The Intel Xeon E5 v4 Review: Testing Broadwell-EP With Demanding Server Workloads
by Johan De Gelas on March 31, 2016 12:30 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
- Enterprise CPUs
- Broadwell
Broadwell-EP: A 10,000 Foot View
What are the building blocks of a 22-core Xeon? The short answer: 24 cores, 2.5 MB L3-cache per core, 2 rings connected by 2 bridges (s-boxes) and several PCIe/QPI/home "agents".
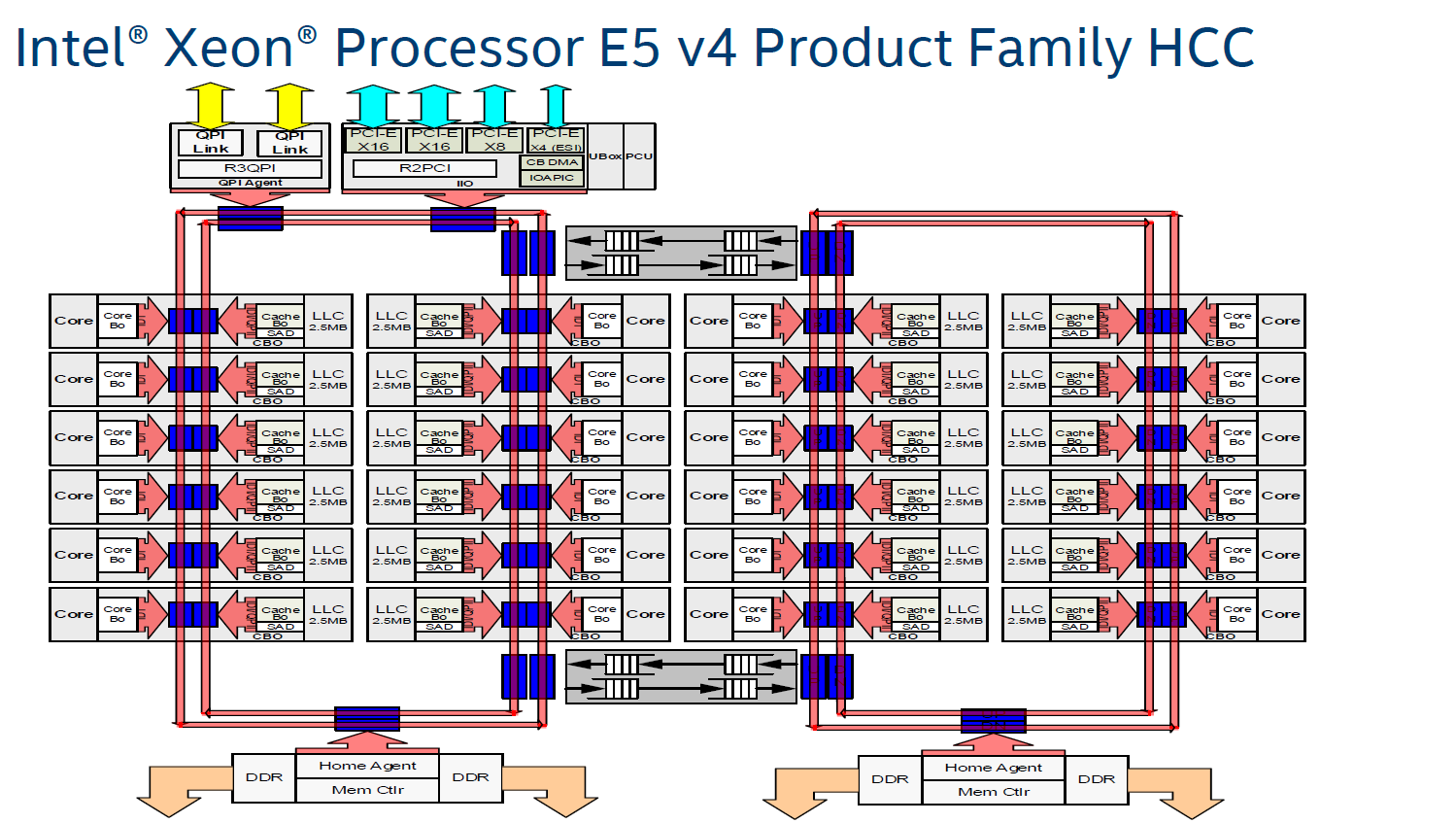
The fact that only 22 of those 24 cores are activated in the top Xeon E5 SKU is purely a product differentiation decision. The 18 core Xeon E5 v3 used exactly the same die as the Xeon E7, and this has not changed in the new "Broadwell" generation.
