The NVIDIA Turing GPU Architecture Deep Dive: Prelude to GeForce RTX
by Nate Oh on September 14, 2018 12:30 PM ESTTuring Tensor Cores: Leveraging Deep Learning Inference for Gaming
Though RT Cores are Turing’s poster child feature, the tensor cores were very much Volta’s. In Turing, they’ve been updated, reflecting its positioning as a gaming/consumer feature via inferencing. The main changes for the 2nd generation tensor cores are INT8 and INT4 precision modes for inferencing, enabled by new hardware data paths, and perform dot products to accumulate into an INT32 product. INT8 mode operates at double the FP16 rate, or 2048 integer operations per clock. INT4 mode operates at quadruple the FP16 rate, or 4096 integer ops per clock.

Naturally, only some networks tolerate these lower precisions and any necessary quantization, meaning the storage and calculation of compacted format data. INT4 is firmly in the research area, whereas INT8’s practical applicability is much more developed. Regardless, the 2nd generation tensor cores still have FP16 mode, which they now support in a pure FP16 mode without FP32 accumulator. While CUDA 10 is not yet out, the enhanced WMMA operations should shed light on any other differences, such as additional accepted matrix sizes for operands.
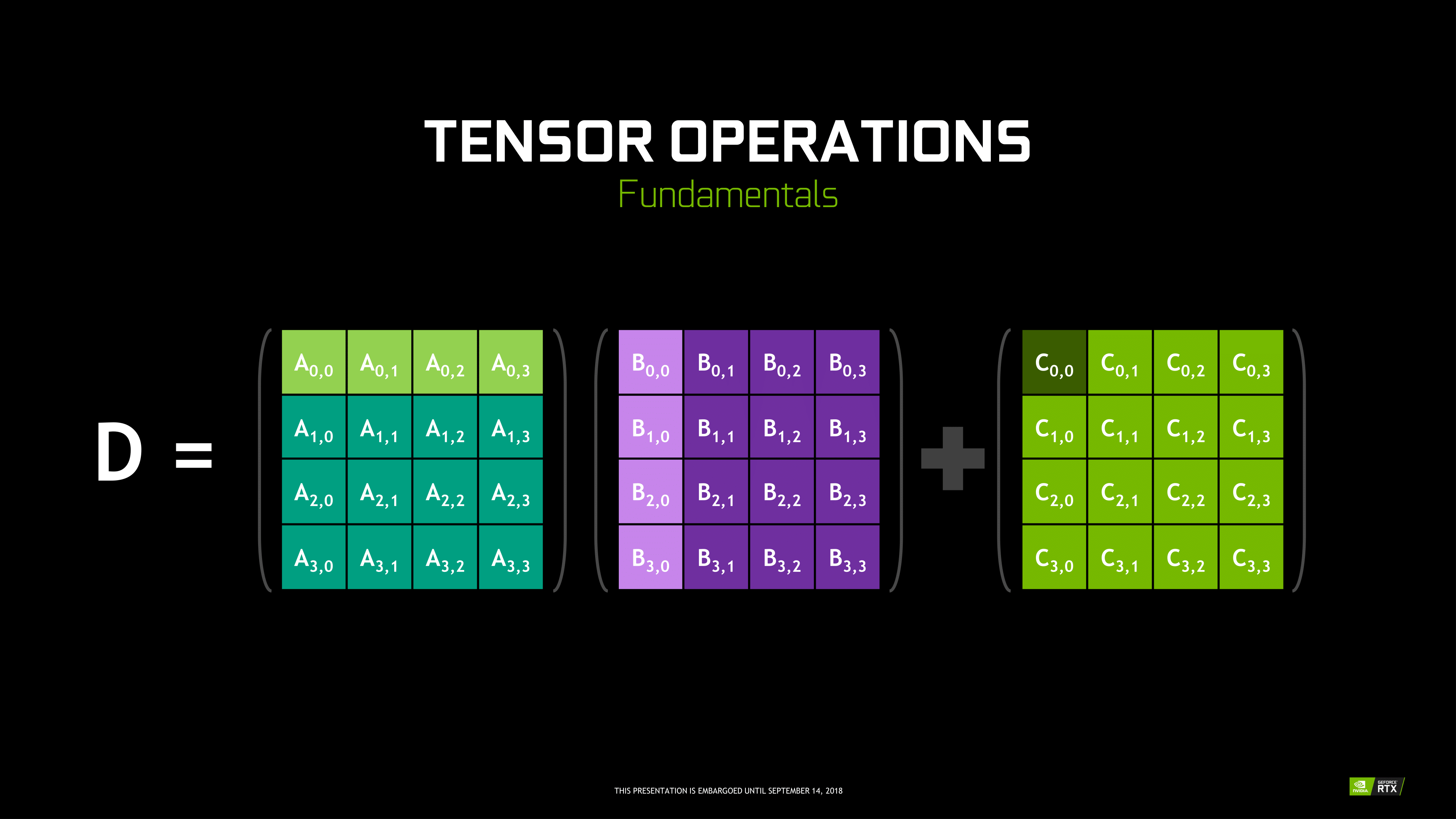
Inasmuch as deep learning is involved, NVIDIA is pushing what was a purely compute/professional feature into consumer territory, and we will go over the full picture in a later section. For Turing, the tensor cores can accelerate the features under the NGX umbrella, which includes DLSS. They can also accelerate certain AI-based denoisers that cleanup and correct real time raytraced rendering, though most developers seem to be opting for non-tensor core accelerated denoisers at the moment.








