The Intel Xeon E7-8800 v3 Review: The POWER8 Killer?
by Johan De Gelas on May 8, 2015 8:00 AM EST- Posted in
- CPUs
- IT Computing
- Intel
- Xeon
- Haswell
- Enterprise
- server
- Enterprise CPUs
- POWER
- POWER8
HPC: OpenFoam
Computational Fluid Dynamics is a very important part of the HPC world. Several readers told us that we should look into OpenFoam, and my lab was able to work with the professionals of Actiflow. Actiflow specializes in combining aerodynamics and product design. Calculating aerodynamics involves the use of CFD software, and Actiflow uses OpenFoam to accomplish this. To give you an idea what these skilled engineers can do, they worked with Ferrari to improve the underbody airflow of the Ferrari 599 and increase its downforce.
We were allowed to use one of their test cases as a benchmark, but we are not allowed to discuss the specific solver. All tests were done on OpenFoam 2.2.1 and openmpi-1.6.3.
Many CFD calculations do not scale well on clusters, that is unless you use InfiniBand. InfiniBand switches are quite expensive and even then there are limits to scaling. We do not have an InfiniBand switch in the lab, unfortunately. Although it's not as low latency as InfiniBand, we do have a good 10G Ethernet infrastructure, which performs rather well. So we can compare our newest Xeon server with a basic cluster.
We also found AVX code inside OpenFoam 2.2.1, so we assume that this is one of the cases where AVX improves FP performance.
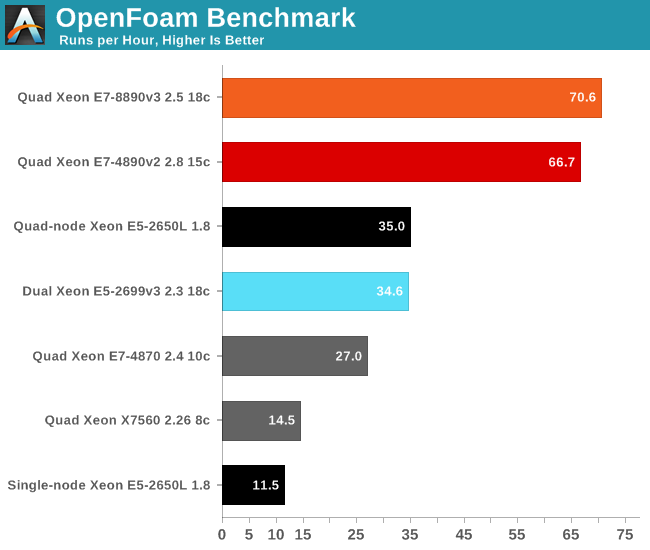
Unless you recompile and tune your code for AVX2, the new Xeon E7 v3 is hardly faster than the previous one. The reason may be that the new Xeon can sometimes go as low as 2.1 GHz running AVX code due to the immense power load AVX2 workloads can cause, while the older E7 v2 is capable of sustaining 2.8 GHz.








146 Comments
View All Comments
PowerTrumps - Saturday, May 9, 2015 - link
I'm sure the author will update the article unless this was a Intel cheerleading piece.name99 - Friday, May 8, 2015 - link
The thing is called E7-8890. Not E7-5890?WTF Intel? Is your marketing team populated by utter idiots? Exactly what value is there in not following the same damn numbering scheme that your product line has followed for the past eight years or so?
Something like that makes the chip look like there's a whole lot of "but this one goes up to 11" thinking going on at Intel...
name99 - Friday, May 8, 2015 - link
OK, I get it. The first number indicates the number of glueless chips, not the micro-architecture generation. Instead we do that (apparently) with a v2 or v3 suffix.I still claim this is totally idiotic. Far more sensible would be to use the same scheme as the other Intel processors, and use a suffix like S2, S4, S8 to show the glueless SMP capabilities.
ZeDestructor - Friday, May 8, 2015 - link
They've been using this convention since Westmere-EX actually, at which point they ditched their old convention of a prefix letter for power tier, followed by one digit for performance/scalability tier, followed by another digit for generation then the rest for individual models. Now we have 2xxx for dual socket, 4xxx for quad socket and 8xxx for 8+ sockets, and E3/E5/E7 for the scalability tier. I'm fine with either, though I have a slight preference for the current naming scheme because the generation is no longer mixed into the main model number.Morawka - Saturday, May 9, 2015 - link
man the power 8 is a beefy cpu... all that cache, you'd think it would walk all over intel.. but intel's superior cpu design winsPowerTrumps - Saturday, May 9, 2015 - link
please explaintsk2k - Saturday, May 9, 2015 - link
Where are the gaming benchmarks?JohanAnandtech - Saturday, May 9, 2015 - link
Is there still a game with software rendering? :-)Gigaplex - Sunday, May 10, 2015 - link
Llvmpipe on Linux gives a capable (feature wise) OpenGL implementation on the CPU.Klimax - Saturday, May 9, 2015 - link
Don't see POWER getting anywhere with that kind of TDP. There will be dearth of datacenters and other hosting locations retooling for such thing. And I suspect not many will even then take it as cooling and power costs will be damn too high.Problem is, IBM can't go lower with TDP as architecture features enabling such performance are directly responsible for such TDP. (Just L1 consumes 2W to keep few cycles latency at high frequency)