The largest die (+/- 454 mm²), highest core (HCC) count SKUs still work with a two ring configuration connected by two bridges. The rings move data in opposite directions (clockwise/counter-clockwise) in order to reduce latency by allowing data to take the shortest path to the destination. The blue points indicate where data can jump onto the ring buses. Physical addresses are evenly distributed over the different cache slices (each 2.5 MB) to make sure that L3-cache accesses are also distributed, as a "hotspot" on one L3-cache slice would lower performance significantly. The L3-cache latency is rather variable: if the core is lucky enough to find the data in its own cache slice, only one extra cycle is needed (on top of the normal L1-L2-L3 latency). Getting a cacheline of another slice can cost up to 12 cycles, with an average cost of 6 cycles..
Meanwhile rings and other entities of the uncore work on a separate voltage plane and frequency. Power can be dynamically allocated to these entities, although the uncore parts are limited to 3 GHz.
Just like Haswell-EP, the Broadwell-EP Xeon E5 has three different die configurations. The second configuration supports 12 to 15 cores and is a smaller version (306mm²) of the third die configuration that we described above. These dies still have two memory controllers.
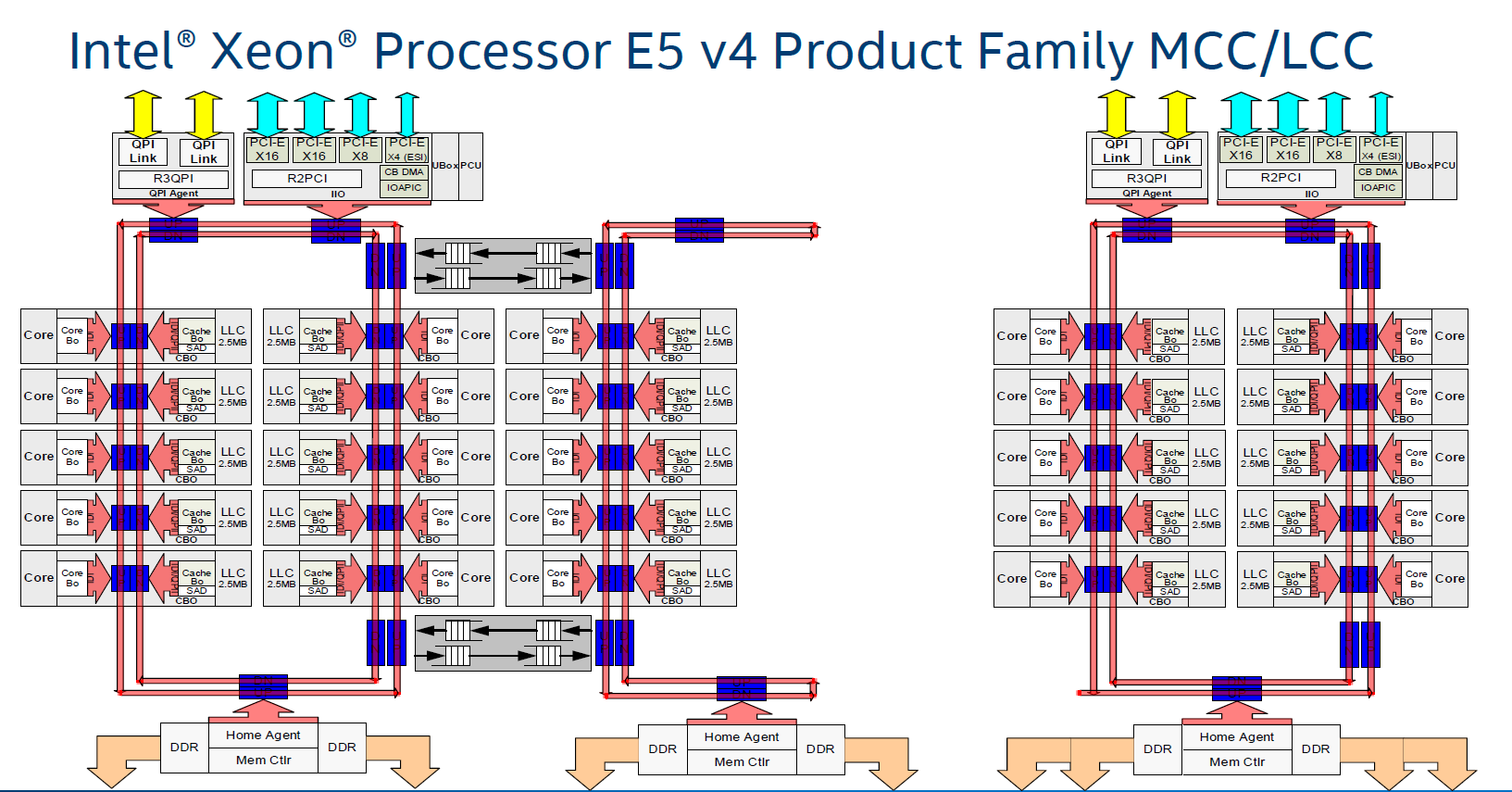
Otherwise the smallest 10 core die uses only one dual ring, two columns of cores, and only one memory controller. However, the memory controller drives 4 channels instead of 2, so there is a very small bandwidth penalty (5-10%) compared to the larger dies (HCC+MCC) with two memory controllers. The smaller die has a smaller L3-cache of course (25 MB max.). As the L3-cache gets smaller, latency is also a bit lower.
