Assessing IBM's POWER8, Part 1: A Low Level Look at Little Endian
by Johan De Gelas on July 21, 2016 8:45 AM ESTInside the Beast(s)
When the POWER8 was first launched, the specs were mind boggling. The processor could decode up to 8 instructions, issue 8 instructions, and execute up to 10 and all this at clockspeed up to 4.5 GHz. The POWER8 is thus an 8-way superscalar out of order processor. Now consider that
- The complexity of an architecture generally scales quadratically with the number of "ways" (hardware parallelism)
- Intel's most advanced architecture today - Skylake - is 5-way
and you know this is a bold move. If you superficially look at what kind of parallelism can be found in software, it starts to look like a suicidal move. Indeed on average, most modern CPU compute on average 2 instructions per clockcycle when running spam filtering (perlbench), video encoding (h264.ref) and protein sequence analyses (hmmer). Those are the SPEC CPU2006 integer benchmarks with the highest Instruction Per Clockcycle (IPC) rate. Server workloads are much worse: IPC of 0.8 and less are not an exception.
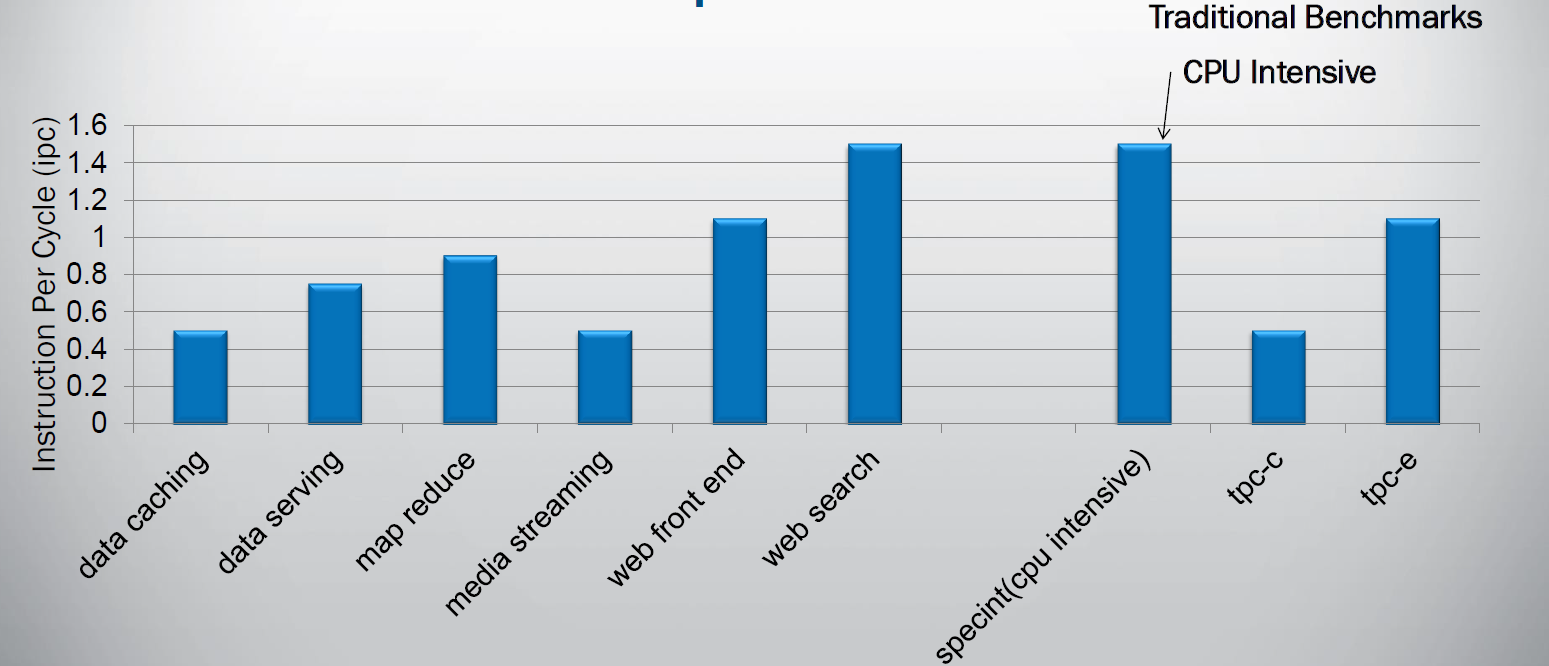
It is clear that simply widening a design will not bring good results, so IBM chose to run up to 8 threads simultaneously on their core. But running lots of threads is not without risk: you can end up with a throughput processor which delivers very poor performance in a wide range of applications that need that single threaded speed from time to time.
