The Intel Xeon D Review: Performance Per Watt Server SoC Champion?
by Johan De Gelas on June 23, 2015 8:35 AM EST- Posted in
- CPUs
- Intel
- Xeon-D
- Broadwell-DE
Memory Subsystem: Latency
To measure latency, we use the open source TinyMemBench benchmark. The source was compiled for x86 with gcc 4.8.2 and optimization was set to "-O2". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests. To keep the graph readable we limited ourselves to the CPUs that were different.
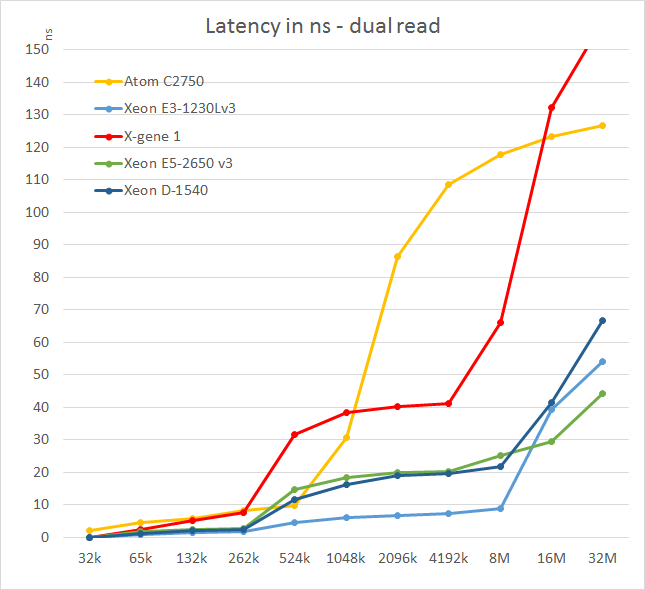
L3 caches have increased significantly the past years, but it is not all good news. The L3 cache of the Xeon E3 responds very quickly (about 10 ns or less than 30 cycles at 2.8 GHz) while the L3-cache of the new generation needs almost twice as much time to respond (about 20 ns or 50 cycles at 2.6 GHz). Larger L3 caches are not always a blessing and can result in a hit to latency - there are applications that have a relatively small part of cacheable data/instructions such as search engines and HPC application that work on huge amounts of data.
It gets worse for the "large L3 cache" models when we look at latency of accessing memory (measured at 64 MB):
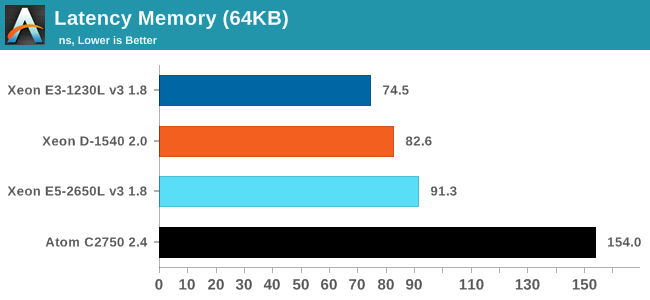
The higher L3-cache latency makes memory accesses more costly in terms of latency for the Xeon E5. Despite having access to DDR4-2133 DIMMs, the Xeon E5-2650L accesses memory slower than the Xeon E3-1230L. It is also a major weakness of the Atom C2750 which has much less sophisticated memory controller/prefetching.








90 Comments
View All Comments
AkulaClass - Tuesday, June 23, 2015 - link
Nice stuff. Realy good to see them bringing power consumption down pr. Performance.WorldWithoutMadness - Tuesday, June 23, 2015 - link
Nice way to confuse people. Codename Yosemiteretrospooty - Tuesday, June 23, 2015 - link
Who would this confuse? Apple fans because of the OS witht he same codename?LOL. Believe me they don't know, or care... Most of them aren't even aware of what a "server" chip is, or even what a "server" is used for.
IanHagen - Tuesday, June 23, 2015 - link
Rails developer checking in to remind you that a great chunk of the Rails community develop using OS X to deploy on Linux and hence is aware of "server chips". Even though you said that "most" Apple users don't know what a server chip is and that's accurate, the same could be said about Windows or even Linux common users. Stop patronizing.All being said, I agree with you. Who could possibly confound the Xeon D's codename coincides with OS X's 10.10 name?
WinterCharm - Tuesday, June 23, 2015 - link
First of all, your implication that apple fans don't know jack shit about servers is a broad generalization, and a stupid one at that.Second of all, anyone who knows enough to even consider buying a Xeon and a motherboard that supports it and the ECC memory, probably knows enough to not get confused. And plenty of mac users know what server chips are and what they're used for.
Nice trolling though.
adithyay328 - Tuesday, August 25, 2015 - link
That's not entirely true, but I will agree that people a lot of the people who use Apples( No discrimination intended) only continue to use Apple due to their lack of tech knowledge( like knowing Android is the king :) . And, yes, they probably won;t know what servers even are.jeffsci - Monday, June 29, 2015 - link
Geographic code names are the norm in the computing industry (I think because they cannot be copyrighted) and they end up being reused. For example, Intel Seattle is/was a motherboard and AMD Seattle is/was an ARM64 processor. See https://en.wikipedia.org/wiki/List_of_Intel_codena... https://en.wikipedia.org/wiki/List_of_Microsoft_co... etc. if you would like to look for more examples :-)RaiderJ - Tuesday, June 23, 2015 - link
Any places in the US that the motherboard is available for purchase? Quick checks looks like it's mostly sold out or otherwise unavailable?ats - Tuesday, June 23, 2015 - link
Availability comes and goes. Xeon D has been a big hit in the large scale deployment markets and they've been soaking up a lot of demand for it, both bare and combined on motherboards like the supermicro offerings severely limiting retail availability. But it is available in retail but quantities are limited. Quite a number of people over at servethehome have gotten their hands on them. If you want one, you'll likely have to keep checking the major sites like newegg, amazon, et al for them to come back in stock. Retail boards are generally in the $800-1000 range atm (basically going for full list but then again bare motherboards with 10gbe tend to go for 600+ so its still a good buy and simple new 10gbe cards tend to go for $300-500).ToTTenTranz - Tuesday, June 23, 2015 - link
How come they call this a SoC if there's no integrated module to drive even a simple display, and they apparently need a discrete PCIe graphics card for that D-SUB output?