The Intel Broadwell Review Part 2: Overclocking, IPC and Generational Analysis
by Ian Cutress on August 3, 2015 8:00 AM ESTComparing IPC: Memory Latency and CPU Benchmarks
Being able to do more with less, in the processor space, allows both the task to be completed quicker and often for less power. While the concept of having multiple cores has allowed many programs to be run at once, such as IM, web, compute and so forth, we are all still limited by the fact that a lot of software is still relying on one line of code after another, pegging each software package to once core unless it can exploit a mulithreaded list of operations. This is referred to as the serial part of the software, and is the basis for many early programming classes – getting the software to compile and complete is more important than speed. But the truth is that having a few fast cores helps more than several thousand super slow cores. This is where Instructions Per Clock (IPC) comes in to play.
The principles behind extracting IPC are quite complex as one might imagine. Ideally every instruction a CPU gets should be read, executed and finished in one cycle, however that is never the case. The processor has to take the instruction, decode the instruction, gather the data (depends on where the data is), perform work on the data, then decide what to do with the result. Moving has never been more complicated, and the ability for a processor to hide latency, pre-prepare data by predicting future events or keeping hold of previous events for potential future use is all part of the plan. All the meanwhile there is an external focus on making sure power consumption is low and the frequency of the processor can scale depending on what the target device actually is.
For the most part, Intel has successfully increased IPC every generation of processor. In most cases, 5-10% with a node change and 5-25% with an architecture change with the most recent large jumps being with the Core architecture and the Sandy Bridge architectures, ushering in new waves of super-fast computational power. As Haswell to Broadwell is a node change with minor silicon updates, we should expect some gain but the main benefit should be efficiency by moving to a smaller node.