The picture below shows the wide superscalar architecture of the IBM POWER8. The image is taken from the white paper "IBM POWER8 processor core architecture", written by B. Shinharoy and many others.
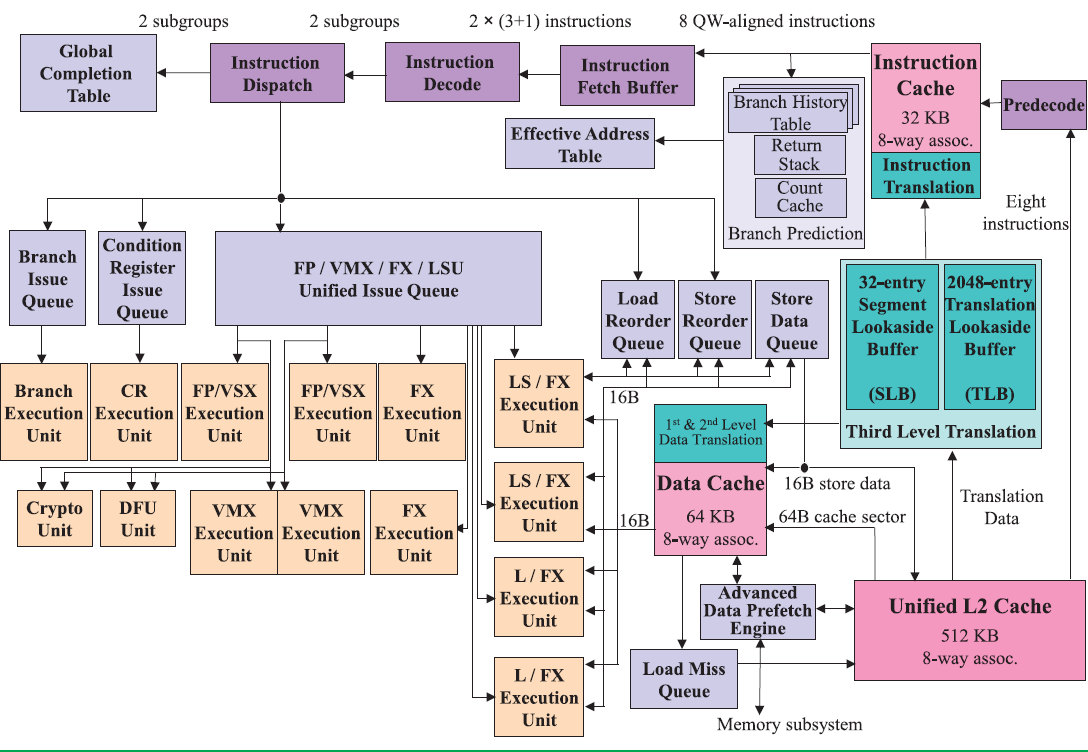
The POWER8+ will have very similar microarchitecture. Since it might have to face a Skylake based Xeon, we thought it would be interesting to compare the POWER8 with both Haswell/Broadwell as Skylake.
The second picture is a very simplified architecture plan that we adapted from an older Intel Powerpoint presentation about the Haswell architecture, to show the current Skylake architecture. The adaptations were based on the latest Intel optimization manuals. The Intel diagram is much simpler than the POWER8's but that is simply because I was not as diligent as the people at IBM.
