AMD 3rd Gen EPYC Milan Review: A Peak vs Per Core Performance Balance
by Dr. Ian Cutress & Andrei Frumusanu on March 15, 2021 11:00 AM ESTDisclaimer June 25th: The benchmark figures in this review have been superseded by our second follow-up Milan review article, where we observe improved performance figures on a production platform compared to AMD’s reference system in this piece.
Compiling LLVM, NAMD Performance
As we’re trying to rebuild our server test suite piece by piece – and there’s still a lot of work go ahead to get a good representative “real world” set of workloads, one more highly desired benchmark amongst readers was a more realistic compilation suite. Chrome and LLVM codebases being the most requested, I landed on LLVM as it’s fairly easy to set up and straightforward.
git clone https://github.com/llvm/llvm-project.gitcd llvm-projectgit checkout release/11.xmkdir ./buildcd ..mkdir llvm-project-tmpfssudo mount -t tmpfs -o size=10G,mode=1777 tmpfs ./llvm-project-tmpfscp -r llvm-project/* llvm-project-tmpfscd ./llvm-project-tmpfs/buildcmake -G Ninja \ -DLLVM_ENABLE_PROJECTS="clang;libcxx;libcxxabi;lldb;compiler-rt;lld" \ -DCMAKE_BUILD_TYPE=Release ../llvmtime cmake --build .We’re using the LLVM 11.0.0 release as the build target version, and we’re compiling Clang, libc++abi, LLDB, Compiler-RT and LLD using GCC 10.2 (self-compiled). To avoid any concerns about I/O we’re building things on a ramdisk. We’re measuring the actual build time and don’t include the configuration phase as usually in the real world that doesn’t happen repeatedly.
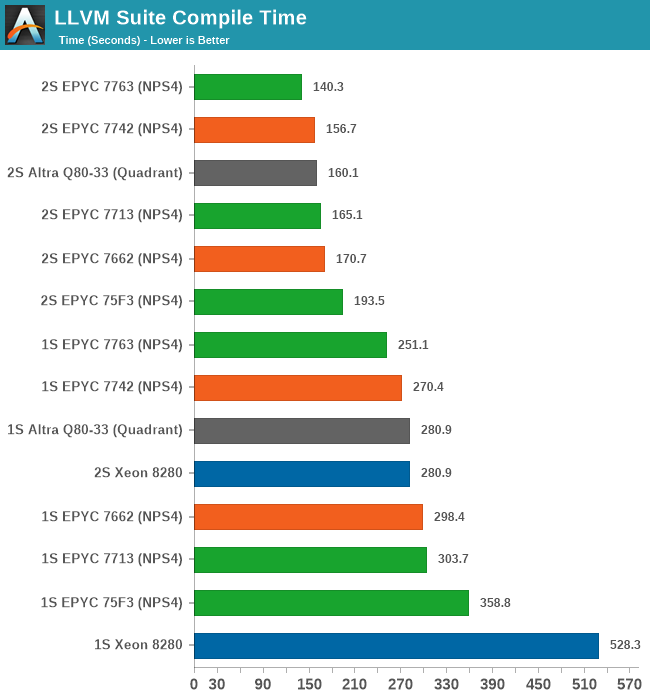
For the new Milan chips, the results are a bit mixed. The higher-power 7763 takes a lead with a +10.5% improvement over the 7742, however the 7713 doesn’t manage to keep up with that predecessor.
The 1S vs 2S scores are interesting as the 2S figures showcase the new Milan chips in a better light due to the higher single-threaded performance of the Zen3 cores. The compilation here also has linking phases which are single-thread performance bottle-necked. This results in scenarios such as the 7713 losing to the 7662 in 1S comparisons, however winning out against the same chip in the 2S comparison, as it’s able to make that advantage count for more.
It’s also great to see the 75F3 keep up with the 64-core counterparts at around 72% of the top-SKU performance.
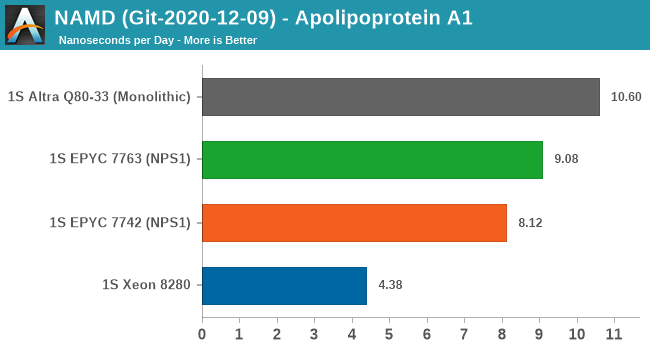
Finally, in NAMD, this is more of a core-local compute workload. We see the 7763 outperform the 7742 by +11.8%, however the Milan chip is still outperformed by the higher core compute capacity of the 80-core Altra chip.
Generally, I have my reservations about NAMD as a benchmark due to its multicore vs MPI variants and scaling anomalies, on top of the whole topic of the benchmark having a completely different algorithm for AVX512 processors.








120 Comments
View All Comments
Memo.Ray - Monday, March 15, 2021 - link
Thanks for the excellent review team Anand!ballsystemlord - Monday, March 15, 2021 - link
Actually, it was Ian and Andrei, not Anand who did the review. I'm not joking, he's a real person who used to work on this site: https://www.anandtech.com/print/1635/velanapontinha - Monday, March 15, 2021 - link
He was not addressing Anand. He is adressing "team Anand" which obviouisly means "the people actually workin on Anandtech"ballsystemlord - Monday, March 15, 2021 - link
I was thinking of a one person (Anand) team. ;)I should have gotten what he said though.
Gothmoth - Monday, March 15, 2021 - link
Team Anand! Since when is a team a single person....bigboxes - Tuesday, March 16, 2021 - link
He didn't get that. Must have missed the "team"plonk420 - Monday, March 22, 2021 - link
yeah, he was a bit too excited to ACKCHYUALLY someone elseSharma_Ji - Wednesday, March 17, 2021 - link
Who used to work - lolHe is the co founder lol
herozeros - Thursday, March 18, 2021 - link
definitely didn't think comment lurking would make me feel old today. lolMemo.Ray - Monday, March 15, 2021 - link
I know my English is a "lil" rough on the edges but I gotta admit, I didn't see these comments coming! lol.