AMD Threadripper Pro Review: An Upgrade Over Regular Threadripper?
by Dr. Ian Cutress on July 14, 2021 9:00 AM EST- Posted in
- CPUs
- AMD
- ThreadRipper
- Threadripper Pro
- 3995WX
CPU Tests: Encoding
One of the interesting elements on modern processors is encoding performance. This covers two main areas: encryption/decryption for secure data transfer, and video transcoding from one video format to another.
In the encrypt/decrypt scenario, how data is transferred and by what mechanism is pertinent to on-the-fly encryption of sensitive data - a process by which more modern devices are leaning to for software security.
Video transcoding as a tool to adjust the quality, file size and resolution of a video file has boomed in recent years, such as providing the optimum video for devices before consumption, or for game streamers who are wanting to upload the output from their video camera in real-time. As we move into live 3D video, this task will only get more strenuous, and it turns out that the performance of certain algorithms is a function of the input/output of the content.
HandBrake 1.32: Link
Video transcoding (both encode and decode) is a hot topic in performance metrics as more and more content is being created. First consideration is the standard in which the video is encoded, which can be lossless or lossy, trade performance for file-size, trade quality for file-size, or all of the above can increase encoding rates to help accelerate decoding rates. Alongside Google's favorite codecs, VP9 and AV1, there are others that are prominent: H264, the older codec, is practically everywhere and is designed to be optimized for 1080p video, and HEVC (or H.265) that is aimed to provide the same quality as H264 but at a lower file-size (or better quality for the same size). HEVC is important as 4K is streamed over the air, meaning less bits need to be transferred for the same quality content. There are other codecs coming to market designed for specific use cases all the time.
Handbrake is a favored tool for transcoding, with the later versions using copious amounts of newer APIs to take advantage of co-processors, like GPUs. It is available on Windows via an interface or can be accessed through the command-line, with the latter making our testing easier, with a redirection operator for the console output.
We take the compiled version of this 16-minute YouTube video about Russian CPUs at 1080p30 h264 and convert into three different files: (1) 480p30 ‘Discord’, (2) 720p30 ‘YouTube’, and (3) 4K60 HEVC.
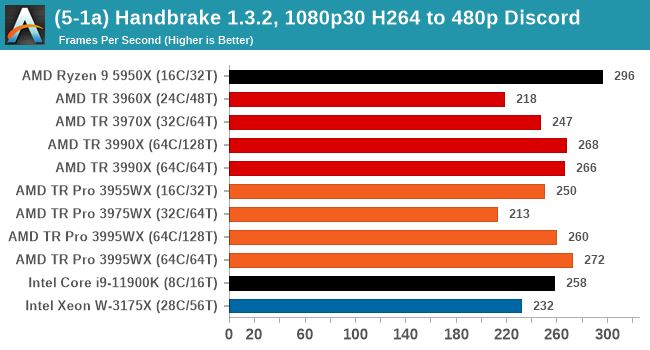
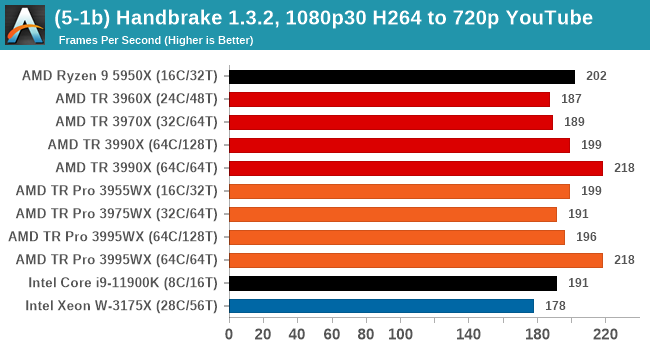
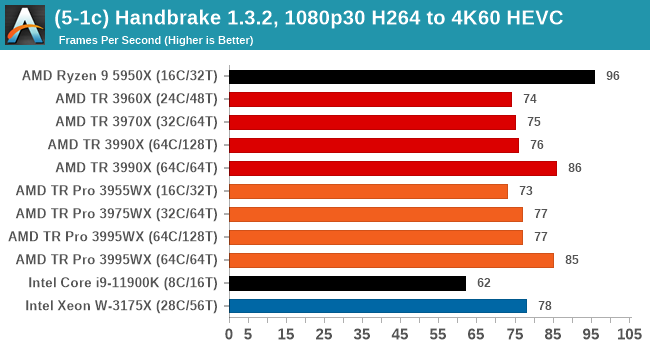
In every situation the R9 5950X does the best or near the best, but HB is one of those tests where running in 64C/64T mode does benefit the result by a good 10%. Otherwise there is little difference between TR and TR Pro.
