The Mobile CPU Core-Count Debate: Analyzing The Real World
by Andrei Frumusanu on September 1, 2015 8:00 AM EST- Posted in
- Smartphones
- CPUs
- Mobile
- SoCs
Overall Analysis & Conclusion
Hopefully we've managed to cover a few of the more common use-cases that are routinely encountered in daily usage on Android and get a good idea of how applications behave. We've seen some quite expected numbers for some use-cases but also stumbled on very large surprises that weren't quite as obvious.
When I started out this piece the goals I set out to reach was to either confirm or debunk on how useful homogeneous 8-core designs would be in the real world. The fact that Chrome and to a lesser extent Samsung's stock browser were able to consistently load up to 6-8 concurrent processes while loading a page suddenly gives a lot of credence to these 8-core designs that we would have otherwise not thought of being able to fully use their designed CPU configurations. In terms of pure computational load, web-page rendering remains as one of the heaviest tasks on a smartphone so it's very encouraging to see that today's web rendering engines are able to make good use of parallelization to spread the load between the available CPU cores.
It's hard to summarize the vast amount data of the last 16 pages in an orderly and correct manner. After all we are talking about extremely varying use-cases and time-scales for each scenario. While averaging the metrics over the course of a scenario might seem a good idea at first, one has to keep in mind that this wouldn't be able to properly represent cases where load peaks for smaller durations. It's these small computational bursts which are most of the time the cause for "lags" and frame-drops. So to better represent these bottle-necks which determine the user-visible cases of application speed and performance, we rather use the 90th percentile of the CPU run-queue depths:
| 90th Percentile Run-Queue Depth Averages | |||
| Little Cluster | Big Cluster | Little + Big Clusters |
|
| S-Browser - AnandTech Article | 2.27 | 2.19 | 3.87 |
| S-Browser - AnandTech FP | 3.12 | 1.25 | 4.15 |
| Chrome - AnandTech FP | 5.69 | 1.84 | 7.10 |
| Chrome - BBC Frontpage | 5.00 | 2.00 | 6.22 |
| Hangouts Launch | 2.77 | 2.11 | 4.01 |
| Hangouts Writing A Message | 2.80 | 0.05 | 2.57 |
| Reddit Sync Launch | 1.84 | 1.11 | 2.38 |
| Reddit Sync Scrolling | 0.95 | 1.03 | 1.46 |
| Play Store Open & Scroll | 2.87 | 0.78 | 3.45 |
| Play Store App Updates | 3.73 | 5.42 | 8.51 |
| Camera: Launch | 1.45 | 2.73 | 2.98 |
| Camera: Still Snapshot | 4.12 | 0.87 | 4.59 |
| Camera: Video Recording | 5.17 | 2.04 | 5.42 |
| Real Racing 3 Launch | 2.16 | 1.33 | 3.26 |
| Real Racing 3 Playing | 2.09 | 0.89 | 2.96 |
| Modern Combat 5 Playing | 2.09 | 0.73 | 2.68 |
I was wary of creating this table as it can be easily misinterpreted: Because run-queue depth averages are not directly representative of the amount of concurrent threads in a given scenario, we lose information when aggregating them for a given cluster or the whole system. This for example happens on the big cluster on the AT article load scenario where the 90th percentile of the aggregate rq-depth reaches 2.19 while in reality this figure is composed of 4 medium-high threads. Readers should thus keep in mind the actual detailed graphs of the preceding pages when reading the table.
While not directly the goal of the article, the collected data also serves as a perfect case-study for heterogeneous big.LITTLE SoCs. We've long seen discussions concerning what the "ideal" big.LITTLE configuration would be. There's several angles to this: the most optimal little and big cluster core counts, and whether we're aiming for performance or power efficiency in each case. In terms of low- to medium-performance threads, we've had several cases where 4 little cores weren't enough. Web page rendering in Chrome in particular seems to be the killer use-case where actually having two clusters of highly efficient cores makes sense.
