AMD Dives Deep On High Bandwidth Memory - What Will HBM Bring AMD?
by Ryan Smith on May 19, 2015 8:40 AM ESTHBM: Wide & Slow Makes It Fast
Given the challenges faced in pushing GDDR5 and similar memory technologies even further, development of high bandwidth memory technology has in the last decade shifted back towards wider, slower interfaces. As serial interfaces reach their limits, parallel interfaces become an increasingly viable alternative. And although they bring with them their own challenges – there’s a reason serial interfaces have been dominant most recently, after all – the ramp up of challenges in further improving serial interfaces has coincided with the development of technologies that make parallel interfaces easier to implement. As a result the pendulum has swung back to parallel interfaces and HBM.
HBM in a nutshell takes the wide & slow paradigm to its fullest. Rather than building an array of high speed chips around an ASIC to deliver 7Gbps+ per pin over a 256/384/512-bit memory bus, HBM at its most basic level involves turning memory clockspeeds way down – to just 1Gbps per pin – but in exchange making the memory bus much wider. How wide? That depends on the implementation and generation of the specification, but the examples AMD has been showcasing so far have involved 4 HBM devices (stacks), each featuring a 1024-bit wide memory bus, combining for a massive 4096-bit memory bus. It may not be clocked high, but when it’s that wide, it doesn’t need to be.

Of course while extra memory bandwidth is nice, the far more interesting part is how HBM delivers this. Although the idea of a wide, slow parallel bus is easy enough to comprehend on paper, implementing it is a whole other matter. A 4096-bit memory bus involves thousands of traces, far more than GDDR5, all of which must be carefully constructed in order to make HBM work. As a result there are a couple of fundamental technologies that are seeing their big (though not necessarily initial) introduction with HBM.
The first and most fundamental matter is how do you efficiently route a 4096-bit memory bus? Even the best surface mounting BGA technologies have their limits, and as it is Hawaii was pushing things with its 512-bit GDDR5 memory bus. An even wider bus only makes that harder, inviting issues both with the routing such a wide bus on a PCB or chip substrate, and in using BGA to connect a chip to those traces.
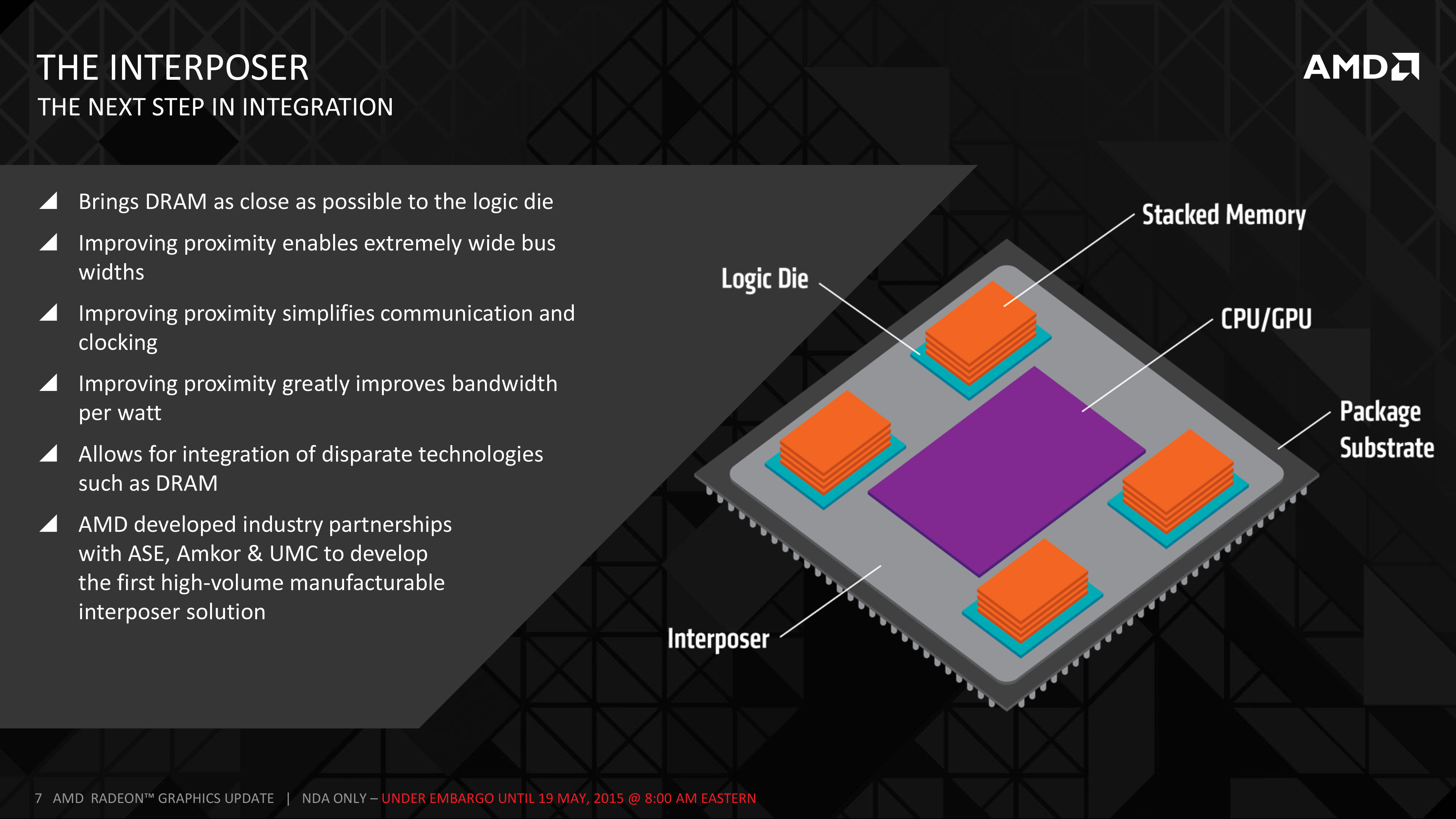
First part of the solution to that in turn was to develop something capable of greater density routing, and that something was the silicon interposer. The interposer in its broadest terms is a partially fabbed silicon chip that instead of being developed into a full ASIC packed with logic, is only developed as far as having metal layers, in order to route signals and power among devices. The interposer in turn works because it exploits some of the core advantages of modern photolithographic processes, allowing for very fine paths to be created that would otherwise not be possible/practical on traditional PCBs and substrates.