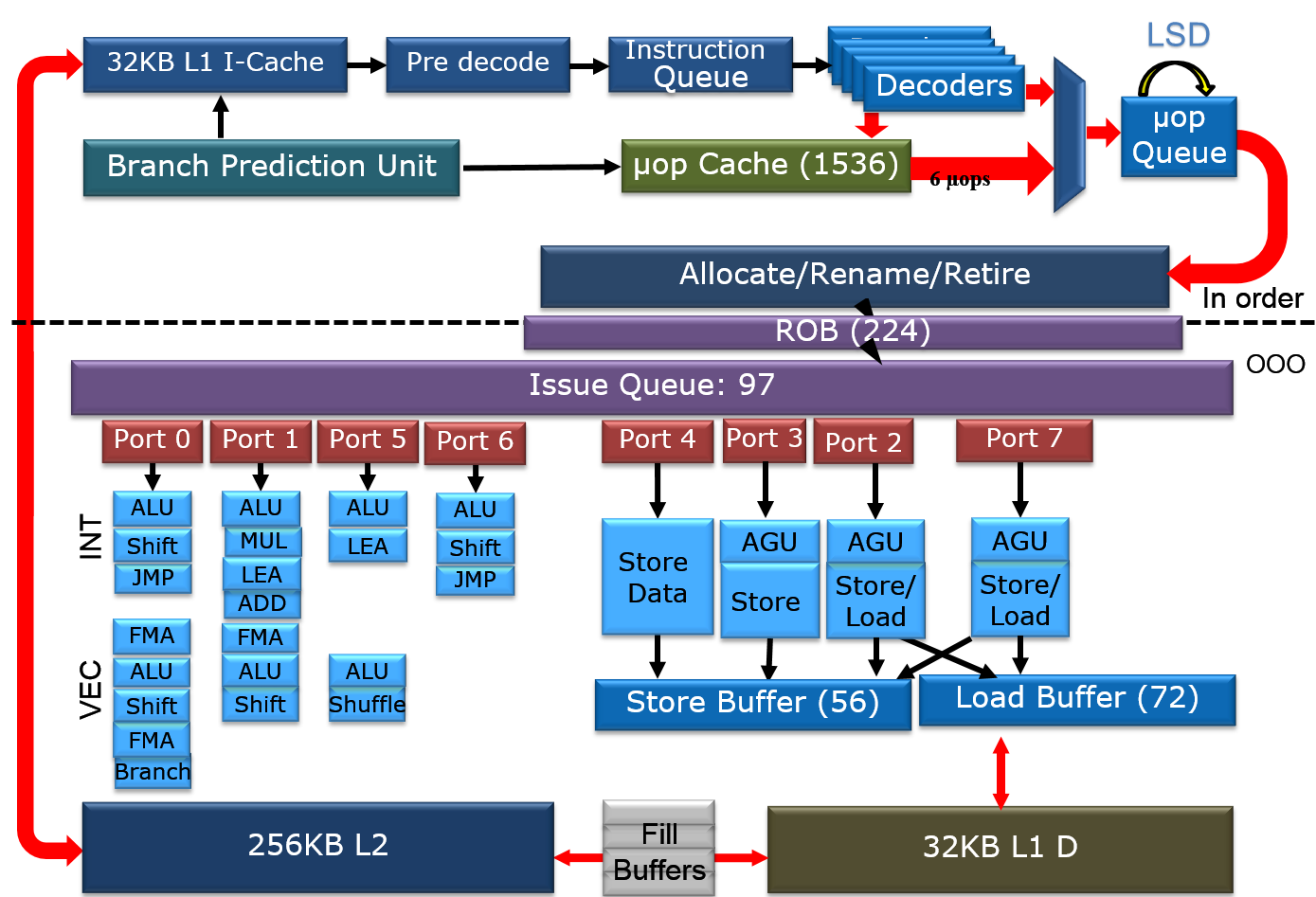
It is above our heads to compare the different branch prediction systems, but both Intel and IBM combine several different branch predictors to choose a branch. Both make use of a very large (16 K entries) global branch history table. Both processors scan 32 bytes in advance for branches. In case of IBM this is exactly 8 instructions. In case of Intel this is twice as much as it can fetch in one cycle (16 Bytes).
