AMD Dives Deep On High Bandwidth Memory - What Will HBM Bring AMD?
by Ryan Smith on May 19, 2015 8:40 AM ESTHBM: Wide & Slow Makes It Fast
Given the challenges faced in pushing GDDR5 and similar memory technologies even further, development of high bandwidth memory technology has in the last decade shifted back towards wider, slower interfaces. As serial interfaces reach their limits, parallel interfaces become an increasingly viable alternative. And although they bring with them their own challenges – there’s a reason serial interfaces have been dominant most recently, after all – the ramp up of challenges in further improving serial interfaces has coincided with the development of technologies that make parallel interfaces easier to implement. As a result the pendulum has swung back to parallel interfaces and HBM.
HBM in a nutshell takes the wide & slow paradigm to its fullest. Rather than building an array of high speed chips around an ASIC to deliver 7Gbps+ per pin over a 256/384/512-bit memory bus, HBM at its most basic level involves turning memory clockspeeds way down – to just 1Gbps per pin – but in exchange making the memory bus much wider. How wide? That depends on the implementation and generation of the specification, but the examples AMD has been showcasing so far have involved 4 HBM devices (stacks), each featuring a 1024-bit wide memory bus, combining for a massive 4096-bit memory bus. It may not be clocked high, but when it’s that wide, it doesn’t need to be.

Of course while extra memory bandwidth is nice, the far more interesting part is how HBM delivers this. Although the idea of a wide, slow parallel bus is easy enough to comprehend on paper, implementing it is a whole other matter. A 4096-bit memory bus involves thousands of traces, far more than GDDR5, all of which must be carefully constructed in order to make HBM work. As a result there are a couple of fundamental technologies that are seeing their big (though not necessarily initial) introduction with HBM.
The first and most fundamental matter is how do you efficiently route a 4096-bit memory bus? Even the best surface mounting BGA technologies have their limits, and as it is Hawaii was pushing things with its 512-bit GDDR5 memory bus. An even wider bus only makes that harder, inviting issues both with the routing such a wide bus on a PCB or chip substrate, and in using BGA to connect a chip to those traces.
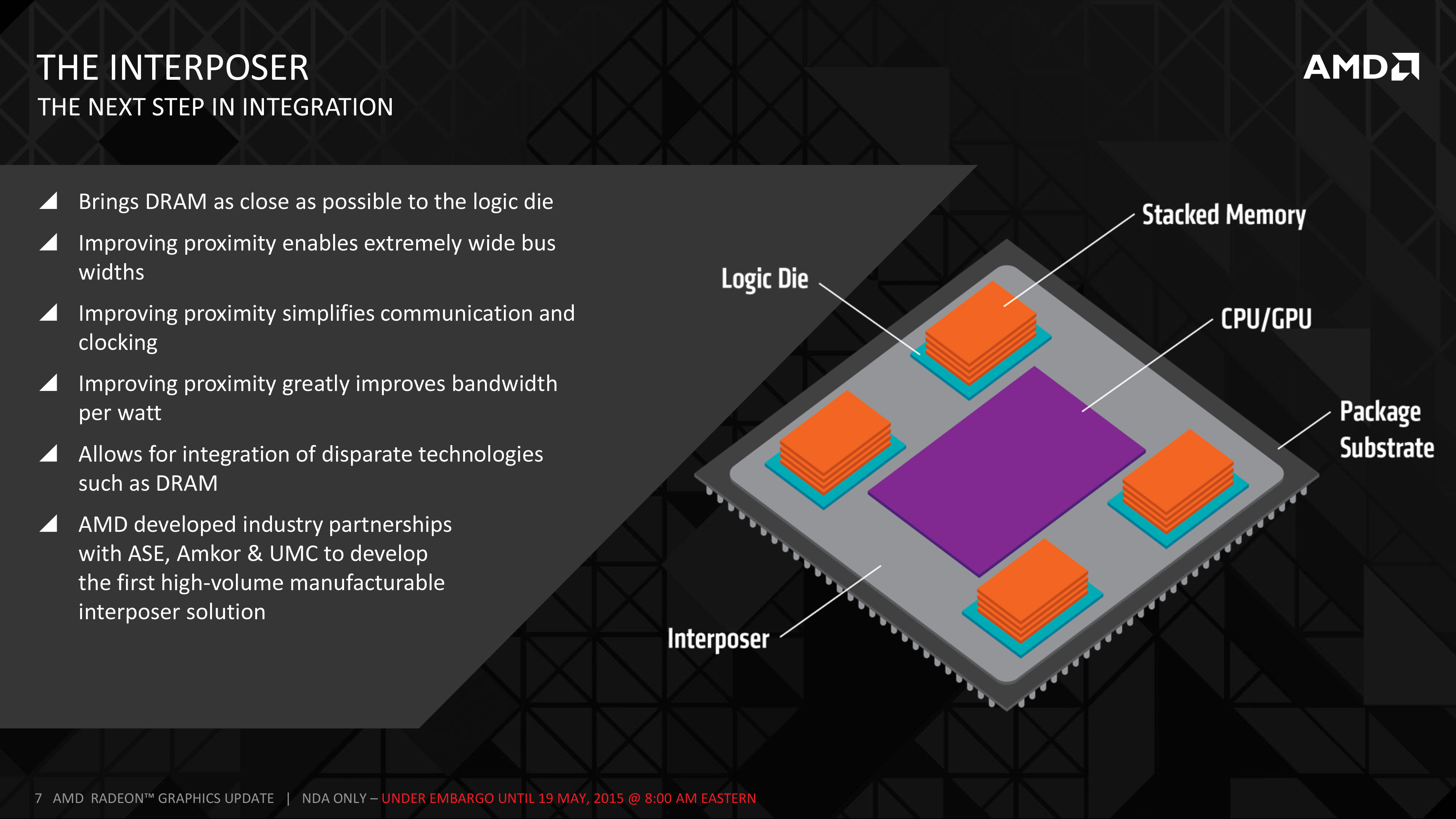