For this test we took Intel’s high-end i7 processors from the last four generations and set them to 3.0 GHz and with HyperThreading disabled. As each platform uses DDR3, we set the memory across each to DDR3-1866 with a CAS latency of 9. From a pure cache standpoint, here is how each of the processors performed:
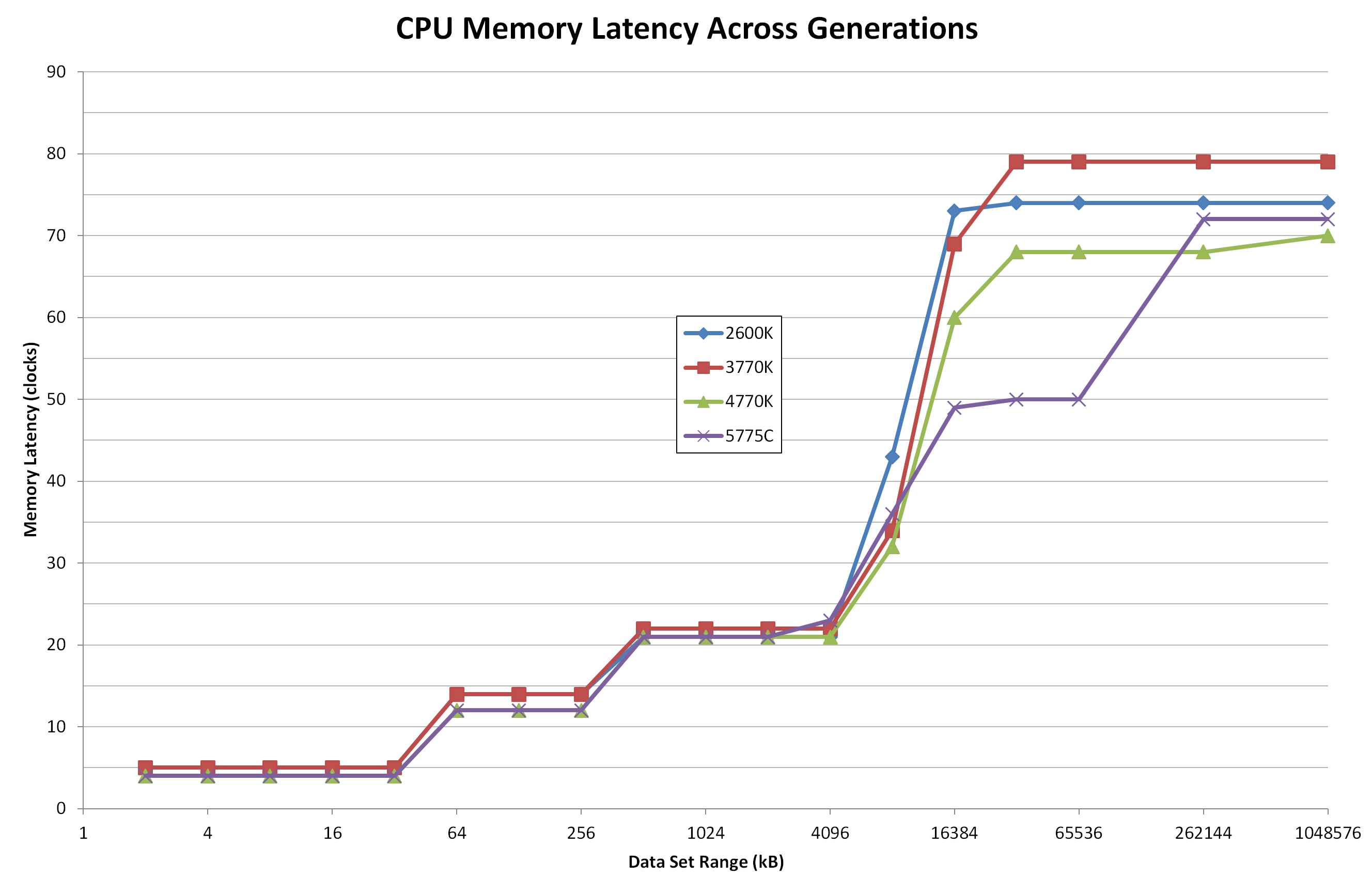
Both Haswell and Broadwell have a small lead through the Level 1 Cache (32kB) and Level 2 Cache (256kB). It all changes from 6MB onwards as a result of the different cache levels between the processors. As the Broadwell based i7-5775C only has 6MB of L3 cache, this seems to effect the 4MB data set range, but between 8MB and 64MB values, the memory latency for Broadwell is substantially lower than any other Intel processor. This comes down to the eDRAM, which sticks around until 128MB.
Most memory accesses happen at lower data set ranges as the system attempts to predict the data needed. When data is not in the L1 cache, it is considered a cache miss and looks for the data in L2. When not in L2, look in L3. When not in L3, look in eDRAM/DDR3. From this perspective, the Broadwell based processors should have a slight advantage when it comes to large amounts of data accesses. Based on our previous testing, this means integrated graphics or high intensity CPU/DRAM workloads such as databases or matrix operations.
Here are the CPU results at 3.0 GHz:
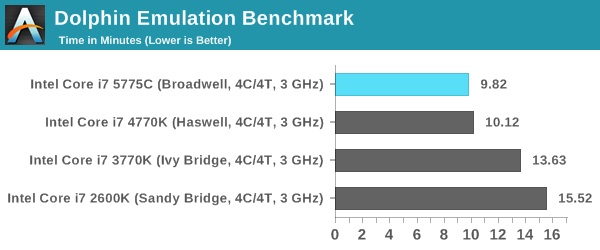
Dolphin Benchmark: link
Many emulators are often bound by single thread CPU performance, and general reports tended to suggest that Haswell provided a significant boost to emulator performance. This benchmark runs a Wii program that raytraces a complex 3D scene inside the Dolphin Wii emulator. Performance on this benchmark is a good proxy of the speed of Dolphin CPU emulation, which is an intensive single core task using most aspects of a CPU. Results are given in minutes, where the Wii itself scores 17.53 minutes.