7-Zip 1900: Link
The first compression benchmark tool we use is the open-source 7-zip, which typically offers good scaling across multiple cores. 7-zip is the compression tool most cited by readers as one they would rather see benchmarks on, and the program includes a built-in benchmark tool for both compression and decompression.
The tool can either be run from inside the software or through the command line. We take the latter route as it is easier to automate, obtain results, and put through our process. The command line flags available offer an option for repeated runs, and the output provides the average automatically through the console. We direct this output into a text file and regex the required values for compression, decompression, and a combined score.
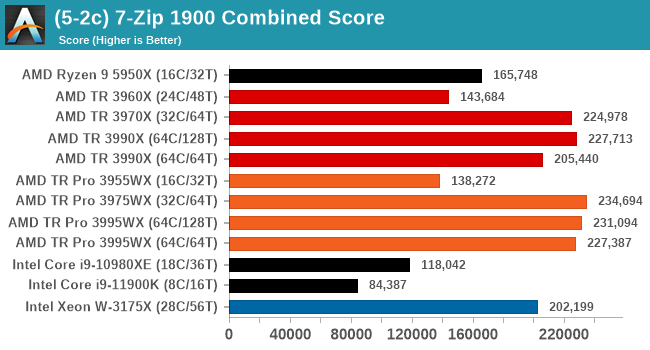
7-zip tends to like memory bandwidth as well as compute, however this test seems to top out at 64 threads, so any processor above that is scoring roughly the same. The 3990X result seems a little low, however.
AES Encoding
Algorithms using AES coding have spread far and wide as a ubiquitous tool for encryption. Again, this is another CPU limited test, and modern CPUs have special AES pathways to accelerate their performance. We often see scaling in both frequency and cores with this benchmark. We use the latest version of TrueCrypt and run its benchmark mode over 1GB of in-DRAM data. Results shown are the GB/s average of encryption and decryption.
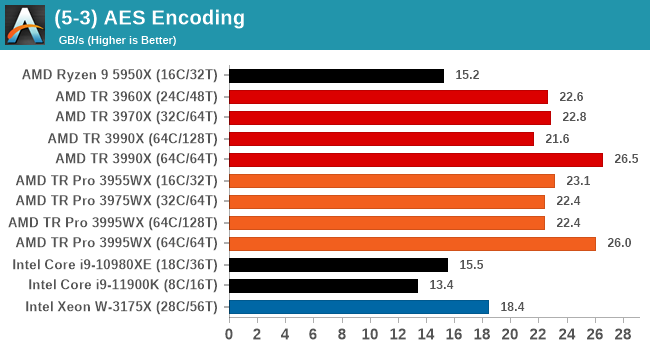
AES does like memory bandwidth, and the 64C/64T setting does best here.
WinRAR 5.90: Link
For the 2020 test suite, we move to the latest version of WinRAR in our compression test. WinRAR in some quarters is more user friendly that 7-Zip, hence its inclusion. Rather than use a benchmark mode as we did with 7-Zip, here we take a set of files representative of a generic stack
- 33 video files , each 30 seconds, in 1.37 GB,
- 2834 smaller website files in 370 folders in 150 MB,
- 100 Beat Saber music tracks and input files, for 451 MB
This is a mixture of compressible and incompressible formats. The results shown are the time taken to encode the file. Due to DRAM caching, we run the test for 20 minutes times and take the average of the last five runs when the benchmark is in a steady state.
For automation, we use AHK’s internal timing tools from initiating the workload until the window closes signifying the end. This means the results are contained within AHK, with an average of the last 5 results being easy enough to calculate.