On the POWER8, data is fetched from the L2-cache and then predecoded into the L1-cache. Predecoding includes adding branch, exception, and grouping. This makes sure that predecoding is out the way before the actual computing ("Von Neuman Cycle") starts.
In Intel Haswell/Skylake, instructions are only predecoded after they are fetched. Predecoding performs macro-op fusion: fusing two x86 instructions together to save decode bandwidth. Intel's Skylake has 5 decoders and up to 5 µop instructions are sent down the pipelines. The current Xeon based upon Broadwell has 4 decoders and is limited to 4 instructions per clock. Those decoded instructions are sent into a µ-op cache, which can contain up to 1536 instructions (8-way), about 100 bits wide. The hitrate of the µop cache is estimated at 80-90% and up to 6 µops can be dispatched in that case. So in some situations, Skylake can run 6 instructions in parallel but as far as we understand it cannot sustain it all the time. Haswell/Broadwell are limited to 4. The µop cache can - most of the time - reduce the branch misprediction penalty from 19 to 14.
Back to the POWER8. Eight instructions are sent to the IBM POWER8 fetch buffer, where up 128 instructions can be held for two thread(s). A single thread can only use half of that buffer (64 instructions). This method of allocation gives each of two threads as much resources as one (i.e. no sharing), which is one of the key design philosophies for the POWER8 architecture.
Just like in the x86 world, the decoding unit breaks down the more complex RISC instructions into simpler internal instructions. Just like any modern Intel CPU, the opposite is also possible: the POWER8 is capable of fusing some combinations of 2 adjacent instructions into one instruction. Saving internal bandwidth and eliminating branches is one of the way this kind of fusion increases performances.
Contrary to the Intel's unified queue, the IBM POWER has 3 different issue queues: branch, condition register, and the "Load/Store/FP/Integer" queue. The first two can issue one instruction per clock, the latter can send off 8 instructions, for a combined total of 10 instructions per cycle. Intel's Haswell-Skylake cores can issue 8 µops per cycle. So both the POWER8 and Intel CPU have more than ample issue and execution resources for single threaded code. More than one thread is needed to really make use of all those resources.
Notice the difference in focus though. The Intel CPU has half of the load units (2), but each unit has twice the bandwidth (256 bit/cycle). The POWER8 has twice the amount of load units (4), but less bandwidth per unit (128 bit per cycle). Intel went for high AVX (HPC) performance, IBM's focus was on feeding 2 to 8 server threads. Just like the Intel units, the LSUs have Address Generation Units (AGUs). But contrary to Intel, the LSUs are also capable of doing simple integer calculations. That kind of massive integer crunching power would be a total waste on the Intel chip, but it is necessary if you want to run 8 threads on one core.








124 Comments
View All Comments
close - Thursday, July 21, 2016 - link
This right here is why I keep coming back to Anandtech. Thumbsup!jardows2 - Thursday, July 21, 2016 - link
Agreed. There are plenty of places you can go to find out how pretty your games will look, but this sort of stuff is much more interesting to me!Looking forward to the application numbers. Power8 may shape up to be a nice server alternative. I would like to see about virtualization. With the threaded capabilities, it might just be a good platform for that.
Brutalizer - Friday, July 22, 2016 - link
Regarding virtualization, SPARC M7 is more than 4x faster than POWER8 on SPECvirt_sc2013, and more than 2x faster than x86https://blogs.oracle.com/BestPerf/entry/20151025_s...
Regarding SPECcpu2006, SPARC M7 is 1.9x and 1.8x faster than POWER8, and is faster than x86 as well:
https://blogs.oracle.com/BestPerf/entry/201510_spe...
Regarding memory bandwidth, SPARC M7 is 2.2x and 1.7x faster than POWER8 and 2.4x faster than x86 on STREAM benchmarks:
https://blogs.oracle.com/BestPerf/entry/20151025_s...