First part of the solution to that in turn was to develop something capable of greater density routing, and that something was the silicon interposer. The interposer in its broadest terms is a partially fabbed silicon chip that instead of being developed into a full ASIC packed with logic, is only developed as far as having metal layers, in order to route signals and power among devices. The interposer in turn works because it exploits some of the core advantages of modern photolithographic processes, allowing for very fine paths to be created that would otherwise not be possible/practical on traditional PCBs and substrates.
Using a silicon interposer solves some of the fundamental problems with HBM, but it also provides some ancillary benefits as well. Along with solving the obvious routing issue, the interposer allows for DRAM to be placed very close to an ASIC, but without being placed on top of it (ala Package-on-package), which is impractical for high TDP devices like GPUs. By being able to place DRAM so close to the ASIC, it avoids the drawbacks of long memory paths, making the shorter paths both simpler to construct and require less power in the process. It also benefits integration, as similar to PoP technology, you can have more of the device’s functionality located on the same package as the ASIC, reducing the number of devices that need to be placed off-package and routed to the ASIC.
Of course the interposer does come with a drawback as well, and that’s cost. While AMD is not talking about costs in great detail – this is a technology deep dive, not an analyst meeting – the fact that the interposer is essentially a very large, partially developed silicon chip means that it’s relatively expensive to produce, especially compared to the very low costs of PCBs and traditional substrates. Mitigating this is the fact that interposers don’t need to go through the most complex and expensive phases of photolithography – the actual front-end lithography – so the cost is only the silicon wafer itself, along with the work required to create the metal layers, with the final interposer only being some 100 microns thick. Furthermore this doesn’t require cutting-edge fabs – old, fully amortized 65nm equipment works quite well – which further keeps the costs down. The end result is that the interposer is still a significant cost, but it is not as bad as it initially seems. This ultimately is why HBM will first be introduced on high margin products like high-end video cards before potentially making its way down to cheaper devices like APUs.