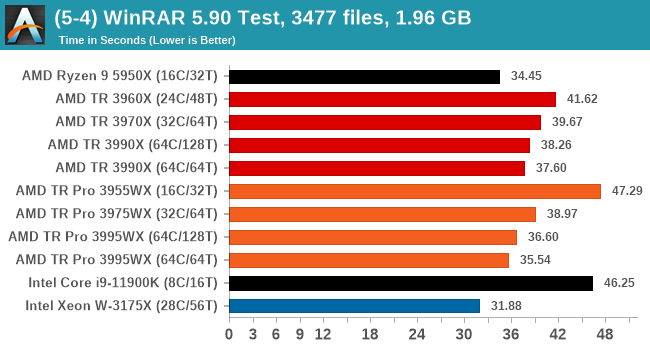
In this test we're looking for the smallest bars representing the lowest time, and 64C/64T has a slight advantage over the full 128T modes. There seems to be no real difference between TR and TR Pro here though - normally WinRAR likes having memory bandwidth, but it seems that there is enough to go around.








98 Comments
View All Comments
Mikewind Dale - Wednesday, July 14, 2021 - link
I have a ThreadRipper Pro 3955WX, and I discovered something interesting about the memory bandwidth.Originally, I bought 4x64 GB ECC RDIMM because I thought 256 GB might be enough, and I wanted to leave some empty RAM slots to populate with 128 GB RDIMMs if those ever became cost-effective. (Right now, 128 GB RDIMMs are about triple the price of 64 GB.)
CPU-Z and AIDA64 reported "quad" channel memory, and AIDA64's memory benchmarks showed reasonable memory performance.
But I discovered that 256 GB wasn't enough for my application, so I bought 2 more 64 GB RDIMMs.
At this point, I had 6 DIMMs populated. CPU-Z and AIDA64 both reported "hexa" channel memory, but AIDA64's memory benchmarks showed that my memory performance was about 2/3 that of a Ryzen.
So I bought 2 more RDIMMs again, for a total of 8. Now, my memory benchmark in AIDA64 is much closer to expected.
So the moral of the story is: you can populate 4 DIMMs, or you can populate 8, but don't dare populate 6. Populating precisely 6 DIMMs will absolutely cripple your memory performance, whereas 4 DIMMs still have acceptable performance.
kobblestown - Wednesday, July 14, 2021 - link
The 3955 probably has only 2 CCDs and is therefore limited to 4 DDR channels throughput. It seems that each IF link has the throughput of 2 DDR channels and this makes sense.You should keep in mind that the IO die has in effect 4 dual channel controllers and you may have populated them suboptimally. If you have two dual channel controllers fully populated and two half populated (instead of a third fully populated and the fourth one staying empty) you'll have skewed results. Also, there was some noise about Milan working better with 6 channel configurations so it may be something specific to Rome chips.
Rudde - Wednesday, July 14, 2021 - link
Server providers had requested for 6 channel memory support for server processors and that was implemented in Milan.McFig - Wednesday, July 14, 2021 - link
What kobblestown is suggesting is that maybe Mikewind Dale could have gotten the 6 RDIMMs working by moving one of them so that each pair is fully populated.Mikewind Dale - Wednesday, July 14, 2021 - link
McFig, there are only 8 slots, so I'm not sure how I could have moved the 6 DIMMs among the 8 slots to ensure that each pair is populated.1_rick - Wednesday, July 14, 2021 - link
He probably means "each of 3 pairs fully populated".DougMcC - Wednesday, July 14, 2021 - link
I think the question is whether 3/3 is better than 4/2kobblestown - Friday, July 16, 2021 - link
Heya! Sorry for the nebulous formulation. In terms of the number of DIMMS per memory controller, I suggest having 2+2+2+0 instead of 2+1+2+1. One needs to figure out what this means for any particular MB. But as DougMcC suggests, that would probably mean having 4 DIMMs on one side of the CPU and 2 on the other, rather than having 3 DIMMs on each side. The latter is bound to be suboptimal. Whether the former offers an improvement is something that I would be very interested to know but could be that Rome has some shortcoming in this area which is addressed in Milan.Again, dual CCD configurations are limited to 4 channel bandwidth but it's still worth it to have all channels populated so you don't get bitten by badly handled assymetry and the IO does not fight (too much) with the cores for the bandwidth.
kobblestown - Friday, July 16, 2021 - link
BTW, one should also check the memory interleaving options in the UEFI. Maybe the way the IO die aggregates the memory channels can be tweaked to achive the expected performance even with 6 DIMMs. Or maybe that's only achievable with Milan.Mikewind Dale - Friday, July 16, 2021 - link
Ahhh, I see what you mean. Thanks. Well, I have 8 DIMMs now, and I don't want to mess with my system any more. Maybe Anandtech can test this.