If you dig a bit on that web site, you will find 30ish world records, where SPARC M7 is 2-3x faster than POWER8 and x86, all the way up to 11x faster.
It is interesting to delve in to the technology behind POWER8 and x86, but in the end, what really matters, is how fast the cpu performs in real life workloads and benchmarks. SPARC has lower IPC than x86, but as real life server workloads have an IPC of 0.8, SPARC which is a server cpu, is much faster than x86 in practice. In theory, x86 and POWER8 are fast, but in practice, they are much slower than SPARC. So, you can theoretize all you want, but in the end - which cpu is fastest in real workloads and in real benchmarks? SPARC. Just look at all the benchmarks above, where SPARC M7 is faster in number crunching, Big data, neural networks, Hadoop, virtualization, memory bandwidth, etc etc. And if you also factor in the business benchmarks, such as SAP, Peoplesoft, databases etc - there is no contest. You get twice the performance, or more, with a SPARC M7 server than the competitors.
SPARC M7 can also turn on encryption on everything, and loose 2-3% performance. Whereas encryption on POWER8 and x86 typically reduces performance down to 33% or lower. So, if you benchmark encrypted workloads, then SPARC M7 is not typically 2-3x faster, but another 3 times faster again - i.e. typically faster 6-9x.
Kevin G - Friday, July 22, 2016 - link
Oracle marketing at its finest.The virtualization score is good vs. POWER8 mainly based on the radical different in core count: 32 vs. 6. Yeah, even with lower IPC, I'd expect the higher core count system to fair better. Also note that IBM offers such higher core count systems and at higher clock speeds which would close that gap.
Same for the claims of being twice as fast in raw benchmarks: Oracle isn't comparing there best against IBM's best POWER8. There choice of comparison point was simply arbitrary to make SPARC look good, as is the job of their marketing department. Real performance comparisons come from independent reports.
To get the memory bandwidth advantage Oracle proclaims, they have to use twice as many sockets.
SarahKerrigan - Friday, July 22, 2016 - link
These supposed Oracle "wins" are all based on worst-case scenarios for Power8 - ie, testing a DCM based system and counting each DCM as two processors. This isn't very useful for comparison to Power8 overall, as the entry-level machines like the one in this article, and the S822LC positioned above it, all use SCM's (with as many as twelve cores.)M7 is a first-rate CPU, but it's also in a totally different cost class; the cheapest M7 config listed on Oracle's website costs over US$40k, for a one-processor machine. Considering you can get a pair of 10-core Power8's with 256GB of RAM in an S822LC for US$14,300 list, this is an exceptionally tough sell for those not wedded to Solaris (and by the way, there's no RHEL, SLES, or Ubuntu for SPARC - Solaris is pretty much the only game in town.)
My company is currently deploying an S812LC and intends to deploy an S822LC in the future; we briefly considered SPARC but found the style of marketing that Oracle and its proxies seem to favor to be deeply offputting, as is the relatively poor perf/$ compared to both Power and Intel. Our loads (mainly a large PostgreSQL application) scale well with memory bandwidth and cache sizes, and we've found S812LC perf/$ to be first-rate. The main downsides have just been related to the relative immaturity of the ppc64le platform (occasional lack of available packages, etc.)
Brutalizer - Sunday, July 31, 2016 - link
These oracle sparc m7 benchmarks vs IBM power8 are not worst case. The DCM Power8 module, actually consists of two power8 CPUs, in one socket. So there is nothing wrong with these benchmarks. It is up to IBM to release benchmarks with two power8 CPUs in one socket, not oracle choice. IBM has for decades promoted few strong cores instead of many weaker cores. For instance, IBM claimed "dual core power6 @ 5 ghz was superior to 8core sparc niagara2 @ 1.6 ghz because databases runs best on few but strong cores" and IBM talked about future super strong single/dual core 6-7 ghz power CPUs and mocked sparc many but weaker cores because databases are worthless on sparc. Back then sparc were first with 8 cores, and it was very controversial having that many cores. Later IBM realized laws of physics prohibit highly clocked CPUs, so IBM abandoned that path and followed sparc with many knower clocked cores. Just like Intel abanoned Prescott with high clocks. Today everybody have many lower clocked cores, just like spare decades ago.Of course, if IBM released benchmarks with other configurations of power8, oracle would be happy to use them, but IBM has not. Oracle has no choice than to use those benchmarks that IBM has released. It is not oracles choice what benchmarks IBM release.