Meanwhile AMD and their vendors will over the long run also benefit from volume production. The first interposers are being produced on retooled 65nm lithographic lines, however once volume production scales up, it will become economical to develop interposer-only lines that are cheaper to operate since they don’t need the ability to offer full lithography as well. Where that cut-off will be is not quite clear at this time, though it sounds like it will happen sooner than later.
Looking at the broader picture, in the grand scheme of things the interposer becomes a new layer on a complete chip, sitting between the traditional substrate and any DRAM/ASICs mounted on top of it. Microbumps will connect the DRAM and ASICs to the interposer, and the interposer will then be connected to the substrate, before finally the substrate is connected to its partner PCB. PCB mounting itself will become a bit easier in the process, as there’s no longer a need to route memory traces through the substrate, which means the only remaining connections are data (PCIe bus, etc) and power for the ASIC and DRAM. All the complex routing is essentially localized to occurring at the interposer layer.

Moving on, the other major technological breakthrough here is the creation of through-silicon vias (TSVs). With the interposer to enable the routing of a dense memory bus, the other issue to solve was the creation of dense memory. The solution to this was to stack multiple memory dies together into a single device/stack, in order to create the single 1024-bit stack, and TSVs are in turn what make this possible.
The reason for stacking DRAM is pretty straightforward: it makes production easier by reducing the DRAM to fewer discrete devices, not to mention it saves space. The challenge here is that you can’t have traditional surface mount connections since the DRAM is stacked, and traditional edge connections (as used in PoP) are neither dense enough nor do they scale well to the kind of stacks HBM would require.
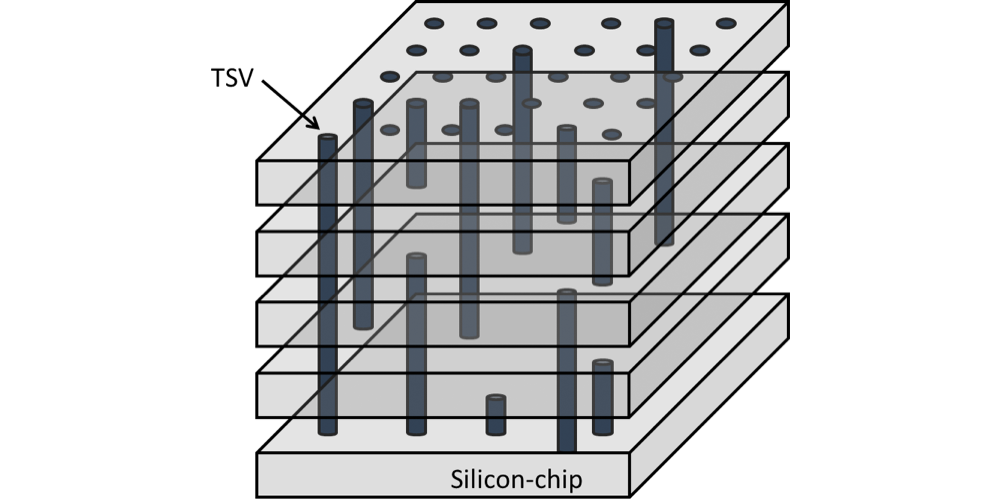
TSVs. Image Courtesy The International Center for Materials Nanoarchitectonics
As a result a means was needed to route DRAM connections though the lower layers of the stack, and this problem was solved with TSVs. Whereas regular vias offer the ability to connect two layers together, TSVs extend this principle by running the vias straight through silicon devices in order to connect layers farther out. The end result is something vaguely akin to DRAM dies surface mounted on top of each other via microbumps, but with the ability to communicate through the layers. From a manufacturing standpoint, between the silicon interposer and TSVs, TSVs are the more difficult technology to master as it essentially combines all the challenges of DRAM fabbing with the challenges of stacking those DRAM dies on top of each other.
Having developed the means to stack DRAM, the final component of an HBM stack is a logic die that lies on the bottom of the stack. Similarly outfitted with TSVs, the logic die is responsible for actually operating the DRAM dies above it, and then handling the operation of the HBM bus between the stack and the ASIC. This actually ends up being a rather interesting development since the net result is more logic added despite the simplicity of the HBM bus, but at the same time thanks to TSVs and the interposer, it’s easier than ever to add that logic.








