The NVIDIA GeForce GTX Titan X Review
by Ryan Smith on March 17, 2015 3:00 PM ESTCompute
Shifting gears, we have our look at compute performance.
As we outlined earlier, GTX Titan X is not the same kind of compute powerhouse that the original GTX Titan was. Make no mistake, at single precision (FP32) compute tasks it is still a very potent card, which for consumer level workloads is generally all that will matter. But for pro-level double precision (FP64) workloads the new Titan lacks the high FP64 performance of the old one.
Starting us off for our look at compute is LuxMark3.0, the latest version of the official benchmark of LuxRender 2.0. LuxRender’s GPU-accelerated rendering mode is an OpenCL based ray tracer that forms a part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.
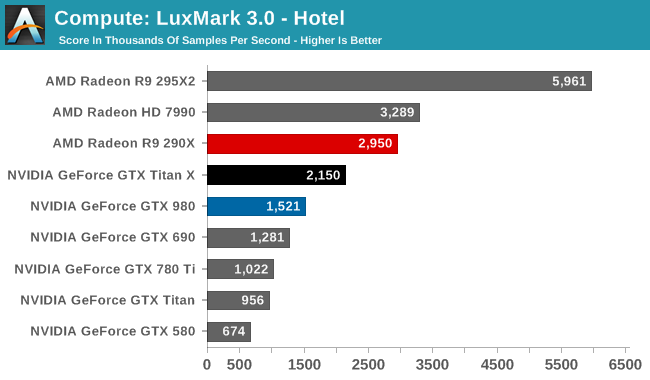
While in LuxMark 2.0 AMD and NVIDIA were fairly close post-Maxwell, the recently released LuxMark 3.0 finds NVIDIA trailing AMD once more. While GTX Titan X sees a better than average 41% performance increase over the GTX 980 (owing to its ability to stay at its max boost clock on this benchmark) it’s not enough to dethrone the Radeon R9 290X. Even though GTX Titan X packs a lot of performance on paper, and can more than deliver it in graphics workloads, as we can see compute workloads are still highly variable.
For our second set of compute benchmarks we have CompuBench 1.5, the successor to CLBenchmark. CompuBench offers a wide array of different practical compute workloads, and we’ve decided to focus on face detection, optical flow modeling, and particle simulations.
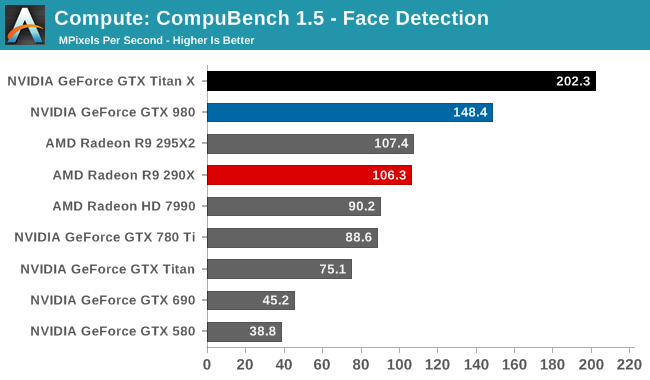
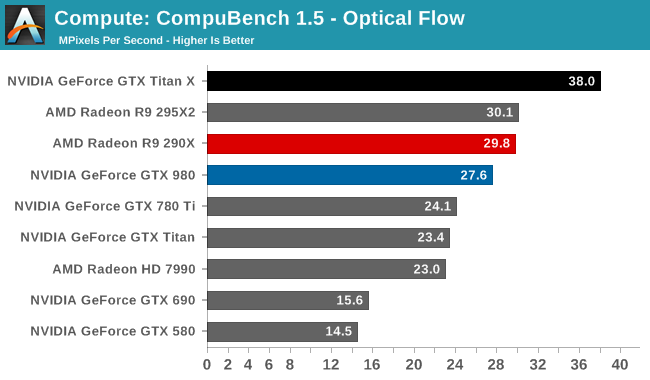
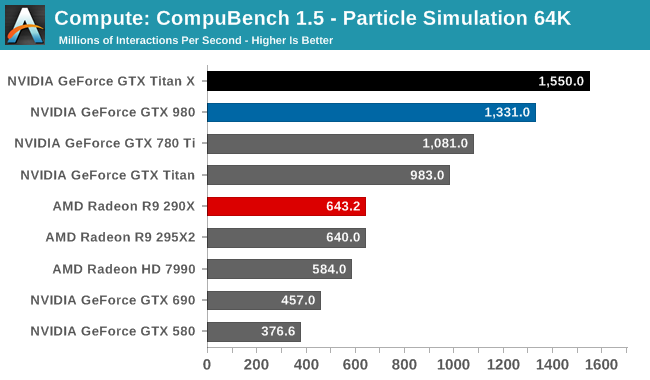
Although GTX Titan X struggled at LuxMark, the same cannot be said for CompuBench. Though the lead varies with the specific sub-benchmark, in every case the latest Titan comes out on top. Face detection in particular shows some massive gains, with GTX Titan X more than doubling the GK110 based GTX 780 Ti's performance.
