The Intel Optane SSD DC P4800X (375GB) Review: Testing 3D XPoint Performance
by Billy Tallis on April 20, 2017 12:00 PM ESTSequential Read
Intel provides no specifications for sequential access performance of the Optane SSD DC P4800X. Buying an Optane SSD for a mostly sequential workload would make very little sense given that sufficiently large flash-based SSDs or RAID arrays can offer plenty of sequential throughput. Nonetheless, it will be interesting to see how much faster the Optane SSD is with sequential transfers instead of random access.
Sequential access is usually tested with 128kB transfers, but this is more of an industry convention and is not based on any workload trend as strong as the tendency for random I/Os to be 4kB. The point of picking a size like 128kB is to have transfers be large enough that they can be striped across multiple controller channels and still involve writing a full page or more to the flash on each channel. Real-world sequential transfer sizes vary widely depending on factors like which application is moving the data or how fragmented the filesystem is.
Even without a large native page size to its 3D XPoint memory, we expect the Optane SSD DC P4800X to exhibit good performance from larger transfers. A large transfer requires the controller to process fewer operations for the same amount of user data, and fewer operations means less protocol overhead on the wire. Based on the random access tests, it appears that the Optane SSD is internally managing the 3D XPoint memory in a way that greatly benefits from transfers being at least 4kB even though the drive emulates a 512B sector size out of the box.
The drives were preconditioned with two full writes using 4kB random writes, so the data on each drive is entirely fragmented. This may limit how much prefetching of user data the drives can perform on the sequential read tests, but they can likely benefit from better locality of access to their internal mapping tables.
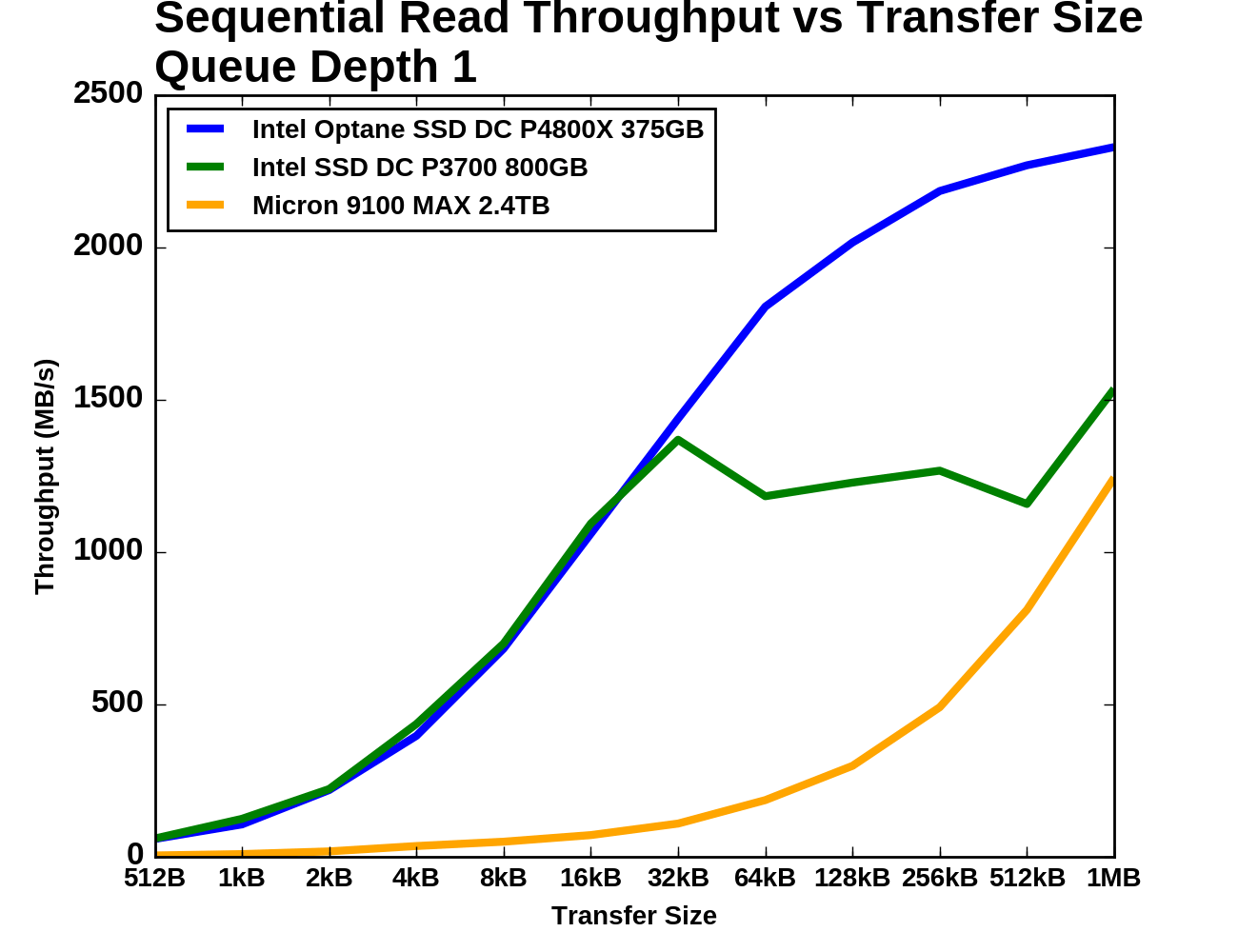
Queue Depth 1
The test of sequential read performance at different transfer sizes was conducted at queue depth 1. Each transfer size was used for four minutes, and the throughput was averaged over the final three minutes of each test segment.
