The Intel Xeon D Review: Performance Per Watt Server SoC Champion?
by Johan De Gelas on June 23, 2015 8:35 AM EST- Posted in
- CPUs
- Intel
- Xeon-D
- Broadwell-DE
Single-Threaded Integer Performance
The LZMA compression benchmark only measures a part of the performance of some real-world server applications (file server, backup, etc.). The reason why we keep using this benchmark is that it allows us to isolate the "hard to extract instruction level parallelism (ILP)" and "sensitive to memory parallelism and latency" integer performance. That is the kind of integer performance you need in most server applications.
One more reason to test performance in this manner is that the 7-zip source code is available under the GNU LGPL license. That allows us to recompile the source code on every machine with the -O2 optimization with gcc 4.8.2.
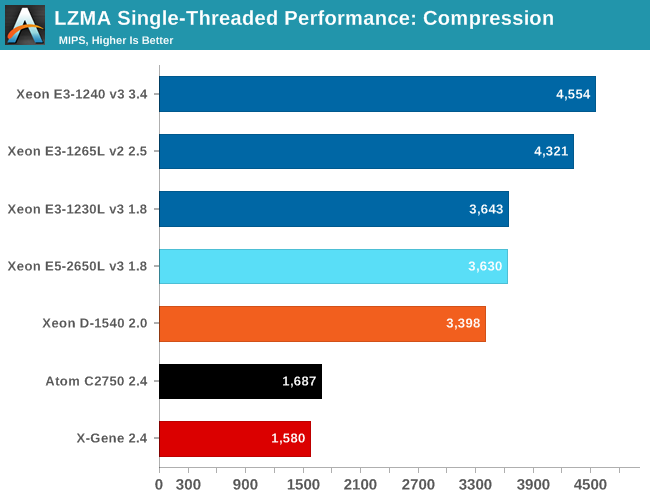
The Xeon E5-2650L Haswell core is only able to boost to 2.5 GHz, while the Xeon D has a newer core (Broadwell) and is capable of 2.6 GHz. Still, the Xeon E5 is 6% faster. The most likely explanation is that the Xeon E5-2650L (65W TDP) keeps turboboost higher for a longer time than the Xeon D (45W TDP).
The Xeon D and Atom C2750 run at the same clockspeed in this single threaded task (2.6 GHz), but you can see how much difference a wide complex architecture makes. The Broadwell Core is able to run about twice as many instructions in parallel as the Silvermont core. The Haswell/Broadwell core results clearly show that well designed wide architectures remain quite capable, even in "low ILP" (Instruction Level Parallelism) code.
Let's see how the chips compare in decompression. Decompression is an even lower IPC (Instructions Per Clock) workload, as it is pretty branch intensive and depends on the latencies of the multiply and shift instructions.
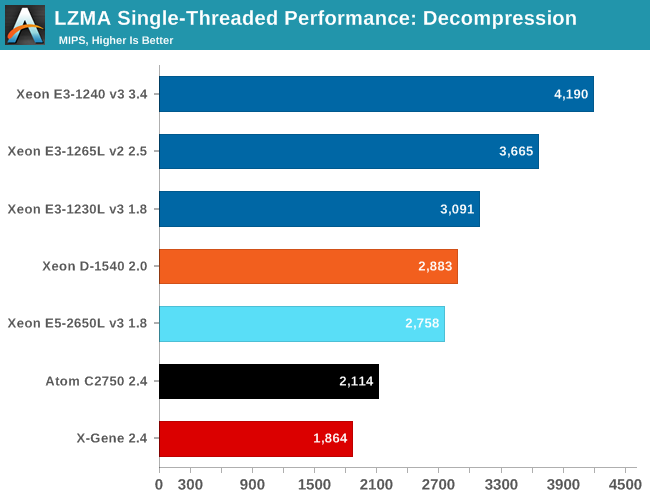
The Xeon E5 runs at 2.5 GHz, the Xeon D at 2.6 GHz, the Xeon E3-1230L at 2.8 GHz, The Xeon E3-1265L can reach 3.7 GHz. The decompression results follow the same logic. There does not seem to be a difference between a Broadwell, Haswell or Ivy Bridge core: performance is almost linear with (turboboost) clockspeed. The only exception is the Xeon E3-1240 which turboboost to 3.8 GHz, but outperforms the other by a larger than expected. The explanation is pretty simple: the higher TDP (80 W) allows the chip to sustain turbo boost clock speeds for much longer.








90 Comments
View All Comments
JohanAnandtech - Wednesday, June 24, 2015 - link
Hi Patrick, the base clock of our chip is 2 GHz, not 1.9 GHz as the one pre-production version that we got from Intel. I have to check the turboclocks though, but I do believe we have measured 2.6 GHz. I'll doublecheck.pjkenned - Wednesday, June 24, 2015 - link
Awesome! Our ES ones were 1.9GHz.Chrisrodinis1 - Tuesday, June 23, 2015 - link
For comparison, this server uses Xeon's. It is the HP Proliant BL460c G9 blade server: https://www.youtube.com/watch?v=0s_w8JVmvf0MrDiSante - Wednesday, June 24, 2015 - link
Why use only -O2 when compiling the benchmarks? I would imagine that in order to squeeze out every last bit of performance, all production software is compiled with all optimizations turned up to 11. I noticed that their github uses -O2 as an example - is it that TinyMemBenchmark just doesn't play nice with -O3?JohanAnandtech - Wednesday, June 24, 2015 - link
The standard makefile had no optimization whatsoever. If you want to measure latency, you do not want maximum performance but rather accuracy, so I played it safe and used -O2. I am not convinced that all production software is optimized with all optimization turned on.diediealldie - Wednesday, June 24, 2015 - link
Intel seems disARMing them... X-Gene 2 doesn't look so promising, as they'll have to fight mighty Skylake-based Xeons, not Broadwell ones.Thanks for great article again.
jfallen - Wednesday, June 24, 2015 - link
Thanks Johan for the great article. I'm a tech enthusiast, and will never buy or use one of these. But it makes great reading and I appreciate the time you take to research and write the article.Regards
Jordan
JohanAnandtech - Wednesday, June 24, 2015 - link
Happy to read this! :-)TomWomack - Wednesday, June 24, 2015 - link
This looks very much consistent with my experience; the disconcertingly high idle power (I looked at the board with a thermal camera; the hot chips were the gigabit PHY, the inductors for the power supply, and the AST2400 management chip), the surprisingly good memory performance, the fairly hot SoC (running sixteen threads of number-crunching I get a power draw of 83W at the plug) and the generally pretty good computation.I'm not entirely sure it was a better buy for my use case than a significantly cheaper 6-core Haswell E - Haswell E is not that hot, electricity not that expensive, and from my supplier the X10SDV-F board and memory were £929 whilst Scan get me an i7-5820K board, CPU and memory for £702. And four-channel DDR4 probably is usefully faster than two-channel for what I do.
I quite strongly don't believe in server mystique - the outbuilding is big enough that I run out of power before I run out of space for micro-ATX cases, and I am lucky enough to be doing calculations which are self-checking to the point that ECC is a waste of money.
JohanAnandtech - Wednesday, June 24, 2015 - link
Hi Tom, I believe we saw up to 90 Watt at the wall when running OpenFOAM (10 Gbit enabled). It is however less relevant for such a chip which is not meant to be a HPC chip as we have shown in the article. HPC really screams for an E5.