163 Comments
View All Comments
testbug00 - Tuesday, May 19, 2015 - link
Name long term good relationships that Nvidia has had with other companies in the industry. Besides their board partners. You could argue TSMC either way. Otherwise, I'm getting nothing. They recently have a relationship with IBM that could become long term. It is entirely possible I'm just missing the companies they partner with that are happy with their partnership in the semi-conductor industry.Compared to IBM, TSMC, SK Hynix, and more.
ImSpartacus - Tuesday, May 19, 2015 - link
Can we have an interview with Joe Macri? He seems like a smart fella if he was the primary reference for this article.wnordyke - Tuesday, May 19, 2015 - link
This analysis does not discuss the benefits of the base die? The base die contains the memory controller and a data serializer. The architecture of moving the memory controller to the base die simplifies the design and removes many bottlenecks. The Base die is large enough to support a large number of circuits. (#1 memory controller, #2 Cache, #3 data processing)The 4096 wires is a large number and 4096 I/O buffers is a large number. The area of 4096 I/O buffers on the GPU die is expensive, and this expense is easily avoided by placing the memory controller on the base die. The 70% memory Bus efficiency is idle bandwidth, and this idle data does not need to be sent back to the GPU. The 4096 Interposer signals reduces to (4096 * 0.7 = 2867) saving 1,229 wires + I/O buffers.
A simple 2 to 1 serializer would reduces down to (2867 * 0.50 = 1432). The Interposer wires are short enough to avoid the termination resistors for a 2GHz signal. Removing the termination resistors is top of the list to saving power, the second on the list to save power is to minimize the Row Activate.
takeship - Tuesday, May 19, 2015 - link
So am I correct in assume then that the 295x2 equivalent performance numbers for Fiji leaked months ago are for the dual gpu variant? It concerns me that at no point in this write up did AMD even speculate what the performance inc with HBM might be.dew111 - Tuesday, May 19, 2015 - link
Why is everyone concerned about the 4GB limit in VRAM? A few enthusiasts might be disappointed, but for anyone who isn't using multiple 4k monitors, 4GB is just fine. It might also be limiting in some HPC workloads, but why would any of us consumers care about that?chizow - Wednesday, May 20, 2015 - link
I guess the concern is that people were expecting AMD's next flagship to pick up where they left off on the high-end, and given how much AMD has touted 4K, that would be a key consideration. Also, there are the rumors this HBM part is $850 to create a new AMD super high-end, so yeah, if you're going to say 4K is off the table and try to sell this as a super premium 4K part, you're going to have a hard sell as that's just a really incongruent message.In any case, AMD says they can just driver-magic this away, which is a recurring theme for AMD, so we will see. HBM's main benefits are VRAM to GPU transfers, but anything that doesn't fit in the local VRAM are still going to need to come from System RAM or worst, local storage. Textures for games are getting bigger than ever...so yeah not a great situation to be stuck at 4GB for anything over 1080p imo.
zodiacfml - Tuesday, May 19, 2015 - link
Definitely for their APUs and mobile. Making this first on GPUs helps recover the R&d without the volume scale.SolMiester - Tuesday, May 19, 2015 - link
Do the R9 290\x really perform that much better with OC memory on the cards? I didnt think AMD was ever really constrained by bandwidth, as they usually always had more on their generation of cards.Consequently, I dont see 390\x being that much competition to Titan X
Intel999 - Tuesday, May 19, 2015 - link
Thanks SolMiester,You have done an excellent job of displaying your level of intelligence. I don't think the New York Giants will provide much competition to the rest of the NFL this year. I won't support my prediction with any facts or theories just wanted to demonstrate that I am not a fan of the Giants.
BillyHerrington - Tuesday, May 19, 2015 - link
Since HBM are owned by AMD & Hynix, does other company (nvidia, etc) have to pay AMD in order to use HBM tech ?