 |
|||||||||
| Vertical Axis scale: | Linear | Logarithmic | |||||||
For transfer sizes up to 32kB, both Intel drives deliver similar sequential read speeds. Beyond 32kB the P3700 appears to be saturated but also highly inconsistent. The Micron 9100 is plodding along with very low but steadily growing speeds, and by the end of the test it has almost caught up with the Intel P3700. It was at least ten times slower than the Optane SSD until the transfer size reached 64kB. The Optane SSD passes 2GB/s with 128kB transfers and finishes the test at 2.3GB/s.
Queue Depth > 1
For testing sequential read speeds at different queue depths, we use the same overall test structure as for random reads: total queue depths of up to 64 are tested using a maximum of four threads. Each thread is reading sequentially but from a different region of the drive, so the read commands the drive receives are not entirely sorted by logical block address.
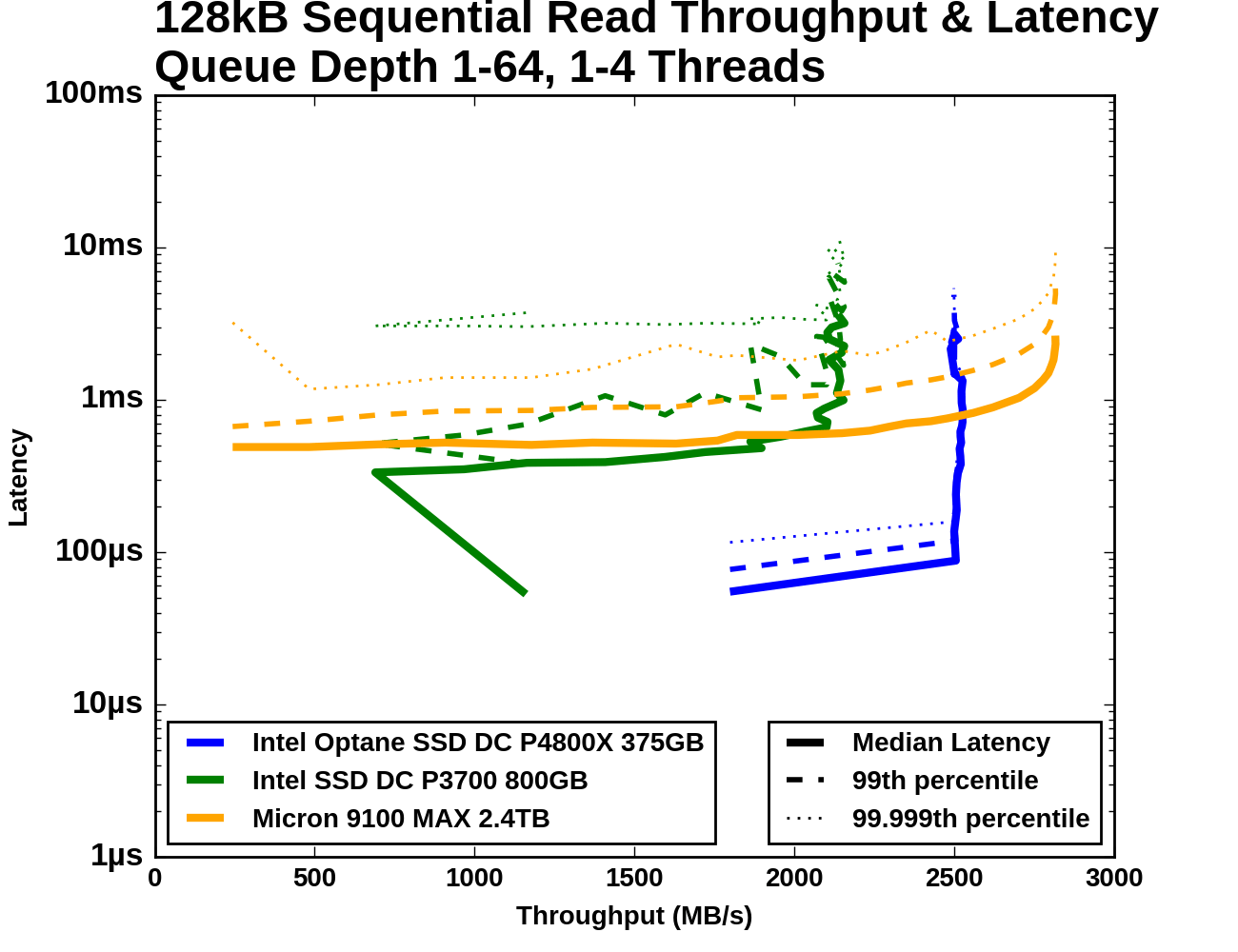
The Optane SSD DC P4800X starts out with a far higher QD1 sequential read speed than either flash SSD can deliver. The Optane SSD's median latency at QD1 is not significantly better than what the Intel P3700 delivers, but the P3700's 99th and 99.999th percentile latencies are at least an order of magnitude worse. Beyond QD1, the Optane SSD saturates while the Intel P3700 takes a temporary hit to throughput and a permanent hit to latency. The Micron 9100 starts out with low throughput and fairly high latency, but with increasing queue depth it manages to eventually surpass the Optane SSD's maximum throughput, albeit with ten times the latency.