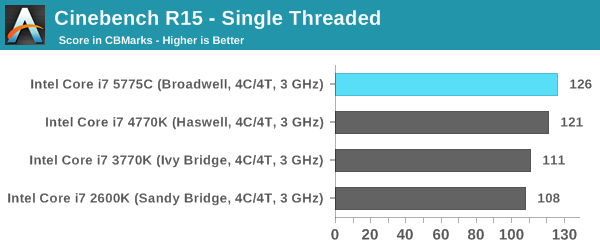
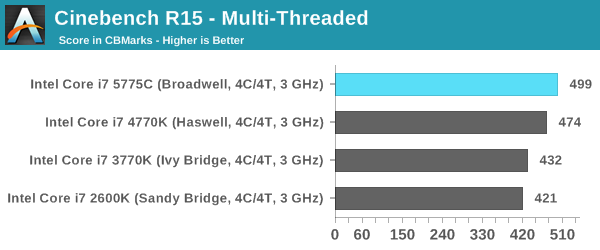
Cinebench R15
Cinebench is a benchmark based around Cinema 4D, and is fairly well known among enthusiasts for stressing the CPU for a provided workload. Results are given as a score, where higher is better.
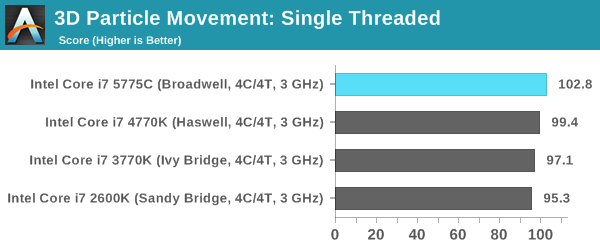
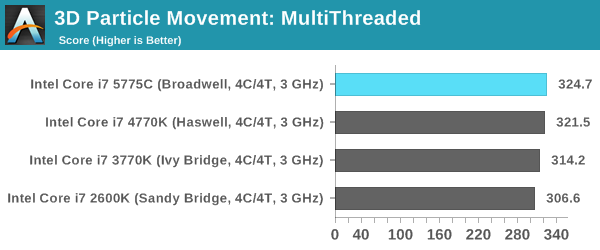
Point Calculations – 3D Movement Algorithm Test: link
3DPM is a self-penned benchmark, taking basic 3D movement algorithms used in Brownian Motion simulations and testing them for speed. High floating point performance, MHz and IPC wins in the single thread version, whereas the multithread version has to handle the threads and loves more cores. For a brief explanation of the platform agnostic coding behind this benchmark, see my forum post here.
Compression – WinRAR 5.0.1: link
Our WinRAR test from 2013 is updated to the latest version of WinRAR at the start of 2014. We compress a set of 2867 files across 320 folders totaling 1.52 GB in size – 95% of these files are small typical website files, and the rest (90% of the size) are small 30 second 720p videos.

Image Manipulation – FastStone Image Viewer 4.9: link
Similarly to WinRAR, the FastStone test us updated for 2014 to the latest version. FastStone is the program I use to perform quick or bulk actions on images, such as resizing, adjusting for color and cropping. In our test we take a series of 170 images in various sizes and formats and convert them all into 640x480 .gif files, maintaining the aspect ratio. FastStone does not use multithreading for this test, and thus single threaded performance is often the winner.

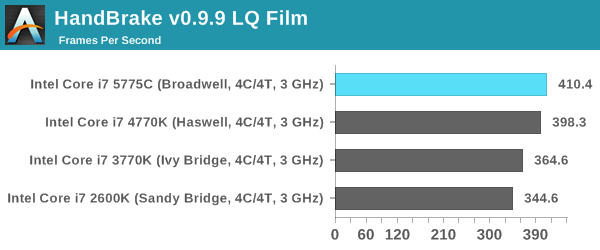
Video Conversion – Handbrake v0.9.9: link
Handbrake is a media conversion tool that was initially designed to help DVD ISOs and Video CDs into more common video formats. The principle today is still the same, primarily as an output for H.264 + AAC/MP3 audio within an MKV container. In our test we use the same videos as in the Xilisoft test, and results are given in frames per second.

