phi cards use a 7GHz PCIe 2.0 interface, as Intel found moving to PCIe 3.0 resulted in slightly higher overhead.








46 Comments
View All Comments
tipoo - Wednesday, November 14, 2012 - link
I wonder if we'll ever have more numerous smaller cores like these working in conjunction with larger traditional cores. A bit like the PPE and SPEs in the Cell processor, with the more general core offloading what it can to the smaller ones.A5 - Wednesday, November 14, 2012 - link
That's called heterogeneous computing. It's definitely where things are going in the future and you can argue that it's already here with Trinity.nevertell - Wednesday, November 14, 2012 - link
The great thing about the Cell was that both the PPE and the SPEs had access to the same memory. Trinity doesn't and while that may be because there isn't an OS that would take advantage of that, hardware is as capable as software is efficient for that exact hardware solution.There is no need for major parallelism in the consumer space, since nobody is willing to rewrite their programs to run on something faster whilst the general public is already served well enough by a Core i3 or i5.
name99 - Friday, November 16, 2012 - link
"The great thing about the Cell was that both the PPE and the SPEs had access to the same memory."Hmm. This is not a useful statement.
Cell had a ludicrous addressing model that was clearly irrelevant to the real world. It's misleading to say that the cores had access to "the same memory". The way it actually worked was that each core had a local address space (I'm think 12bit wide, but I may be wrong, maybe 14 bits wide) and almost every instruction operated in that local address space. There were a few special purpose instructions that moved data between that local address space and and the global address space. Think of it as like programming with 8086 segments, only you have only one data segment (no ES, no SS), you can't easily swap DS to access another segment, and the segment size is substantially smaller than 64K.
Much as I dislike many things about Intel, more than anyone else they seem to get that hardware that can't be programmed is not especially useful. And so we see them utilizing ideas that are not exactly new (this design, or transactional memory) but shipping them in a form that's a whole lot more useful than what went before.
This will get the haters on all sides riled up, but the fact is --- this is very similar to what Apple does in their space.
dcollins - Wednesday, November 14, 2012 - link
That's exactly how this supercomputer, and all supercomputers offering accelerated compute, work. Xeon or Opteron CPUs handle complex branching tasks like networking and work distribution while the accelerators handle the parallelizable problem solving work.Merging them onto a single die is simply a matter of having enough die space to fit everything while making sure that economics of a single chip is better than separate products.
tipoo - Wednesday, November 14, 2012 - link
*in consumer computing I mean.Gigaplex - Wednesday, November 14, 2012 - link
Both AMD Fusion and Intel Ivy Bridge support this right now. The software just needs to catch up.tipoo - Wednesday, November 14, 2012 - link
Sort of I suppose, but I think something like this would be easier to use for most compute tasks for the reasons the article states, these are still closer to general processor cores than GPU cores are.frostyfiredude - Wednesday, November 14, 2012 - link
Something like ARM's big.LITTLE in a sense seems like a good idea to me. I'm not sure how feasable it is, but having one or two small Atom-like cores paired to larger and more complex Core processing cores all sharing the same L3 sounds like a decent idea for mobile CPUs to cut idle power use. My guess is the two types of cores would need to share the same instructions, so the differences would be things like OoO vs In-order, execution width, designed for low clock speed vs high clock speed. The Atom SoCs can hit power use around that of ARM SoCs, so if Intel can get that kind of super low power use at low loads and ULV i7 performance out of the same chip when stressed that'd be super killer.CharonPDX - Thursday, November 15, 2012 - link
One rumor I had heard upon Larrabee getting cancelled and turned into Knights Ferry was that this technology might be released as a coprocessor that used the same socket as the "main" Xeon.That you could mix-and-match them in one system. If you wanted maximum conventional performance, you put in 8 conventional Xeons. If you wanted maximum stream performance, you'd put in one "boot" conventional Xeon, and 7 of these. (At the time, there were also rumors that Itanium was going to be same-socket-and-platform, which now looks like it will come true.)