 |
|||||||||
| Vertical Axis units: | IOPS | MB/s | |||||||
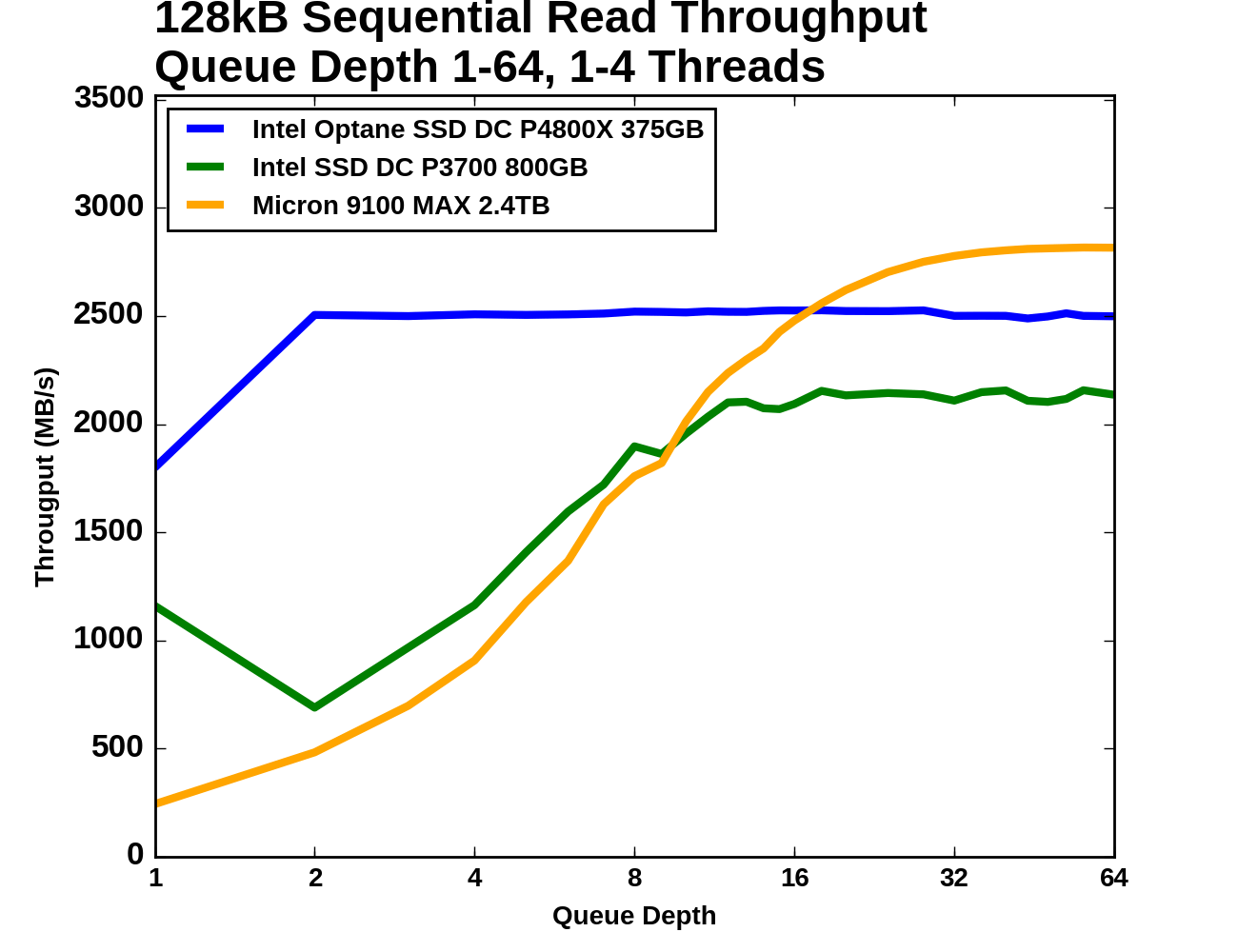
The Intel Optane SSD DC P4800X starts this test at 1.8GB/s for QD1, and delivers 2.5GB/s at all higher queue depths. The Intel P3700 performs significantly worse when a second QD1 thread is introduced, but by the time there are four threads reading from the drive the total throughput has recovered. The Intel P3700 saturates a little past QD8, which is where the Micron 9100 passes it. The Micron 9100 then goes on to surpass the Optane SSD's throughput above QD16, but it too has saturated by QD64.