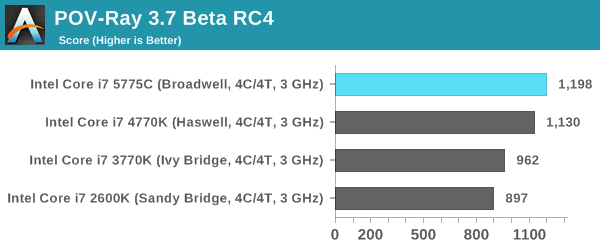
Rendering – PovRay 3.7: link
The Persistence of Vision RayTracer, or PovRay, is a freeware package for as the name suggests, ray tracing. It is a pure renderer, rather than modeling software, but the latest beta version contains a handy benchmark for stressing all processing threads on a platform. We have been using this test in motherboard reviews to test memory stability at various CPU speeds to good effect – if it passes the test, the IMC in the CPU is stable for a given CPU speed. As a CPU test, it runs for approximately 2-3 minutes on high end platforms.
Synthetic – 7-Zip 9.2: link
As an open source compression tool, 7-Zip is a popular tool for making sets of files easier to handle and transfer. The software offers up its own benchmark, to which we report the result.
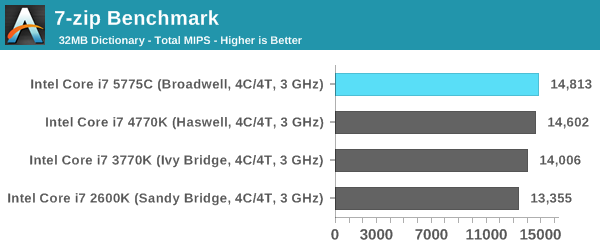
Overall: CPU IPC
*When this section was published initially, the timed benchmarks (those that rely on time rather than score) were caluclated incorrectly. The text has been updated to reflect the new calculations.
Removing WinRAR as a benchmark that obviously benefits from the eDRAM, we get an interesting look at how each generation has evolved over time. Taking Sandy Bridge (i7-2600K) as the base, we get the following:

As we can see, performance gains are everywhere although the total benefit is highly dependent on the benchmark in question. Cinebench in single threaded mode for example gives a 16.7% gain from Sandy Bridge to Broadwell, however Dolphin which is also single threaded gets a 58.1% improvement. Overall, a move from Sandy Bridge to Broadwell from an IPC perspective gives an average ~21% improvement. That is an increase in pure, raw throughput before considering frequency or any differentiator in core counts.