We also know that power8 is slower than the latest Intel xeons, and we know that sparc m7 is typically 2-3x faster than Intel Xeon, so probably these benchmarks from IBM vs sparc m7 benchmarks are true. If you find other IBM power8 benchmarks I am sure oracle will compare to them instead. But you can only bench against ibm's own results, right?
Regarding my credibility, yes, I am an sparc supporter. What is the problem with being an supporter? I know there are IBM supporters here, and there are nvidia, Amd, Intel etc supporters. What is wrong with that? Does the fact that I consider sparc to be superior, invalidate the official oracle vs IBM vs Intel benchmarks? I have not created those benchmarks, IBM has. And oracle. And Intel. Instead of you, IBM supporters, linking to official superior IBM power8 benchmarks you claim that because I am an sparc supporter, those official vendor benchmarks can not be trusted. Instead of proving that power8 is faster with benchmarks, you resort to attacking me. That does not win you any discussions. Show us facts and benchmarks if you want invalidate my linked benchmarks, instead of attacking me. Fact is, you have not proven anything regarding power8 inferiority.
And why do I keep talking about sparc m7? Well, it seems people believe that Intel and power8 is so fast, but in fact there are another cpu out there, 2-3x faster, up to 11x faster. People just don't know that sparc is the worlds fastest CPU. I would like anandtech to talk about the best CPU in the world instead of slow IBM power or Intel Xeon CPUs. But anandtech don't.
Regarding myself, yes I have been interviewed in Swedish media, and it is evident that I have always worked finance. I have never worked at Sun nor Oracle. Just read the interview. The last years I am an quantitative analyst concocting trading strategies. I have never worked in IT. i just happen to be a nerd and geek, and i only support the best tech, and it is sparc and Solaris. IBM and Intel sucks. Just compare their lousy performance to sparc m7
SarahKerrigan - Sunday, July 31, 2016 - link
"The DCM Power8 module, actually consists of two power8 CPUs, in one socket."Dude, nobody outside of Oracle marketing cares, just like they didn't care when Xeon and Opteron used MCM's. IBM has SCM's going all the way up to 12 cores and 8 Centaur links, they just use DCM's for cost reasons on some (but not all) smaller machines. These have the same number of Centaur links per socket as the big SCM's, and they're priced as one would expect of one or two socket enterprise systems. Realistically, the 8-Centaur SCM has roughly equivalent memory bandwidth to the 8-Centaur DCM.
"Later IBM realized laws of physics prohibit highly clocked CPUs, so IBM abandoned that path and followed sparc with many knower clocked cores. Just like Intel abanoned Prescott with high clocks. Today everybody have many lower clocked cores, just like spare decades ago."
You mean like when Oracle replaced 16-core 1.65GHz T3 with 8-core 3GHz T4? Which, by the way, had very similar throughput performance (which you say is all that matters) to the T3, but had far higher single-thread and single-core performance? If only throughput matters, why would Oracle do such a thing? It's quite a thing for you to imply Oracle doesn't know what they're doing!
They also have been publishing benchmarks for their shiny new S7 chip where they lose per-chip to the Xeon - but they win per-core, which you've said on many occasions doesn't matter. Here are some examples:
https://blogs.oracle.com/BestPerf/entry/20160629_n...
https://blogs.oracle.com/BestPerf/entry/20160629_r...
Comparisons to IBM are conspicuously absent, I suspect because Power perf/core is rather impressive.