 |
|||||||||
| Mean | Median | 99th Percentile | 99.999th Percentile | ||||||
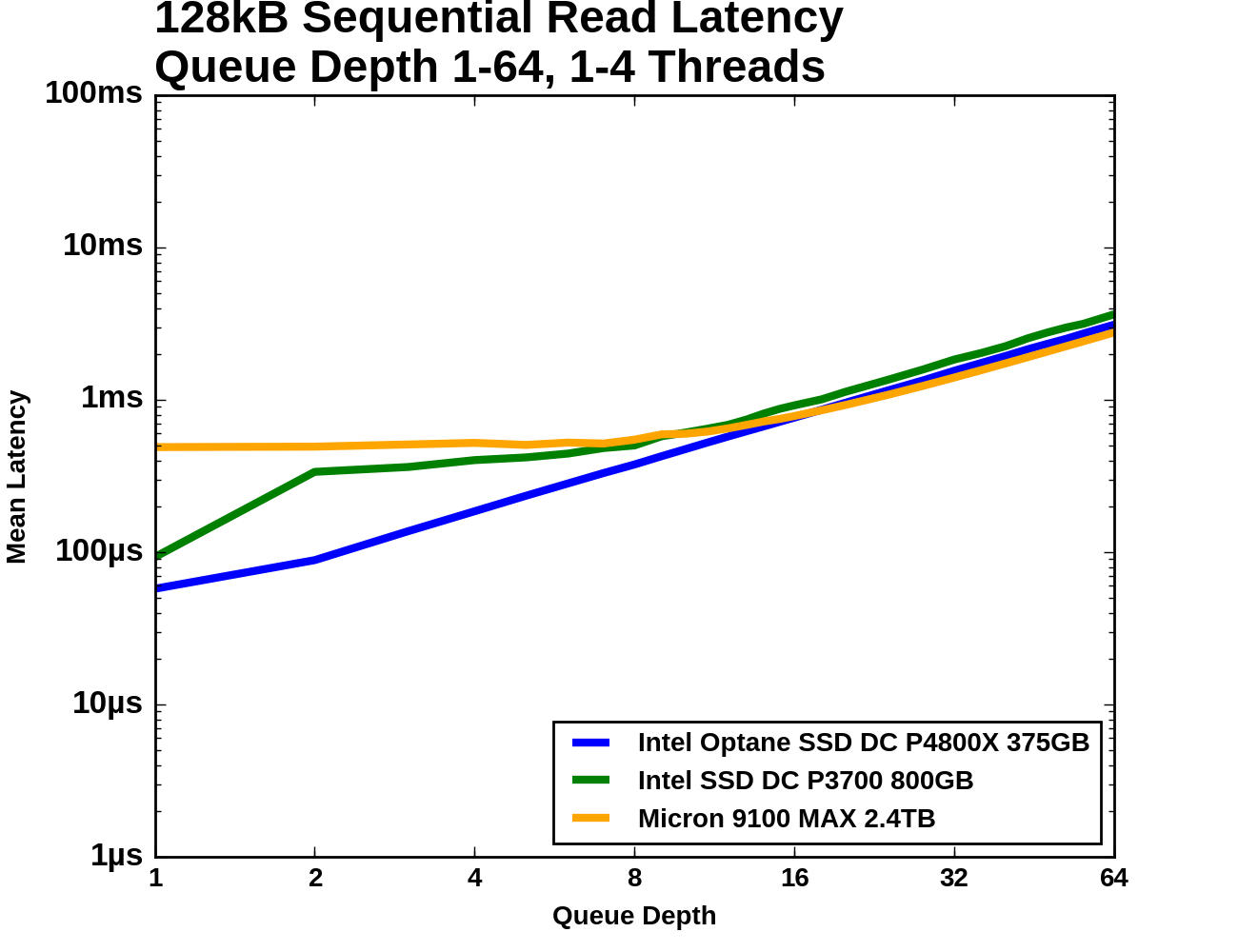
The Optane SSD's latency increases modestly from QD1 to QD2, and then unavoidably increases linearly with queue depth due to the drive being saturated and unable to offer any better throughput. The Micron 9100 starts out with almost ten times the average latency, but is able to hold that mostly constant as it picks up most of its throughput. Once the 9100 passes the Optane SSD in throughput it is delivering slightly better average latency, but substantially higher 99th and 99.999th percentile latencies. The Intel P3700's 99.999th percentile latency is the worst of the three across almost all queue depths, and its 99th percentile latency is only better than the Micron 9100's during the early portions of the test.
Sequential Write
The sequential write tests are structured identically to the sequential read tests save for the direction the data is flowing. The sequential write performance of different transfer sizes is conducted with a single thread operating at queue depth 1. For testing a range of queue depths, a 128kB transfer size is used and up to four worker threads are used, each writing sequentially but to different portions of the drive. Each sub-test (transfer size or queue depth) is run for four minutes and the performance statistics ignore the first minute.