Our 3rd compute benchmark is Sony Vegas Pro 13, an OpenGL and OpenCL video editing and authoring package. Vegas can use GPUs in a few different ways, the primary uses being to accelerate the video effects and compositing process itself, and in the video encoding step. With video encoding being increasingly offloaded to dedicated DSPs these days we’re focusing on the editing and compositing process, rendering to a low CPU overhead format (XDCAM EX). This specific test comes from Sony, and measures how long it takes to render a video.
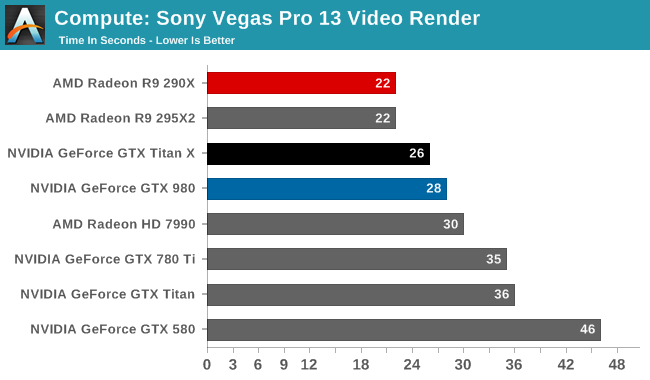
Traditionally a benchmark that favors AMD, GTX Titan X closes the gap some. But it's still not enough to surpass the R9 290X.
Moving on, our 4th compute benchmark is FAHBench, the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, with single precision being the most useful metric for most consumer cards due to their low double precision performance. Each precision has two modes, explicit and implicit, the difference being whether water atoms are included in the simulation, which adds quite a bit of work and overhead. This is another OpenCL test, utilizing the OpenCL path for FAHCore 17.
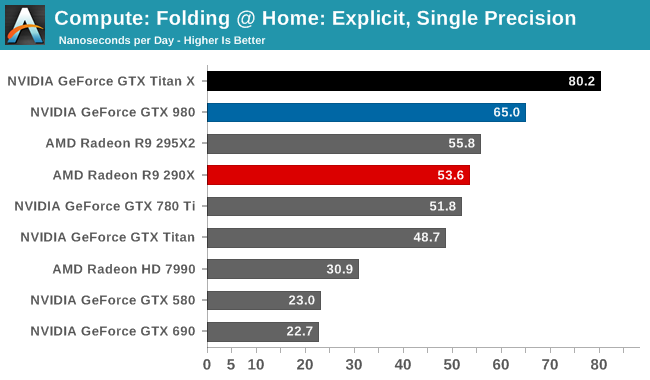
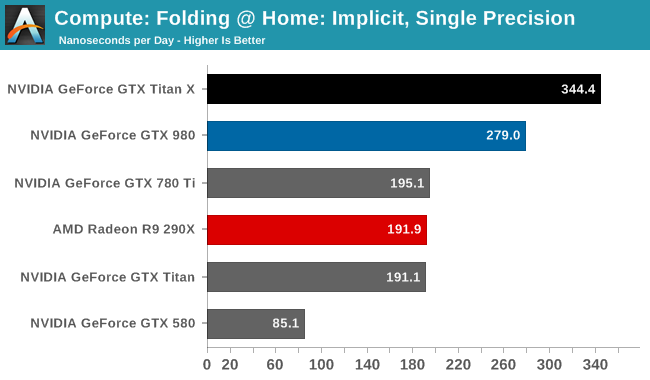
Folding @ Home’s single precision tests reiterate just how powerful GTX Titan X can be at FP32 workloads, even if it’s ostensibly a graphics GPU. With a 50-75% lead over the GTX 780 Ti, the GTX Titan X showcases some of the remarkable efficiency improvements that the Maxwell GPU architecture can offer in compute scenarios, and in the process shoots well past the AMD Radeon cards.