Cache Coherency
As the core count goes up, it gets increasingly complex to keep cache coherency. Intel uses the MESIF (Modified, Exclusive, shared, Invalid and Forward) protocol for cache coherency. The Home Agents inside the memory controller and the caching agents inside the L3-cache slice implement the cache coherency. To maintain consistency, a snoop mechanism is necessary. There are now no less than 4 different snoop methods.
The first, Early Snoop, was available starting with Sandy Bridge-EP models. With early snoop, caching agents broadcast snoop requests in the event of an L3-cache miss. Early snoop mode offers low latency, but it generates massive broadcasting traffic. As a result, it is not a good match for high core count dies running bandwidth intensive applications.
The second mode, Home Snoop, was introduced with Ivy Bridge. Cache line requests are no longer broadcasted but forwarded to the home agent in the home node. This adds a bit of latency, but significantly reduces the amount of cache coherency traffic.
Haswell-EP added a third mode, Cluster on Die (CoD). Each home agent has 14 KB directory cache. This directory cache keeps track of the contested cache lines to lower cache-to-cache transfer latencies. In the event of a request, it is checked first, and the directory cache returns a hit, snoops are only sent to indicated (by the directory cache) agents.
On Broadwell-EP, the dice are indeed split along the rings: all cores on one ring are one NUMA node, all other cores on the other ring make the second NUMA node. On Haswell-EP, the split was weirder, with one core of the second ring being a member of the first cluster. On top of that, CoD splits the processor in two NUMA nodes, more or less one node per ring.
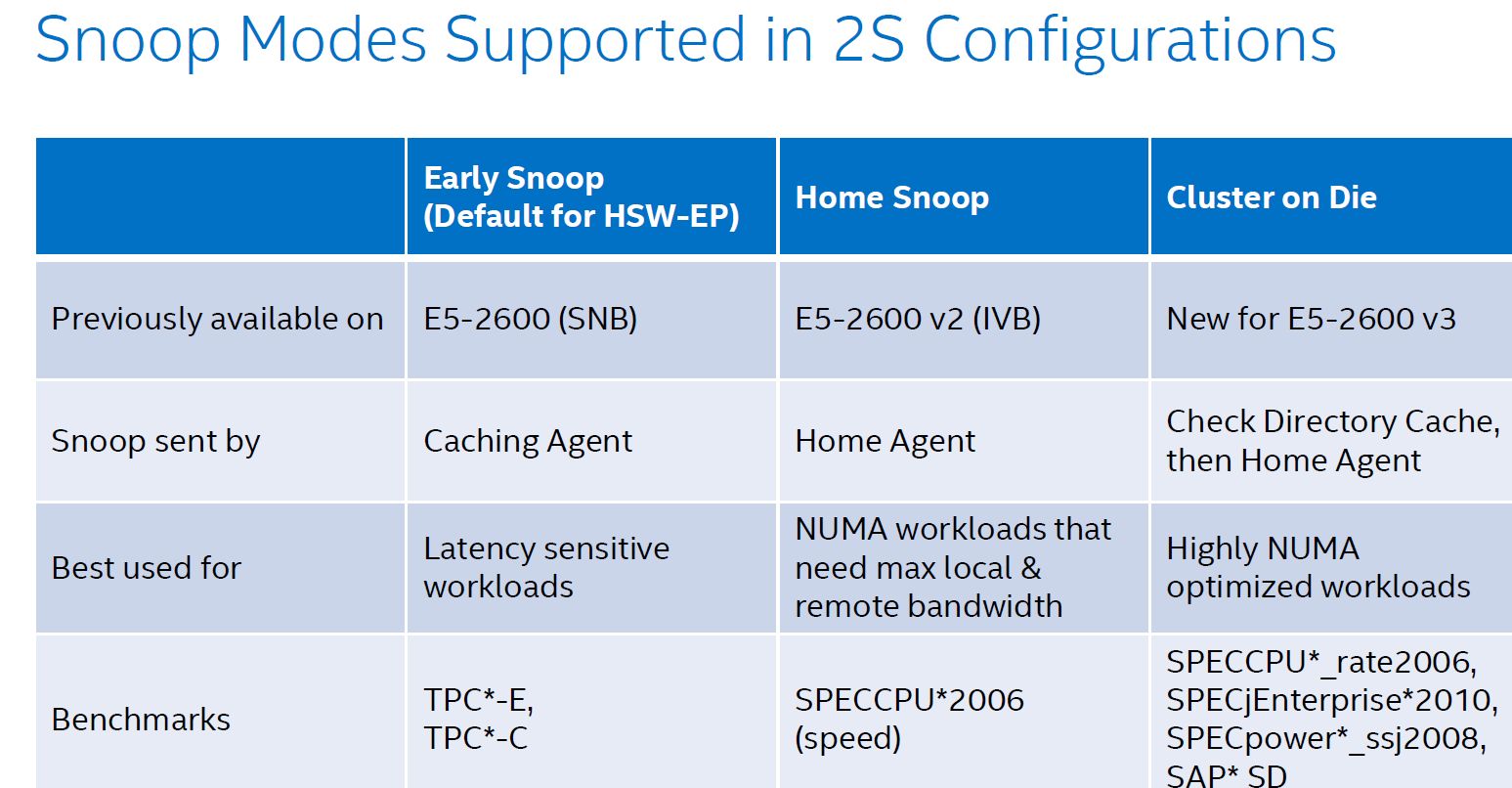
The fourth mode, introduced with Broadwell EP, is the "home snoop" method, but improved with the use of the directory cache and yet another refinement called opportunistic snoop broadcast. This mode already starts snoops to the remote socket early and does the read of the memory directory in parallel instead of waiting for the latter to be done. This is the default snoop method on Broadwell EP.
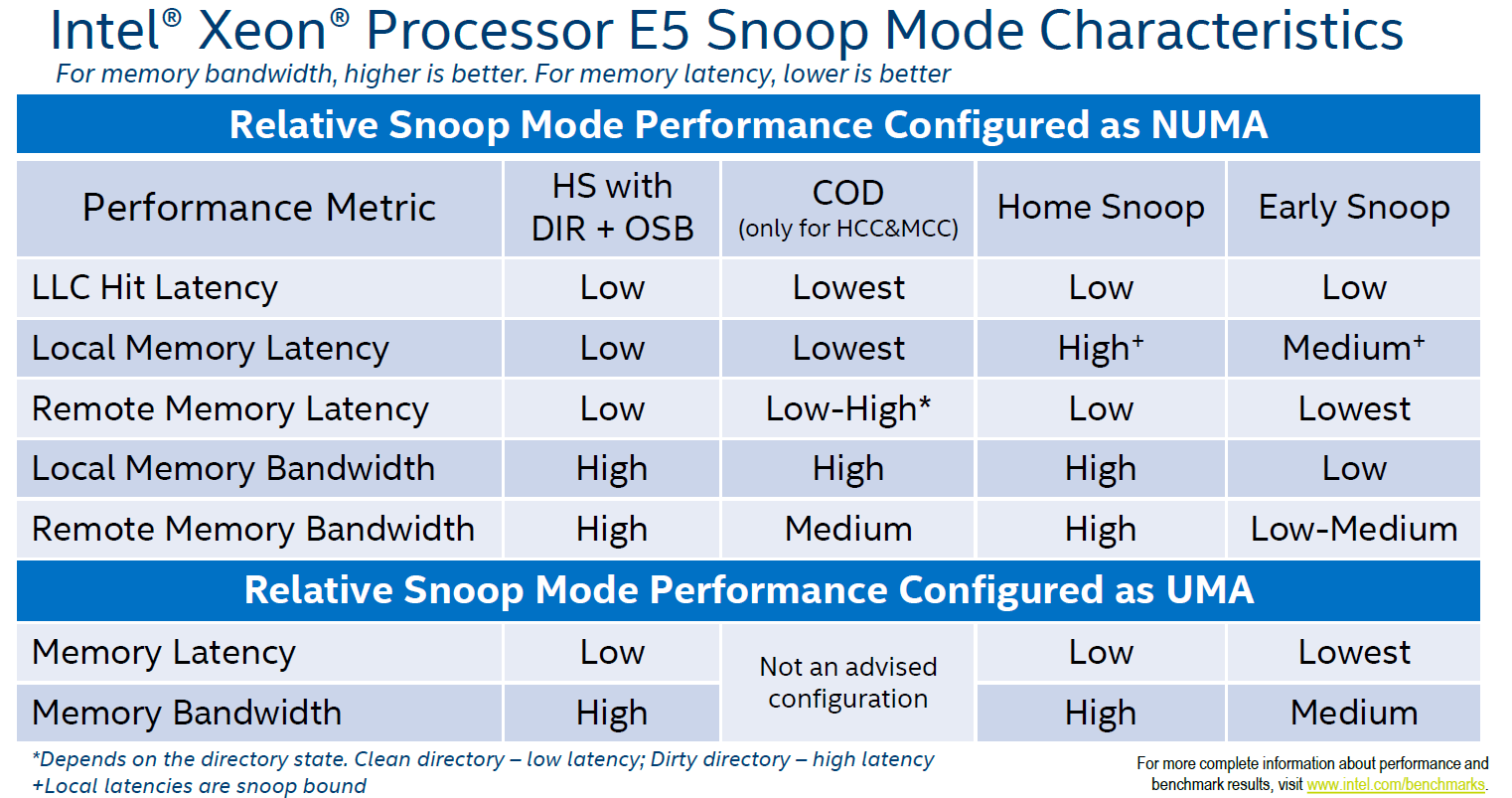
This opportunistic snooping lowers the latency to remote memory.
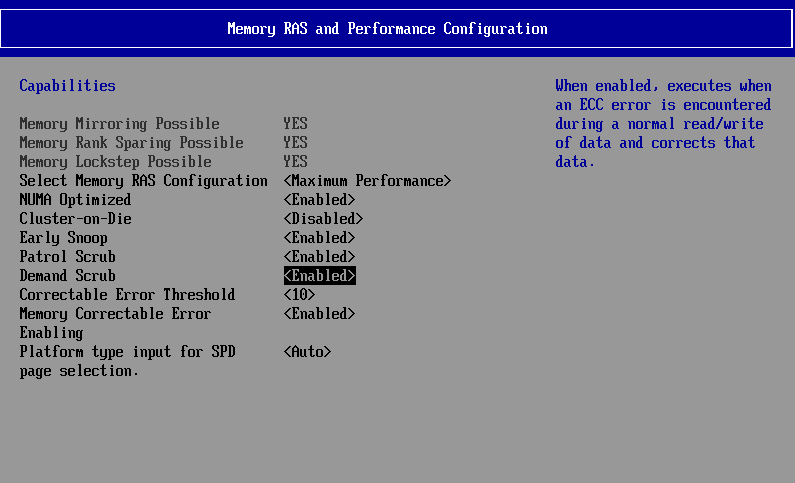
These snoop modes can be set in the BIOS as you can see above.








112 Comments
View All Comments