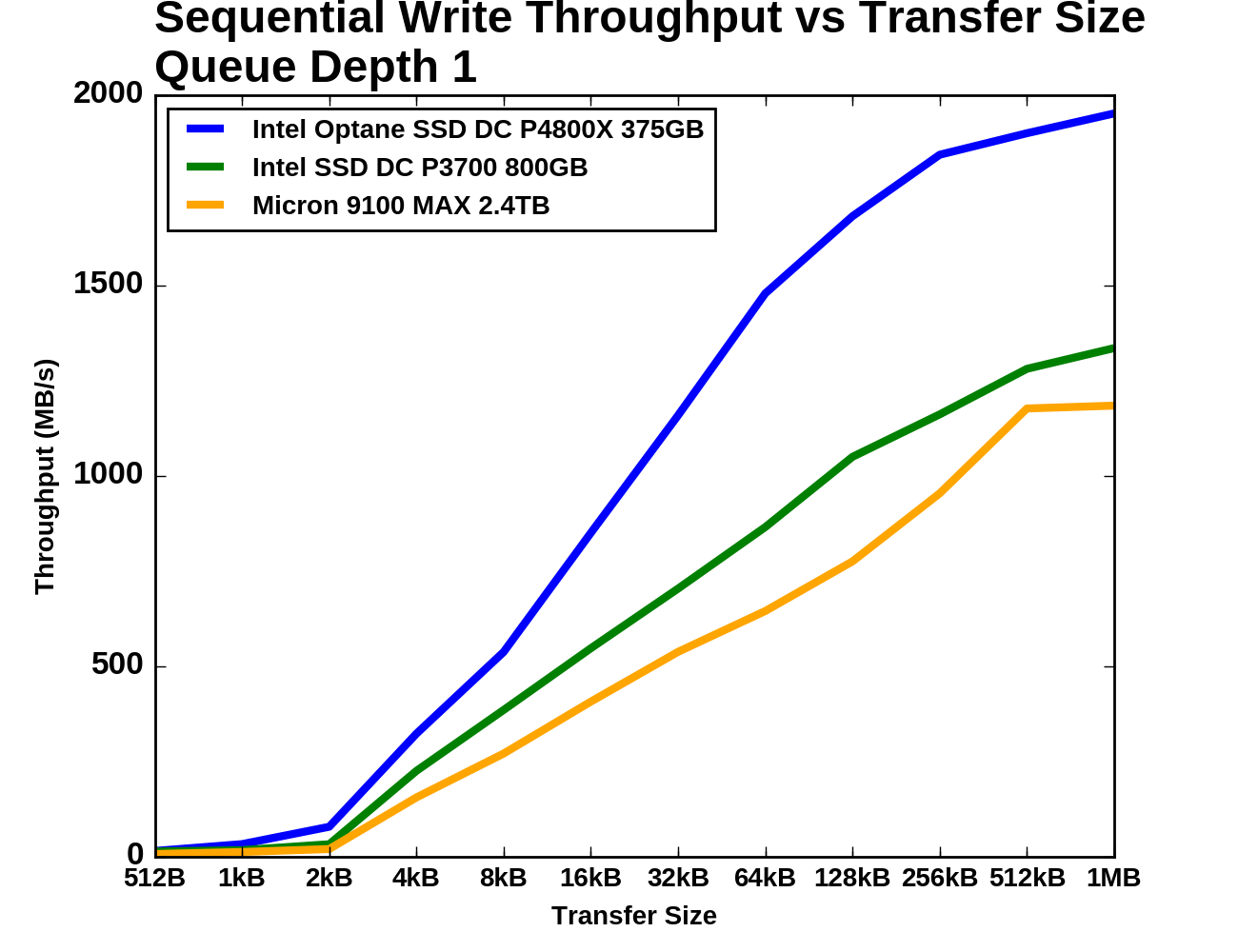 |
|||||||||
| Vertical Axis scale: | Linear | Logarithmic | |||||||
As with random writes, sequential write performance doesn't begin to take off until transfer sizes reach 4kB. Below that size, all three SSDs offer dramatically lower throughput, with the Optane SSD narrowly ahead of the Intel P3700. The Optane SSD shows the steepest growth as transfer size increases, but it and the Intel P3700 begin to show diminishing returns beyond 64kB. The Optane SSD almost reaches 2GB/s by the end of the test while the Intel P3700 and the Micron 9100 reach around 1.2-1.3GB/s.
Queue Depth > 1
When testing sequential writes at varying queue depths, the Intel SSD DC P3700's performance was highly erratic. We did not have sufficient time to determine what was going wrong, so its results have been excluded from the graphs and analysis below.