If we adjust this graph to show generation to generation improvement:
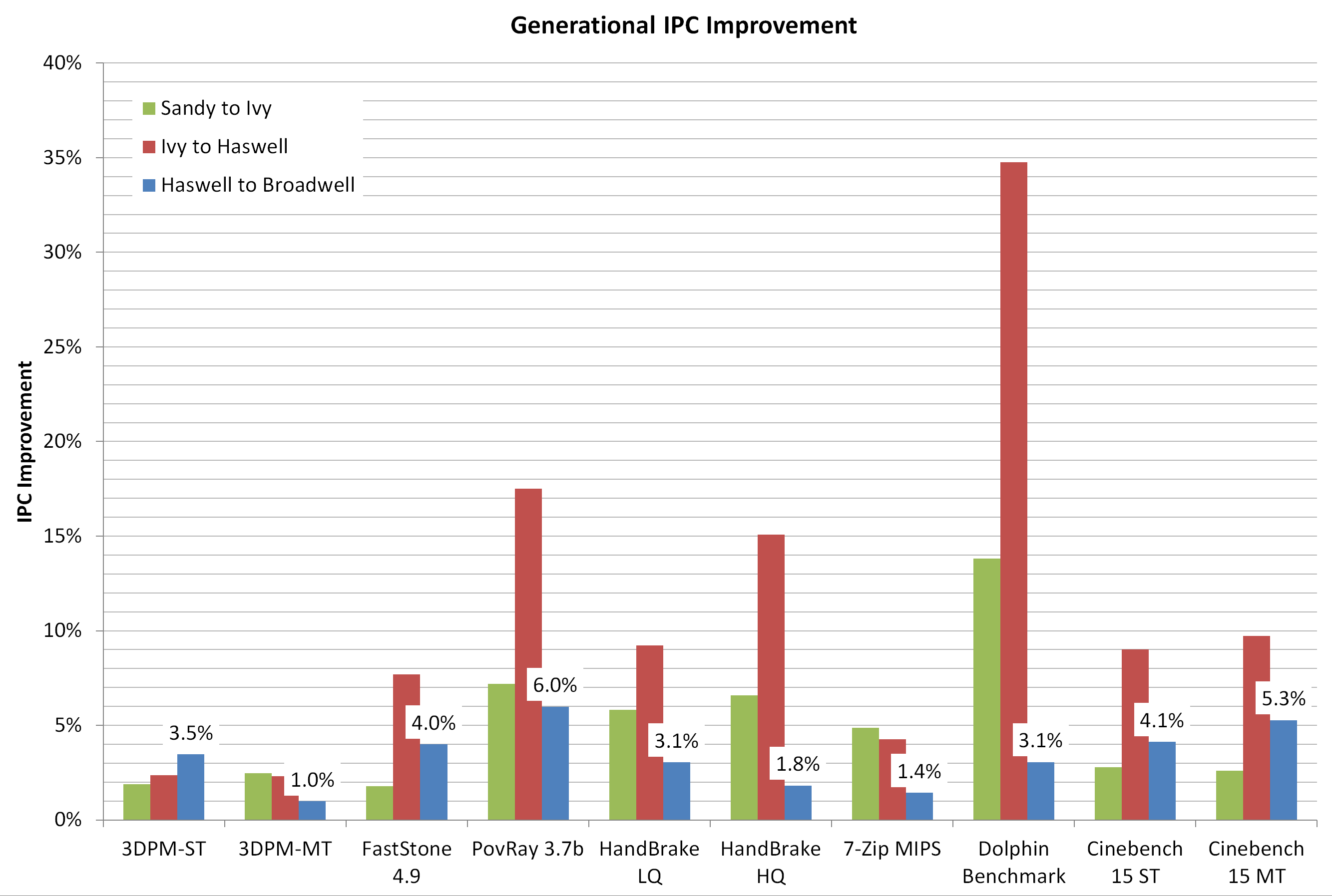
This graph shows something a little bit different. From these numbers:
Sandy Bridge to Ivy Bridge: Average ~5.0% Up
Ivy Bridge to Haswell: Average ~11.2% Up
Haswell to Broadwell: Average ~3.3% Up
Thus in a like for like environment, when eDRAM is not explicitly a driver for performance, Broadwell gives a 3.3% gain over Haswell. That’s a take home message worth considering, but it also affords the difference in performance between an architecture update and a node change.
Cycling back to our WinRAR test, things look a little different. Ivy Bridge to Haswell gives only a 3.2% difference, but the eDRAM in Broadwell slaps on another 23.8% performance increase, dropping the benchmark from 76.65 seconds to 63.91 seconds. When eDRAM counts, it counts a lot.








121 Comments
View All Comments
name99 - Monday, August 3, 2015 - link
Well think about WHY these results are as they are:- There is one set of benchmarks (most of the raytracing and sci stuff) that can make use of AVX. They see a nice boost from initial AVX (implemented by routing each instruction through the FPU twice) to AVX on a wider execution unit to the introduction of AVX2.
- There is a second set of benchmarks (primarily winRAR) that manipulate data which fits in the crystalwell cache but not in the 8MB L3). Again a nice win there; but that's a specialized situation. In data streaming examples (which better described most video encode/decode/filtering) that large L4 doesn't really buy you anything.