On the high-performance "big" cluster side, the discussion topic is more about whether 2 or 4 core designs make more sense. I think the decision here is not about performance but rather about power efficiency. A 2-core big-cluster design would provide more than enough performance for most use-cases, but as we've seen throughout our testing during interactive use it's more common than not to have 2+ threads placed on the big cluster. So while a 2-core design could handle bursts where ~3-4 threads are placed onto the big cluster, the CPUs would need to scale up higher in frequency to provide the same performance compared to a wider 4-core design. And scaling up higher in frequency has a quadratically detrimental effect on power efficiency as we need higher operating voltages. At the end of the day I think the 4 big core designs are not only the better performing ones but also the more efficient ones.
This puts one particular vendor in quite of an interesting position: MediaTek. Even if one wouldn't be able to fully saturate a cluster one can still derive power efficiency advantages due to the fact that two small clusters would be able to operate at separate frequencies and thus efficiency points. I've encountered enough scenarios that would in theory fit the Helio X20's tri-cluster design that I'm starting to think that such a design would actually be a very smart choice for current Android devices.

What about more traditional SoC configurations? As mentioned earlier symmetric 8-core designs such as MediaTek's Helio X10 would, contrary to one's expectations, be seemingly able to take advantage of their higher core counts. So while it would be preferable to have higher performance cores such as Cortex A57's or A72's, one has to keep in mind the target market of these architectures are limited to higher-end SoCs. The 8 little-core designs are mostly targeted at the entry- and mid-level where adding a second Cortex A53 cluster can be very cheap way of still providing benefits in every-day usages, particularly in web-browsing.
What is clear though albeit there are corner-cases, is that the vast majority of applications do seem to be optimal for quad-core SoCs. This is why traditional 4-core and 4.4 big.LITTLE designs still appear to make the most sense in terms providing a balanced configuration and making most use of the hardware at hand. For big.LITTLE, even if there were no use-cases where all cores are concurrently used, it's not a big deal as what we are aiming for in heterogeneous systems is power efficiency gains.
This is also the point of the discussion where the debate of the potential detrimental effect of having more cores comes into play: The fact that a SoC has more cores does not automatically mean it uses more power. As demonstrated in the data, modern power management is advanced enough to make extensive use of fine-grained power-gated idle states, thus eliminating any overhead there might be of simply having more physical cores on the silicon. If there are cases (And as we've seen, there are!) which make use of more cores then this should be seen purely as an added bonus and icing on the cake.
What about narrow CPU-core number design philosophies? Would such designs make sense on Android? This is probably another question that our readers will ask themselves when looking at the data. Apple and recently Nvidia with their Denver architecture both choose to keep going the route of employing large 2-core designs that are strong in their single-threaded performance but fall behind in terms of multi-threaded performance.
While for Apple it can be argued that we're dealing with a very different operating system and it is likely iOS applications are less threaded than their Android counter-parts. But there are cases where this doesn't need to be necessarily hold true: For example browser rendering engines, as demonstrated, can be multi-threaded if adapted to do so. Native high-end games which already make use of multiple threads are also unlikely to differ in their threading logic between the platforms.