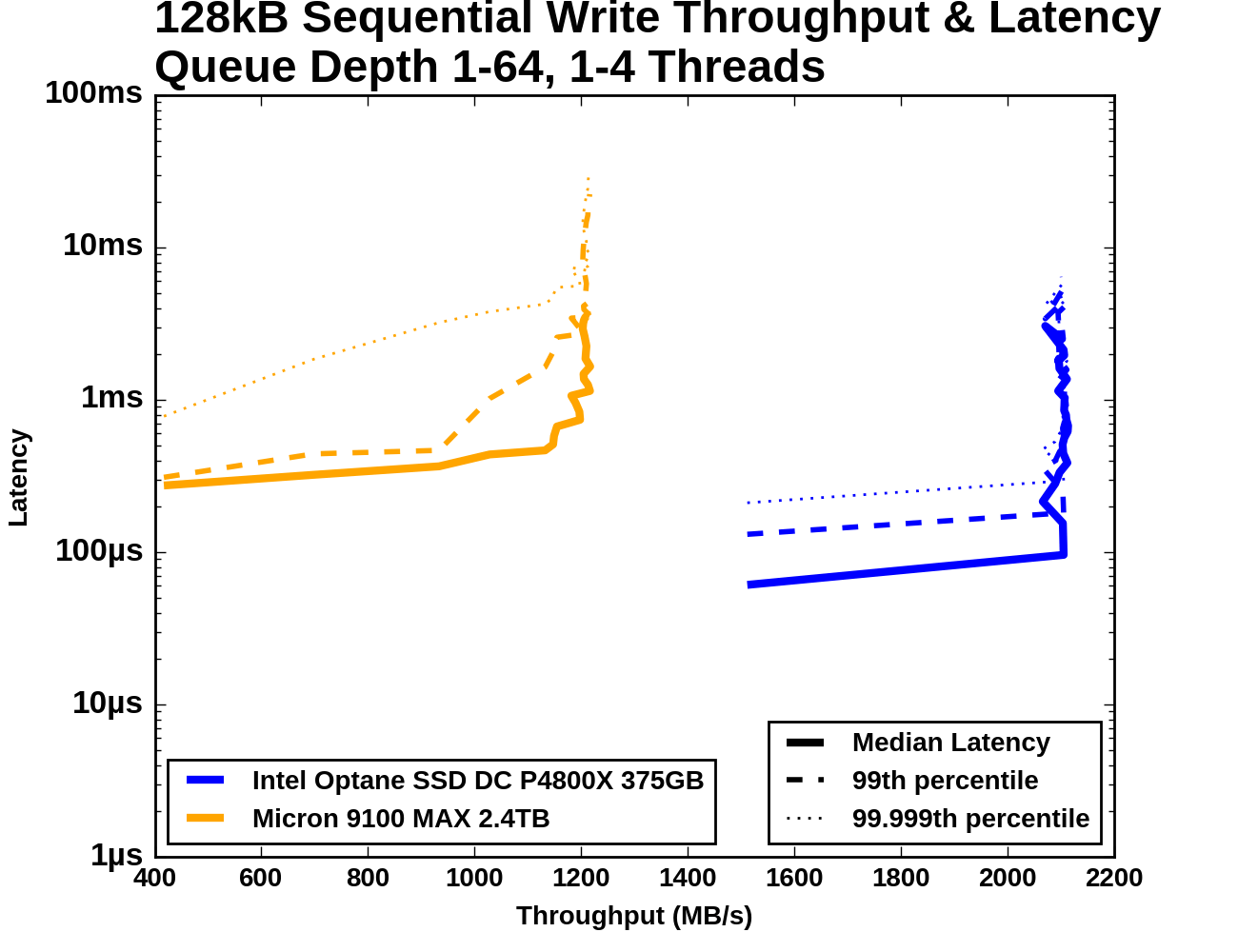
The Optane SSD DC P4800X delivers better sequential write throughput at every queue depth than the Micron 9100 can deliver at any queue depth. The Optane SSD's latency increases only slightly as it reaches saturation while the Micron 9100's 99th percentile latency begins to climb steeply well before that drive reaches its maximum throughput. The Micron 9100's 99.999th percentile latency also grows substantially as throughput increases, but its growth is more evenly spread across the range of queue depths.
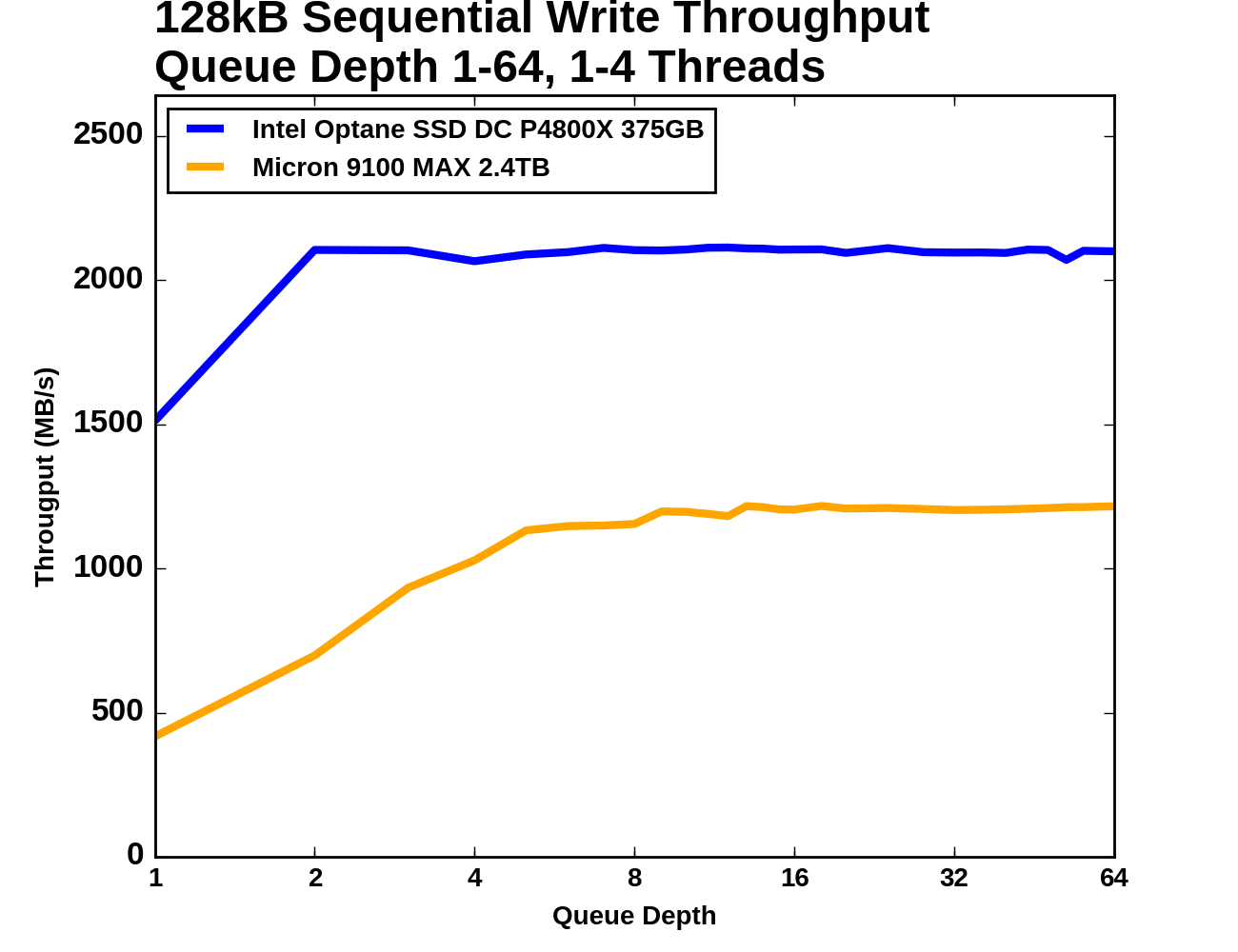 |
|||||||||
| Vertical Axis units: | IOPS | MB/s | |||||||