111 Comments
View All Comments
xXx][Zenith - Friday, September 14, 2018 - link
Nice write-up! With 25% of the chip area dedicated to Tensor Cores and other 25% to RT Cores NVIDIA is betting big on DLSS and RTX for gaming usecases. With all the architectural improvements, better memory compression ... AMD is out of the game, quite frankly.Btw, for the fans of GigaRays/Sec, aka CEO metric, here is a Optix-RTX benchmark for Volta, Pascal and Maxwell GPUs: https://www.youtube.com/watch?v=ULtXYzjGogg
OptiX 5.1 API will work with Turing GPUs but will not take advantage of the new RT Cores, so older-gen NV GPUs can be directly compared to Turing. Application devs need to rebuild with Optix 5.2 to get access to HW accelarated ray tracing. Imho, RTX cards will have nice speedup with Turing RT Cores using GPU renderers (Octane, VRay, ...) but the available RAM will limit the scene complexity big time.
blode - Friday, September 14, 2018 - link
hate when i lose a game before my opponent arriveseddman - Friday, September 14, 2018 - link
As far as I can tell, GigaRays/Sec is not an nvidia made term. It's been used before by others too, like imagination tech.The nvidia made up term is RTX-ops.
xXx][Zenith - Friday, September 14, 2018 - link
Ray tracing metric without scene complexity, viewport placement is just smoke and mirrors ...From whitepaper: "Turing ray tracing performance with RT Cores is significantly faster than ray tracing in Pascal GPUs. Turing can deliver far more Giga Rays/Sec than Pascal on different workloads, as shown in Figure 19. Pascal is spending approximately 1.1 Giga Rays/Sec, or 10 TFLOPS / Giga Ray to do ray tracing in software, whereas Turing can do 10+ Giga Rays/Sec using RT Cores, and run ray tracing 10 times faster."
eddman - Saturday, September 15, 2018 - link
I don't know the technical details of ray tracing, but how is that nvidia statement related to scene complexity, etc?From my understanding of that statement, they are simply saying that turing is able to deliver far more rays/sec than pascal, because it is basically hardware-accelerating the operations through RT cores but pascal has to do all those operations in software through regular shader cores.
niva - Wednesday, September 19, 2018 - link
If you hold scene complexity constant (take the same environment/angle) and run a ray tracing experiment, the new hardware will be that much faster at cranking out frames. At least that's how I'm interpreting the article and the statement above, I'm not really sure if that's accurate though...Yojimbo - Saturday, September 15, 2018 - link
When did Imgtec use gigarays? As far as I remember they didn't have hardware capable of a gigaray. They measured in hundreds of millions of rays per second, and I don't remember them using the term "megaray", either. Just something along the lines of "200 million rays/sec".eddman - Saturday, September 15, 2018 - link
Why fixate on the "giga" part? I obviously meant rays/sec; forgot top remove the giga part after copy/paste. A measuring method doesn't change with quantity.Yojimbo - Saturday, September 15, 2018 - link
Because the prefix is the whole point. The point is the terminology, not the measuring method. Rays per second is pretty obvious and has probably been around since the 70s. The "CEO metric" the OP was talking about was specifically about "gigarays per second". Jensen Huang said it during his SIGGRAPH presentation. Something like "Here's something you probably haven't heard before. Gigarays. We have gigarays."eddman - Saturday, September 15, 2018 - link
What are you on about? He meant "giga" as in "billion". It's so simple. He said it that way to make it sound impressive.