GTC 2012 Part 1: NVIDIA Announces GK104 Based Tesla K10, GK110 Based Tesla K20
by Ryan Smith on May 17, 2012 3:15 AM ESTThe other Tesla announced this week is Tesla K20, which is the first and so far only product announced that will be using GK110. Tesla K20 is not expected to ship until October-November of this year due to the fact that GK110 is still a work in progress, but since NVIDIA is once again briefing developers of the new capabilities of their leading compute GPU well ahead of time there’s little reason not to announce the card, particularly since they haven’t attached any solid specifications to it beyond the fact that it will be composed of a single GK110 GPU.

GK110 itself is a bit of a complex beast that we’ll get into more detail about later this week, but for now we’ll quickly touch upon some of the features that make GK110 the true successor to GF110. First and foremost of course, GK110 has all the missing features that GK104 lacked – ECC cache protection, high double precision performance, a wide memory bus, and of course a whole lot of CUDA Cores. Because GK110 is still in the lab NVIDIA doesn’t know what will be viable to ship later this year, but as it stands they’re expecting triple the double precision performance of Tesla M2090, with this varying some based on viable clockspeeds and how many functional units they can ship enabled. Single precision performance should also be very good, but depending on the application there’s a decent chance that K10 could beat K20, at least in the type of applications that are well suited for GK104’s limitations.
As it stands a complete GK110 is composed of 15 SMXes – note that these are similar but not identical to GK104 SMXes – bound to 1.5MB of L2 cache and a 384bit memory bus. GK110 SMXes will contain 192 CUDA cores (just like GK104), but deviating from GK104 they will contain 64 CUDA FP64 cores (up from 8, which combined with the much larger SMX count is what will make K20 so much more powerful at double precision math than K10. Of interesting note, NVIDIA is keeping the superscalar dispatch method that we first saw in GF104 and carried over to GK104, so unlike Fermi Tesla products, compute performance on K20 is going to be a little more erratic as a result of the fact that maximizing SMX utilization will require a high degree of both TLP and ILP.

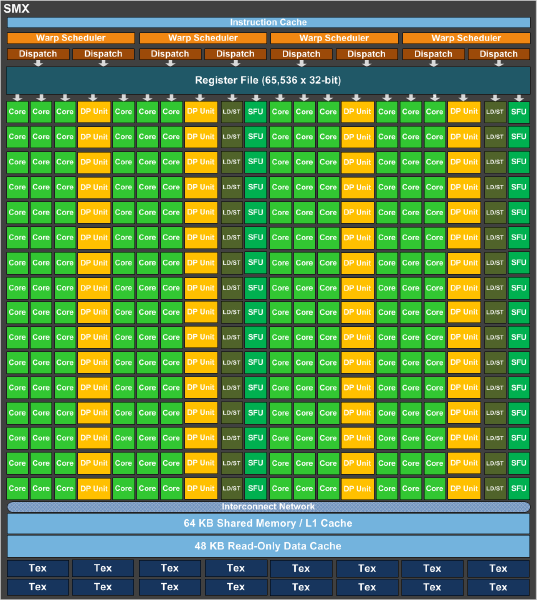
Along with the slew of new features native to the Kepler family and some new Kepler family compute instructions being unlocked with CUDA 5, GK110/K20 will be bringing with it two major new features that are unique to just GK110: Hyper-Q and Dynamic Parallelism. We’ll go over both of these in depth in the near future with our look at GK110, but for the time being we’ll quickly touch on what each of them does.
Hyper-Q is NVIDIA’s name for the expansion of the number of work queues in the GPU. With Fermi NVIDIA’s hardware only supported 1 hardware work queue, whereas GK110 will support 32 work queues. The important fact to take away from this is that 1 work queue meant that Fermi could be under occupied at times (that is, hardware units were left without work to do) if there wasn’t enough work in that queue to fill every SM, even with parallel kernels in play. By having 32 work queues to select from, GK110 can in many circumstances achieve higher utilization by being able to put different program streams on what would otherwise be an idle SMX.