The Optane SSD reaches its maximum throughput at QD2 and maintains it as more threads and higher queue depths are introduced. The Micron 9100 only provides a little over half of the throughput and requires a queue depth of around 6-8 to reach that performance.
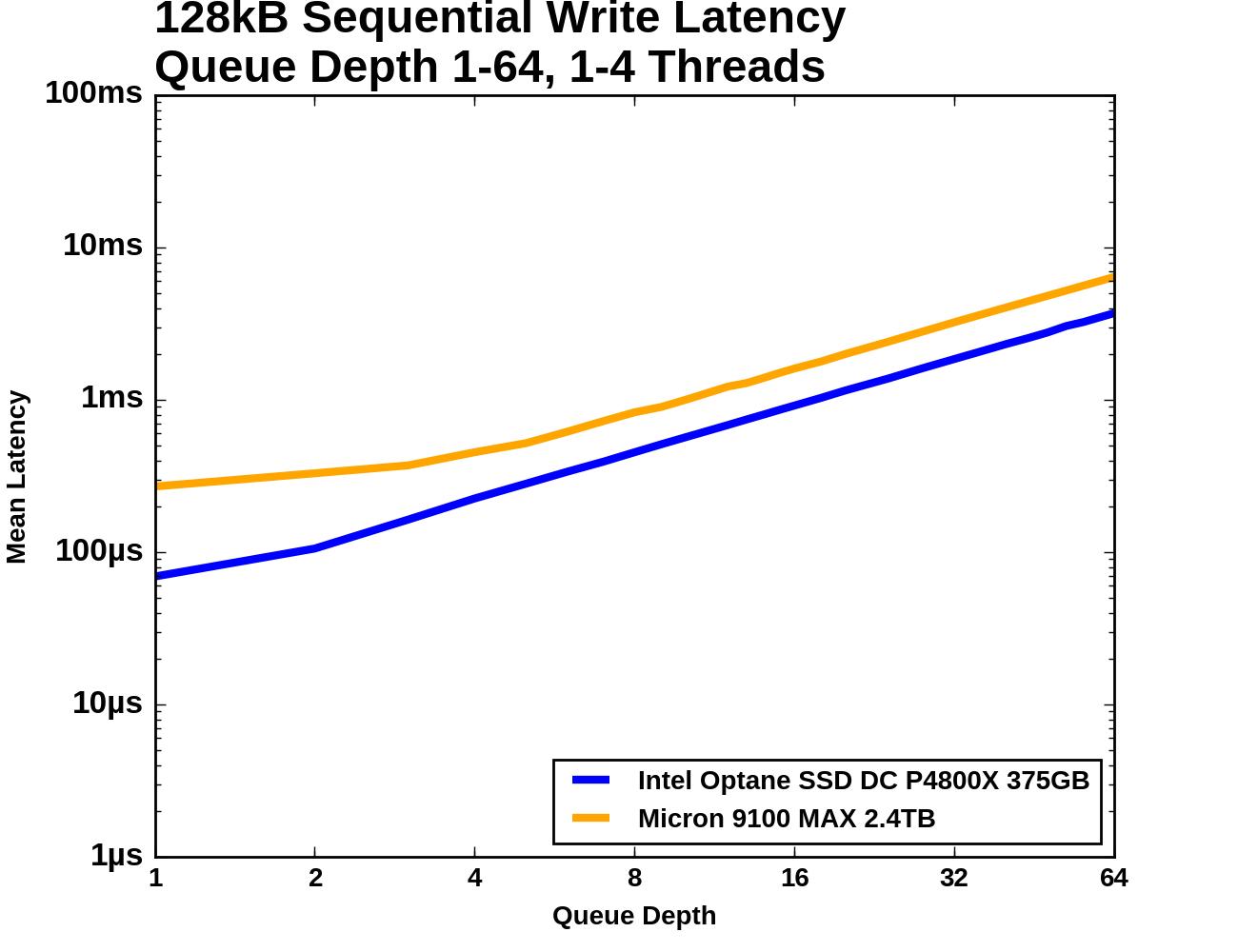 |
|||||||||
| Mean | Median | 99th Percentile | 99.999th Percentile | ||||||
The Micron 9100's 99th percentile latency starts out around twice that of the Optane SSD, but at QD3 it increases sharply as the drive approaches its maximum throughput until it is an order of magnitude higher than the Optane SSD. The 99.999th percentile latencies of the two drives are separated by a wide margin throughout the test.