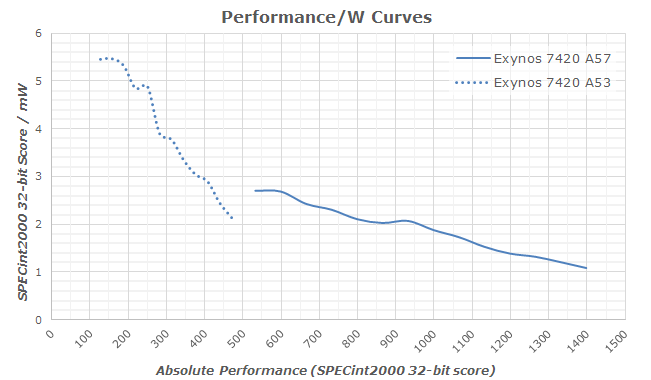
While such narrow CPU-core designs would have higher performance at a given frequency - it is not a direct indicator of the actual performance/W efficiency that a single thread would have on these chipsets. We still haven't had a chance to make a proper apples-to-apples comparison for these architectures so we're limited to theorycrafting with the data we currently have available to us:
What we see in the use-case analysis is that the amount of use-cases where an application is visibly limited due to single-threaded performance seems be very limited. In fact, a large amount of the analyzed scenarios our test-device with Cortex A57 cores would rarely need to ramp up to their full frequency beyond short bursts (Thermal throttling was not a factor in any of the tests). On the other hand, scenarios were we'd find 3-4 high load threads seem not to be that particularly hard to find, and actually appear to be an a pretty common occurence. For mobile, the choice seems to be obvious due to the power curve implications. In scenarios where we're not talking about having loads so small that it becomes not worthwhile to spend the energy to bring a secondary core out of its idle state, one could generalize that if one is able to spread the load over multiple CPUs, it will always preferable and more efficient to do so.
In the end what we should take away from this analysis is that Android devices can make much better use of multi-threading than initially expected. There's very solid evidence that not only are 4.4 big.LITTLE designs validated, but we also find practical benefits of using 8-core "little" designs over similar single-cluster 4-core SoCs. For the foreseeable future it seems that vendors who rely on ARM's CPU designs will be well served with a continued use of 4.4 b.L designs. Only MediaTek seems to fall out of the norm here with its upcoming X20 SoC, which I'm definitely looking forward to see as to how it behaves in the real-world. We'll also see some vendors revert back to quad-core designs in their custom architectures - while we've yet to get a better picture of how these will behave in terms of performance and power, I think that 4 cores will be a quite reasonable target and sweet-spot for vendors to aim for.








157 Comments
View All Comments
rstuart - Tuesday, September 1, 2015 - link
Wow, excellent article. Colour me impressed that the developers use 4 cores effectively more times than not. It was not what I was expecting. Nor did I realise how much of the video processing task was offloaded to the GPU. In fact it's so good I suspect there will be more than a few electrical engineers poring over this in order to understand how well their software brethren make use of the hardware they provide.Filiprino - Tuesday, September 1, 2015 - link
Are you sure the Galaxy S6 employs the CFS scheduler? Should not it be the GTS scheduler?Andrei Frumusanu - Tuesday, September 1, 2015 - link
GTS is just an extension on top of CFS.Filiprino - Wednesday, September 2, 2015 - link
Well, yes. But it's not the same saying CFS or GTS. I think it should be noted that the phone is using GTS whose run queues work like in CFS.Andrei Frumusanu - Saturday, September 5, 2015 - link
GTS doesn't touch runqueues. GTS's modification to the CFS scheduler are relatively minor, it's still very much CFS at the core.AySz88 - Tuesday, September 1, 2015 - link
A technical note regarding "...scaling up higher in frequency has a quadratically detrimental effect on power efficiency as we need higher operating voltages..." - note that power consumption *already* goes up quadratically as voltage squared, BEFORE including the frequency change (i.e. P = k*f*v*v). So if you're also scaling up voltage while increasing frequency, you get a horrific blowing-up-in-your-face CUBIC relationship between power and frequency.ThreeDee912 - Tuesday, September 1, 2015 - link
Being in the Apple camp, I do know Apple also highly encourages developers to use multithreading as much as possible with their Grand Central Dispatch API, and has implemented things like App Nap and timer coalescing to help with the "race-to-idle" in OS X. I'm guessing Apple is likely taking this into account when designing their ARM CPUs as well. The thing is, unlike OS X, iOS and their A-series CPUs are mostly a black box of unknowns, other than whatever APIs they let developers use.jjj - Wednesday, September 2, 2015 - link
For web browsing i do wish you would look at heavier sites, worst case scenario since that's when the device stumbles and look at desktop versions.Would be nice to have a total run-queue depth graph normalized for core perf and clocks ( so converted in total perf expressed in w/e unit you like) to see what total perf would be needed (and mix of cores) with an ideal scheduler - pretty hard to do it in a reasonable way but it would be an interesting metric. After all the current total is a bit misleading by combining small and big , it shows facts but ppl can draw the wrong conclusions, like 4 cores is enough or 8 is not. Many commenters seem to jump to certain conclusions because of it too.