- There WOULD be a third set of benchmarks (if AnandTech tested for this) that showed a substantial improvement in indirect branch performance going from IB to Haswell. This is most obvious on interpreters and similar such code, though it also helps virtual functions in C++/Swift style code and Objective C method calls. My recollection is that you can see this jump in the GeekBench Lua benchmark. (Interestingly enough, Apple's A8 seems to use this same advanced TAGE-like indirect predictor because it gets Lua IPC scores as good as Intel).
OK, no we get to Skylake. Which of these apply?
- No AVX bump except for Xeons.
- Usually no CrystalWell
So the betting would be that the BIG jumps we saw won't be there. Unless they've added something new that they haven't mentioned yet (eg a substantially more sophisticated prefetcher, or value prediction), we won't even get the small targeted boost that we saw when Haswell's indirect predictor was added. So all we'll get is the usual 1 or 2% improvement from adding 4 or 6 more physical registers and ROB slots, maybe two more issue slots, a few more branch predictor slots, the usual sort of thing.
There ARE ideas still remaining in the academic world for big (30% or so) improvements in single-threaded IPC, but it's difficult for Intel to exploit these given how complex their CPUs are, and how long the pipeline is from starting a chip till when it ships. In the absence of competition, my guess is they continue to play it safe. Apple, I think, is more likely to experiment with these ideas because their base CPU is a whole lot easier to understand and modify, and they have more competition.
(Though I don't expect these changes in the A9. The A7 was adequate to fight off the expected A57; the A8 is adequate to fight off the expected A72; and all the A9 needs to do to maintain a one year plus lead is add the ARMv81.a ISA and the same sort of small tweaks and a two hundred or so MHz boost that we saw applied to the A8. I don't expect the big microarchitectural changes at Apple until
- they've shipped ARMv81.a ISA
- they've shipped their GPU (tightly integrated HSA style with not just VM and shared L3, but with tighter faster coupling between CPU and GPU for fast data movement, and with the OS able to interrupt and to some extent virtualize the GPU)
- they're confident enough in how wide-spread 64-bit apps are that they don't care about stripping out the 32-bit/thumb ISA support in the CPU [with what they implies for the pipeline, in particular predication and barrel shifter] and can create a microarchitecture that is purely optimized for the 64-bit ISA.
Maybe this will be the A10, IF the A9 has ARMv8.1a and an Apple GPU.)
Speedfriend - Tuesday, August 4, 2015 - link
"The A7 was adequate to fight off the expected A57;"In hindsight the A7 was not very good at all, it was the reason that Apple was unable to launch a large screen phone with decent battery life. Look at he improvements made to A8, around 10% better performance, but 50% more battery life.
Speedfriend - Tuesday, August 4, 2015 - link
"they've shipped their GPU" by the way, why do you expect them to ship their own GPU and not use IMG's. The IMG GPU have consistently been the best in the market.nunya112 - Monday, August 3, 2015 - link
by the looks of it. the 4790K seems to be the best CPU. until skylake that is. but even then I doubt there will be much improvementnunya112 - Monday, August 3, 2015 - link
unless u have the older ivy's then yeah maybe worth it ?TheinsanegamerN - Monday, August 3, 2015 - link
Nah. the older ivys can be overclocked to easily meet these chips. the IPC of broadwell is overshadowed by a 400mhz lower clock rate on typical OC. only reason to upgrade is if you NEED something on the new chipset or are running some nehalem-era chip.Teknobug - Monday, August 3, 2015 - link
Ivy's are the best overclockers.TheinsanegamerN - Monday, August 3, 2015 - link
Sandy overclocked better than ivy,Hulk - Monday, August 3, 2015 - link
Ian - Very nice job on this one! Thanks.Meaker10 - Monday, August 3, 2015 - link
A slight correction, on the image of crystal well it is the die on the left (the much larger one) which is the cache and the small one is the cpu on the right.