117 Comments
View All Comments
Ninhalem - Thursday, April 20, 2017 - link
At last, this is the start of transitioning from hard drive/memory to just memory.ATC9001 - Thursday, April 20, 2017 - link
This is still significantly slower than RAM....maybe for some typical consumer workloads it can take over as an all in one storage solution, but for servers and power users, we'll still need RAM as we know it today...and the fastest "RAM" if you will is on die L1 cache...which has physical limits to it's speed and size based on speed of light!I can see SSD's going away depending on manufacturing costs but so many computers are shipping with spinning disks still I'd say it's well over a decade before we see SSD's become the replacement for all spinning disk consumer products.
Intel is pricing this right between SSD's and RAM which makes sense, I just hope this will help the industry start to drive down prices of SSD's!
DanNeely - Thursday, April 20, 2017 - link
Estimates from about 2 years back had the cost/GB price of SSDs undercutting that of HDDs in the early 2020's. AFAIK those were business as usual projections, but I wouldn't be surprised to see it happen a bit sooner as HDD makers pull the plug on R&D for the generation that would otherwise be overtaken due to sales projections falling below the minimums needed to justify the cost of bringing it to market with its useful lifespan cut significantly short.Guspaz - Saturday, April 22, 2017 - link
Hard drive storage cost has not changed significantly in at least half a decade, while ssd prices have continued to fall (albeit at a much slower rate than in the past). This bodes well for the crossover.Santoval - Tuesday, June 6, 2017 - link
Actually it has, unless you regard HDDs with double density at the same price every 2 - 2.5 years as not an actual falling cost. $ per GB is what matters, and that is falling steadily, for both HDDs and SSDs (although the latter have lately spiked in price due to flash shortage).bcronce - Thursday, April 20, 2017 - link
The latency specs include PCIe and controller overhead. Get rid of those by dropping this memory in a DIMM slot and it'll be much faster. Still not as fast as current memory, but it's going to be getting close. Normal system memory is in the range of 0.5us. 60us is getting very close.tuxRoller - Friday, April 21, 2017 - link
They also include context switching, isr (pretty board specific), and block layer abstraction overheads.ddriver - Friday, April 21, 2017 - link
PCIE latency is below 1 us. I don't see how subtracting less than 1 from 60 gets you anywhere near 0.5.All in all, if you want the best value for your money and the best performance, that money is better spent on 128 gigs of ecc memory.
Sure, xpoint is non volatile, but so what? It is not like servers run on the grid and reboot every time the power flickers LOL. Servers have at the very least several minutes of backup power before they shut down, which is more than enough to flush memory.
Despite intel's BS PR claims, this thing is tremendously slower than RAM, meaning that if you use it for working memory, it will massacre your performance. Also, working memory is much more write intensive, so you are looking at your money investment crapping out potentially in a matter of months. Whereas RAM will be much, much faster and work for years.
4 fast NVME SSDs will give you like 12 GB\s bandwidth, meaning that in the case of an imminent shutdown, you can flush and restore the entire content of those 128 gigs of ram in like 10 seconds or less. Totally acceptable trade-back for tremendously better performance and endurance.
There is only one single, very narrow niche where this purchase could make sense. Database usage, for databases with frequent low queue access. This is an extremely rare and atypical application scenario, probably less than 1/1000 in server use. Which is why this review doesn't feature any actual real life workloads, because it is impossible to make this product look good in anything other than synthetic benches. Especially if used as working memory rather than storage.
IntelUser2000 - Friday, April 21, 2017 - link
ddriver: Do you work for the memory industry? Or hold a stock in them? You have a personal gripe about the company that goes beyond logic.PCI Express latency is far higher than 1us. There are unavoidable costs of implementing a controller on the interface and there's also software related latency.
ddriver - Friday, April 21, 2017 - link
I have a personal gripe with lying. Which is what intel has been doing every since it announced hypetane. If you find having a problem with lying a problem with logic, I'd say logic ain't your strong point.Lying is also what you do. PCIE latency is around 0.5 us. We are talking PHY here. Controller and software overhead affect equally every communication protocol.
Xpoint will see only minuscule latency improvements from moving to dram slots. Even if PCIE has about 10 times the latency of dram, we are still talking ns, while xpoint is far slower in the realm of us. And it ain't no dram either, so the actual latency improvement will be nowhere nearly the approx 450 us.
It *could* however see significant bandwidth improvements, as the dram interface is much wider, however that will require significantly increased level of parallelism and a controller that can handle it, and clearly, the current one cannot even saturate a pcie x4 link. More bandwidth could help mitigate the high latency by masking it through buffering, but it will still come nowhere near to replacing dram without a tremendous performance hit.