iwod - Thursday, March 31, 2016 - link
Maximum memory still 768GB?What happen to the 5.1Ghz Xeon E5?
Ian Cutress - Thursday, March 31, 2016 - link
I never saw anyone with a confirmed source for that, making me think it's a faked rumor. I'll happily be proved wrong, but nothing like a 5.1 GHz part was announced today.Brutalizer - Saturday, April 2, 2016 - link
It would have been interesting to bench to the best cpu today, the SPARC M7. For instance:-SAP: two M7 cpu scores 169.000 saps vs 109.000 saps for two of this Broadwell-EP cpus
-Hadoop, sort 10TB data: one SPARC M7 server with four cpus, finishes the sort in 4,260 seconds. Whereas a cluster of 32 PCs equipped with dual E5-2680v2 finishes in 1,054 seconds, i.e. 64 Intel Xeon cpus vs four SPARC M7 cpus.
-TPC-C: one SPARC M7 server with one cpu gets 5,000,000 tpm, whereas one server with two E5-2699v3 cpus gets 3.600.000 tpm
-Memory bandwidth, Stream triad: one SPARC M7 reaches 145 GB/sec, whereas two of these Broadwell-EP cpus reaches 119GB/sec
-etc. All these benchmarks can be found here, and another 25ish benchmarks where SPARC M7 is 2-3x faster than E5-2699v3 or POWER8 (all the way up to 11x faster):
https://blogs.oracle.com/BestPerf/entry/20151025_s...