Would be nice to see the tests for each cluster with the other cluster shut down, ideally with perf and power measured too. Would help address some objections in the comments.
In the Hangouts launch test conclusion you say that more than 4 cores wouldn't be needed but that doesn't seem accurate outside the high end since if all the cores were small. assuming the small cores would be 2-3 times lower perf, then above 1.5 run-queue depth on the big cores might require more than 4 small cores if we had no big ones. Same goes for some other tests
A SoC with 3 types of cores , 2 of them big ,even bigger than A72 , and a bunch of medium and small does seem to make sense, with a proper scheduler and thermal management ofc. For midrange 2+4 should do and it wouldn't increase the cost too much vs 8 small ones, depending a bit on cache size - lets say on 16ff A53 bellow 0.5mm2 , A72 1.15mm2 and cache maybe close to 1.7 mm2 per 1MB. so a very rough approximation would be 2-3mm2 penalty depending if the dual A72 has 1 or 2MB L2. a lot more if the dual A72 forces them to add a second memory chan but even then it's worth the cost, 1-2$ more for the OEM would be worth it given the gain in single threaded perf and the marketing benefits
When looking at perf and battery in the real world multitasking is always present in some way. in benchmarks, never is. So why not try that too, something you encounter in daily usage. a couple of extra threads from other things should matter enough - maybe on Samsung devices you could test in split screen mode too, since it's something ppl do use and actually like.
For games it would be interesting to plot GPU clocks and power or temps as well as maybe FPS. Was expecting games to use the small cores more to allow for more TDP to go to the GPU and the games you tested do seem to do just that. Maybe you could look at a bunch of games from that perspective. Then again, it would be nice if AT would just start testing real games instead of synthetic nonsense that has minimal value and relevance
A look at image processing done on CPU+GPU would be interesting.
The way Android scales on many cores is encouraging for glasses where every cubic mm matters and batteries got to be tiny. Do hope the rumored Mercury core for wearables at 50-150mW is real and shows up soon.
Oh and i do support looking at how AT's battery of benchmarks is behaving but a better solution would be to transition away from synthetic, no idea why it takes so long in mobile when we had the PC precedent and nobody needs an explanation as to why synthetic benchmarks are far from ideal.
Anyway, great to see some effort in actually understanding mobile, as opposed to dubious synthetic benchmarks and empty assumptions that have been dominating this scene.AT should hire a few more people to help you out and increase the frequency of such articles since there are lots of things to explore and nobody is doing it.
tuxRoller - Wednesday, September 2, 2015 - link
Linux had largely been guided towards massively multiprocess workloads. If they didn't do this well then they wouldn't do anything well.The scheduler should be getting a lot better soon. It APPEARS that, after a long long long long time, things are moving forward on the combined scheduler (cfs), cpuidle, and cpufreq (dvfs) front. That's necessary in order to proper scheduling of tasks, especially across an aSMP soc.
One thing to keep in mind is that these oems often carry out of tree patches that they believe help their hardware. Often these patches are of, ahem, suspect quality, and pretty much always perform their task with some noticeable drawbacks. The upstream solution is (almost?) always "better".
Iow, things should only get better.
toyotabedzrock - Wednesday, September 2, 2015 - link
Is Chrome rendering pages it expects you to visit on the little cores?You should test with Chrome DEV as well.