Using a silicon interposer solves some of the fundamental problems with HBM, but it also provides some ancillary benefits as well. Along with solving the obvious routing issue, the interposer allows for DRAM to be placed very close to an ASIC, but without being placed on top of it (ala Package-on-package), which is impractical for high TDP devices like GPUs. By being able to place DRAM so close to the ASIC, it avoids the drawbacks of long memory paths, making the shorter paths both simpler to construct and require less power in the process. It also benefits integration, as similar to PoP technology, you can have more of the device’s functionality located on the same package as the ASIC, reducing the number of devices that need to be placed off-package and routed to the ASIC.
Of course the interposer does come with a drawback as well, and that’s cost. While AMD is not talking about costs in great detail – this is a technology deep dive, not an analyst meeting – the fact that the interposer is essentially a very large, partially developed silicon chip means that it’s relatively expensive to produce, especially compared to the very low costs of PCBs and traditional substrates. Mitigating this is the fact that interposers don’t need to go through the most complex and expensive phases of photolithography – the actual front-end lithography – so the cost is only the silicon wafer itself, along with the work required to create the metal layers, with the final interposer only being some 100 microns thick. Furthermore this doesn’t require cutting-edge fabs – old, fully amortized 65nm equipment works quite well – which further keeps the costs down. The end result is that the interposer is still a significant cost, but it is not as bad as it initially seems. This ultimately is why HBM will first be introduced on high margin products like high-end video cards before potentially making its way down to cheaper devices like APUs.
Meanwhile AMD and their vendors will over the long run also benefit from volume production. The first interposers are being produced on retooled 65nm lithographic lines, however once volume production scales up, it will become economical to develop interposer-only lines that are cheaper to operate since they don’t need the ability to offer full lithography as well. Where that cut-off will be is not quite clear at this time, though it sounds like it will happen sooner than later.
Looking at the broader picture, in the grand scheme of things the interposer becomes a new layer on a complete chip, sitting between the traditional substrate and any DRAM/ASICs mounted on top of it. Microbumps will connect the DRAM and ASICs to the interposer, and the interposer will then be connected to the substrate, before finally the substrate is connected to its partner PCB. PCB mounting itself will become a bit easier in the process, as there’s no longer a need to route memory traces through the substrate, which means the only remaining connections are data (PCIe bus, etc) and power for the ASIC and DRAM. All the complex routing is essentially localized to occurring at the interposer layer.

Moving on, the other major technological breakthrough here is the creation of through-silicon vias (TSVs). With the interposer to enable the routing of a dense memory bus, the other issue to solve was the creation of dense memory. The solution to this was to stack multiple memory dies together into a single device/stack, in order to create the single 1024-bit stack, and TSVs are in turn what make this possible.
The reason for stacking DRAM is pretty straightforward: it makes production easier by reducing the DRAM to fewer discrete devices, not to mention it saves space. The challenge here is that you can’t have traditional surface mount connections since the DRAM is stacked, and traditional edge connections (as used in PoP) are neither dense enough nor do they scale well to the kind of stacks HBM would require.