Brutalizer - Saturday, April 2, 2016 - link
BTW, all these SPARC M7 benchmarks are almost unaffected if encryption is turned on, maybe 2-5% slower. Whereas if you turn on encryption for x86 and POWER8, expect performance to halve or even less. Just check the benchmarks on the link above, and you will see that SPARC M7 benchmarks are almost unaffected encrypted or not.JohanAnandtech - Saturday, April 2, 2016 - link
"if you turn on encryption for x86 and POWER8, expect performance to halve or even less". And this is based upon what measurement? from my measurements, both x86 and POWER8 loose like 1-3% when AES encryption is on. RSA might be a bit worse (2-10%), but asymetric encryption is mostly used to open connections.Brutalizer - Wednesday, April 6, 2016 - link
If we talk about how encryption affects performance, lets look at this benchmark below. Never mind the x86 is slower than the SPARC M7, let us instead look at how encryption affects the cpus. What performance hit has encryption?https://blogs.oracle.com/BestPerf/entry/20160315_t...
-For x86 we see that two E5-2699v3 cpus utilization goes from 40% without crypto, up to 80% with crypto. This leaves the x86 server with very little headroom to do anything else than executing one query. At the same time, the x86 server took 25-30% longer time to process the query. This shows that encryption has a huge impact on x86. You can not do useful work with two x86 cpus, except executing a query. If you need to do additional work, get four x86 xeons instead.
-If we look at how SPARC M7 gets affected by encryption, we see that cpu utilization went up from 30% up to 40%. So you have lot of headroom to do additional work while processing the query. At the same time, the SPARC cpu took 2% longer time to process the query.
It is not really interesting that this single SPARC M7 cpu is 30% faster than two E5-2699v3 in absolute numbers. No, we are looking at how much worse the performance gets affected when we turn on encryption. In case of x86, we see that the cpus gets twice the load, so they are almost fully loaded, only by turning on encryption. At the same time taking longer time to process the work. Ergo, you can not do any additional work with x86 with crypto. With SPARC, it ends up with 40% cpu utilization so you can do additional work on SPARC, and process time does not increase at all (2%). This proves that x86 encryption halves performance or worse.
For your own AES encryption benchmark, you should also see how much cpu utilization goes up. If it gets fully loaded, you can not do any useful work except handling encryption. So you need an additional cpu to do the actual work.
JohanAnandtech - Saturday, April 2, 2016 - link
Two M7 machines start at 90k, while a dual Xeon is around 20k. And most of those Oracle are very intellectually dishonest: complicated configurations to get the best out of the M7 machines, midrange older x86 configurations (10-core E5 v2, really???)Brutalizer - Wednesday, April 6, 2016 - link
The "dishonest" benchmarks from Oracle, are often (always?) using what is published. If for instance, IBM only has one published benchmark, then Oracle has no other choice than use it, right? Of course when there are faster IBM benchmarks out there, Oracle use that. Same with x86. In all these 25ish cases we see that SPARC M7 is 2-3x faster, all the way up to 11x faster. The benhcmarks vary very much, raw compute power, databases, deep learning, SAP, etc etcPhil_Oracle - Thursday, May 12, 2016 - link
I disagree Johan! You don't appear to know much about the new SPARC M7 systems and suggest you do a full evaluation before making such remarks. A SPARC T7-1 with 32-cores has a list price of about $39K outperforms a 2-socket 36-core E5-2699v3 anywhere from 38% (OLTP HammerDB) to over 8x faster (OLTP w/ in-memory analytics). A similarly configured *enterprise* class 2-socket 36-core E5-2699v3 from HPE or Cisco lists for $25K+, so in terms of price/performance, the SPARC T7-1 beats the 2-socket E5-2699v3. And if you take into account SW that’s licensed per core, the SPARC M7 is 60% to 2.6x faster/core, dramatically lowering licensing costs. With the new E5-2699v4, providing ~20% more cores at roughly the same price, gets closer, but with performance/core not changing much with E5 v4, SPARC M7 still has a huge lead. And the difference is while the E5 v3/v4 chips don't scale beyond 2-socket, you can get an SPARC M7 system up to 16-sockets with the almost identical price/performance of the 1-socket system.adamod - Friday, June 3, 2016 - link
BUT CAN IT PLAY CRYSIS?????