The other major new feature here was Dynamic Parallelism, which is NVIDIA’s name for the ability for kernels to be able to dispatch other kernels. With Fermi only the CPU could dispatch a new kernel, which incurs a certain amount of overhead by having to communicate back and forth with the CPU. By giving kernels the ability to dispatch their own child kernels, GK110 can both save time by not having to go back to the GPU, and in the process free up the CPU to work on other tasks.
Wrapping things up, there are a few other features new to GK110 such as a new grid management unit, RDMA, and a new ISA encoding scheme, all of which are intended to further improve NVIDIA’s compute performance, both over Fermi and even GK104. But we’ll save these for another day when we look at GK110 in depth.








51 Comments
View All Comments
iwod - Thursday, May 17, 2012 - link
Would any upcoming article be analyzing that as well? I was thinking it would be extremely useful in Gaming Cafe, LAN Party and Arcade Center.Ryan Smith - Thursday, May 17, 2012 - link
We'll have more info on GPU virtualization later today. It's quite a bit to cover.CeriseCogburn - Wednesday, May 23, 2012 - link
Massive win.Hyper-Q and Dynamic Parallelism means Tesla can achieve near 100% utilization 24/7, with much less cpu power behind it required to do so, a huge value oriented upgrade.
That's what I call the best hardware designing, the best engineering, surpassing expectations, and delivering bang for the buck.
Amd is crying itself to sleep - and I'm starting to fear for them.
r3loaded - Thursday, May 17, 2012 - link
Is there a chance that Nvidia will release a consumer-grade GPU based on GK110? Something like a GTX 685 perhaps?tviceman - Thursday, May 17, 2012 - link
Geforce based GK110 cards will likely come Q1 2013. Nvidia will prioritize this product to the pro msrket first, and will move to retail after that to pit it against AMD's sea islands.chizow - Thursday, May 17, 2012 - link
I wouldn't be surprised if we see GK110 GeForce parts sooner than Tesla, as historically Nvidia has launched the GeForce parts first. I believe last round of rumors was September.This gives them more time to bin GK110 ASICs for functional units but more importantly, TDP and also gives them time to polish drivers expected of enterprise/professional parts.
PsiAmp - Saturday, May 19, 2012 - link
Nvidia can't solve the problems with their design under 28nm fab to improve yields till the end of the year as Huang stated.GK110 is much bigger than GK104 so yield problem is marked even more. Knowing that they will have a limited production for some time it is wiser to release it to the market where it will get higher profits. And it is HPC market. So no, we won't see GK110 in consumer cards this year.
CeriseCogburn - Saturday, May 19, 2012 - link
You mean TSMC doesn't have enough wafer starts and building out several extra billion dollars of infrastructure injected recently doesn't happen overnight.With such great demand as we've already seen on 680 and now 670, it will sell out while amd 79xx and 78xx sit on the shelves.
CeriseCogburn - Saturday, May 19, 2012 - link
chizow's theory on massive pre-overclocking of the 680 is now laughable - as we see 745MHz for the "new core" speed.Maybe a few of you could instead start claiming nVidia "held back the slow, unable to achieve HARVESTED " cores for their new K10's, since the cores only hit 745MHz stable.
Quite unlike the "defective and harvested 670 cores" that hit 915 980 or 1006 core on release, as so many of you bleated.
I think that's great nVidia is using defective "harvested" cores for their new $,2,000.00 plus K10 Tesla line - what a way to make huge profit $$$ on bad, slow, leaky parts, huh !
(rolls eyes again at the idiotic attack bleating)
elajt_1 - Friday, May 18, 2012 - link
I'll be suprised if we ever see a GK110 part in a Geforce card. Why would Nvidia sell these as graphicscards? Harder to manufacture, much more expensive because of that (e.g lower yields and less gpu's on a wafer), a big probability of horrible margins (for obvious reasons). And lastly, a big chance that chip won't be able to clock very high since it's likely/potentially even bigger than GF100.There is also a big possibility the GK110 won't improve much (graphic wise) over the existing GK104. If I understood anything from the above article, the chip is not optimised for gaming, which makes it even more unlikely they'll go in that direction.
Just my two cents.