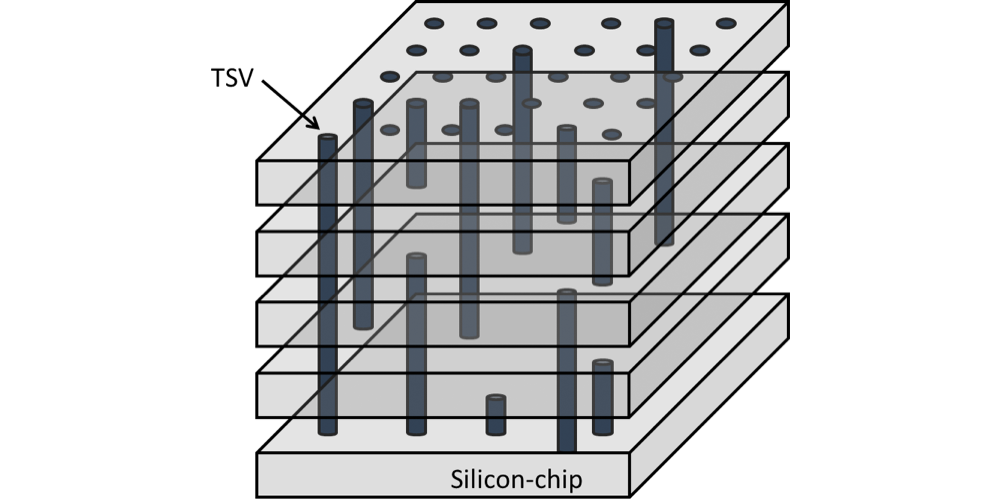
TSVs. Image Courtesy The International Center for Materials Nanoarchitectonics
As a result a means was needed to route DRAM connections though the lower layers of the stack, and this problem was solved with TSVs. Whereas regular vias offer the ability to connect two layers together, TSVs extend this principle by running the vias straight through silicon devices in order to connect layers farther out. The end result is something vaguely akin to DRAM dies surface mounted on top of each other via microbumps, but with the ability to communicate through the layers. From a manufacturing standpoint, between the silicon interposer and TSVs, TSVs are the more difficult technology to master as it essentially combines all the challenges of DRAM fabbing with the challenges of stacking those DRAM dies on top of each other.
Having developed the means to stack DRAM, the final component of an HBM stack is a logic die that lies on the bottom of the stack. Similarly outfitted with TSVs, the logic die is responsible for actually operating the DRAM dies above it, and then handling the operation of the HBM bus between the stack and the ASIC. This actually ends up being a rather interesting development since the net result is more logic added despite the simplicity of the HBM bus, but at the same time thanks to TSVs and the interposer, it’s easier than ever to add that logic.








163 Comments
View All Comments
jardows2 - Tuesday, May 19, 2015 - link
The open-air problem is only a problem if there is a new, smaller form factor for the video cards. OEM partners will likely make oversized heatsinks, or use a custom PCB to support more fans, just as they do now. With the reduced power envelope, I imagine the bulk of the OEM's will use the savings to make more compact designs, rather than use the energy savings to make higher performing designs.xenol - Tuesday, May 19, 2015 - link
I'm a bit skeptical that HBM will dramatically increase the performance the GPU. While it's true that this will help with high resolution rendering, there's also the fact that if the GPU wasn't up to snuff to begin with, it doesn't matter how much memory bandwidth you throw at it. But I'm willing to wait and see when this tech finally shows up at our store shelves before committing to any idea.If anything, I'm only led to believe this will just solve memory bandwidth and power consumption issues for a while.
testbug00 - Tuesday, May 19, 2015 - link
It won't on 28nm. Give you higher core clocks in a TPD, yes. HBM currently shows bandwidth scaling to at least 8TB/s from what I can tell... Which, is over 20 times the Titan X currently. Even if they can "only' hit half of that, it should supply more than enough bandwidth until 5nm process at least.So, at least 10 years, more likely 15-20.
chizow - Tuesday, May 19, 2015 - link
I agree, it is interesting though regardless, as 2.5D stacked RAM is clearly going to be the future of GPU memory, which will in turn drive different form factors, cooling solutions etc.der - Tuesday, May 19, 2015 - link
It'll bring a lot!guskline - Tuesday, May 19, 2015 - link
Great article. Sounds like custom water coolers may be shut out because the OEM cooler will be water cooled and there probably isn't enough improvement going to custom cooling.I'm anxious to see the performance of a single 390x Fiji vs my 2 custom cooled R9 290s in CF.
CaedenV - Tuesday, May 19, 2015 - link
This is fantastic. I mean, we cannot build any wider, so it is neat to see them finding ways to build upwards instead.I would love to see a next gen device that pairs a card like this with HMC. Super fast mixed-use storage/memory combined with super fast GPU memory would make for a truly amazing combination.
Also, I don't see the 4GB limit being a big deal for mainstream high-end cards or laptops. It is only the ultra high-end enthusiast cards that might suffer in sales.
menting - Tuesday, May 19, 2015 - link
Just to be clear..HBM and HMC are not the same (but they are fairly similar in a lot of areas)anubis44 - Tuesday, May 19, 2015 - link
nVidia also simply has fewer good, long-term relationships to exploit than AMD has. The whole semi-conductor industry has been working with AMD for 45 years, whereas nVidia, run by Jen Hsun Huang, a former AMD employee, has only been around for about 15 years.HighTech4US - Tuesday, May 19, 2015 - link
What drugs are you on today?