"For instance, IBM claimed "dual core power6 @ 5 ghz was superior to 8core sparc niagara2 @ 1.6 ghz because databases runs best on few but strong cores" and IBM talked about future super strong single/dual core 6-7 ghz power CPUs and mocked sparc many but weaker cores because databases are worthless on sparc."
IBM has never reduced per-core or single-thread performance generation to generation. P7 and P8 were both massive improvements in both categories. IBM has not historically shown interest in "weaker" cores for Power.
"Well, it seems people believe that Intel and power8 is so fast, but in fact there are another cpu out there"
Yes. For the low, low price of over forty thousand dollars for the lowest-end, one-processor M7 system with public prices on Oracle's website.
"2-3x faster"
Consulting officially published results on an industry-standard benchmark:
Xeon E7-8890v4, 2.2GHz: SPECint rate result of 927/chip, 24 cores (38/core)
Power8 SCM, 4GHz: SPECint rate result of 900/chip, 12 cores (75/core)
SPARC M7, 4.13GHz: SPECint rate result of 1200/chip, 32 cores (37/core)
Not that impressive - especially given M7's price. And certainly not 2-3x of anything (or even 1.9x). It's 1.3x... while having 2.5x as many cores. Additionally, for a large range of applications, single-thread performance matters.
"up to 11x faster."
When running in-memory queries inside Oracle DB using accelerator instructions added to SPARC M7 specifically for Oracle DB, yes.
By the way, since you mentioned memory bandwidth... how does it feel to have two-processor SPARC S7 losing on STREAM Triad to entry-level, one-processor Power8 machines that cost significantly less? Compare https://blogs.oracle.com/BestPerf/entry/20160629_s... to the entry-level Power8 results in the article we're commenting on!
Oracle proponents need to do better than this. At least Phil Dunn resorts less to copypasta...
SPEC references:
https://spec.org/cpu2006/results/res2016q2/cpu2006...
https://spec.org/cpu2006/results/res2015q4/cpu2006...
https://spec.org/cpu2006/results/res2015q2/cpu2006...
close - Tuesday, August 2, 2016 - link
"What is the problem with being an supporter? What is wrong with that?"Lying, deceiving, etc.
This is what Oracle does because simply put ever since they acquired Sun those products went to sh*t. Oracle are reverse-alchemists. Whether it's software (like Java) or hardware (like the Sparc) Oracle managed to turn those gold nuggets into lead weights. Java was buried by Google, Sparc was buried by Intel and IBM.
Oracle always resorts to this kind of piss-poor advertising and it's not for the customers themselves. They try to save face with numbers on that site with one reason only: to have something to show during their conferences. Because companies don't rely on numbers in a benchmark when committing to multi-year contracts and getting tied into a specific ecosystem.
Right now only a handful of government institutions and some in regulated industries still rely on Sparc and only in corner cases. Most times it's just until they manage to migrate off them.
close - Tuesday, August 2, 2016 - link
The EXA products might be the only ones with some solid popularity because it's the full package but they do come with plenty of caveats. Having worked in the defense and financial sectors for a long time I've seen plenty of consolidation being done on newer Oracle/Sparc systems but not so many new deployments (a handful). And the proof is in the numbers. Oracle can't seem to make any headway into this.This isn't the kind of runaway success you'd expect for such an "overpowering" system.
P.S. Google for "For the sake of full disclosure, I work at Oracle. The opinions and views expressed in this post are my own, and do not necessarily reflect the opinions or views of my employer" and see the army of posters Oracle is employing and the kind of tactics Oracle they resort to. And that's just the official posters.
close - Tuesday, August 2, 2016 - link
Their engineered systems for integrated infrastructure and platforms (the latter being their driver) are great but not because of the hardware or the CPU in particular. It's because of the value of the whole package that includes the software layer. Nobody actually cares about the CPU in those particular products and if the CPU were being sold they would have tough time.And not least, they almost always HAVE to heavily discount the price in order to make the sale. From personal and recent experience Oracle was eager enough to undercut competitors like Cisco, VCE or HP (HP has 3 digit growth in this segment YoY for 2-3 years now) and discounted so aggressively that we ended up with 50% savings...