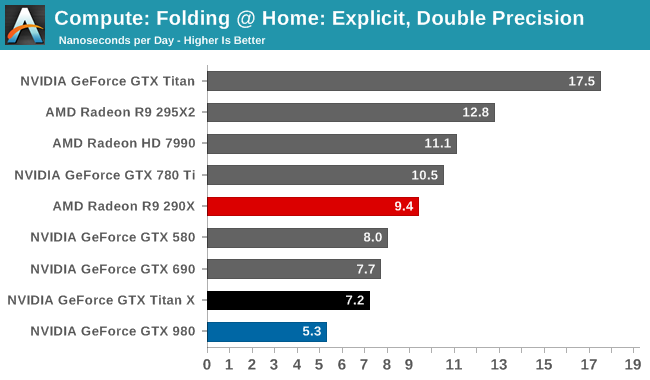
On the other hand with a native FP64 rate of 1/32, the GTX Titan X flounders at double precision. There is no better example of just how much the GTX Titan X and the original GTX Titan differ in their FP64 capabilities than this graph; the GTX Titan X can’t beat the GTX 580, never mind the chart-topping original GTX Titan. FP64 users looking for an entry level FP64 card would be well advised to stick with the GTX Titan Black for now. The new Titan is not the prosumer compute card that was the old Titan.
Wrapping things up, our final compute benchmark is an in-house project developed by our very own Dr. Ian Cutress. SystemCompute is our first C++ AMP benchmark, utilizing Microsoft’s simple C++ extensions to allow the easy use of GPU computing in C++ programs. SystemCompute in turn is a collection of benchmarks for several different fundamental compute algorithms, with the final score represented in points. DirectCompute is the compute backend for C++ AMP on Windows, so this forms our other DirectCompute test.
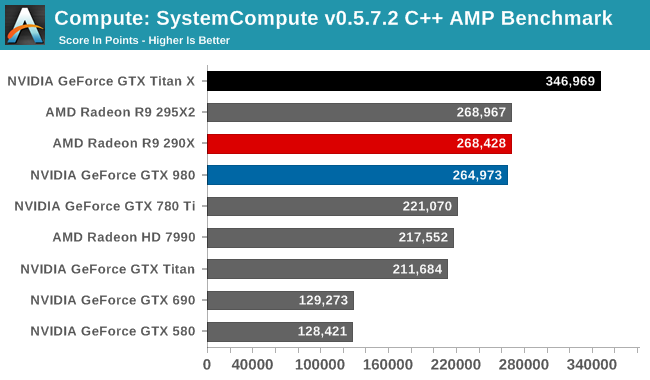
With the GTX 980 already performing well here, the GTX Titan X takes it home, improving on the GTX 980 by 31%. Whereas GTX 980 could only hold even with the Radeon R9 290X, the GTX Titan X takes a clear lead.
Overall then the new GTX Titan X can still be a force to be reckoned with in compute scenarios, but only when the workloads are FP32. Users accustomed to the original GTX Titan’s FP64 performance on the other hand will find that this is a very different card, one that doesn’t live up to the same standards.








276 Comments
View All Comments
Kevin G - Tuesday, March 17, 2015 - link
Last I checked, rectal limits are a bit north of 700 mm^2. However, nVidia is already in the crazy realm in terms of economics when it comes to supply/demand/yields/cost. Getting fully functional chips with die sizes over 600 mm^2 isn't easy. Then again, it isn't easy putting down $999 USD for a graphics card.However, harvested parts should be quiet plentiful and the retail price of such a card should be appropriately lower.
Michael Bay - Wednesday, March 18, 2015 - link
>rectal limits are a bit north of 700 mm^2Oh wow.
Kevin G - Wednesday, March 18, 2015 - link
@Michael BayIntel's limit is supposed to be between 750 and 800 mm^2. They have released a 699 mm^2 product commercially (Tukwilla Itanium 2) a few years ago so it can be done.
Michael Bay - Wednesday, March 18, 2015 - link
>rectal limitsD. Lister - Wednesday, March 18, 2015 - link
lolchizow - Tuesday, March 17, 2015 - link
Yes its clear Nvidia had to make sacrifices somewhere to maintain advancements on 28nm and it looks like FP64/DP got the cut. I'm fine with it though, at least on GeForce products I don't want to pay a penny more for non-gaming products, if someone wants dedicated compute, go Tesla/Quadro.Yojimbo - Tuesday, March 17, 2015 - link
Kepler also has dedicated FP64 cores and from what I see in Anandtech articles, those cores are not used for FP32 calculations. How does NVIDIA save power with Maxwell by leaving FP64 cores off the die? The Maxwell GPUs seem to still be FP64 capable with respect to the number of FP64 cores placed on the die. It seems what they save by having less FP64 cores is die space and, as a result, the ability to have more FP32 cores. In other words, I haven't seen any information about Maxwell that leads me to believe they couldn't have added more FP64 cores when designing GM200 to make a GPU with superior double precision performance and inferior single precision performance compared with the configuration they actually chose for GM200. Maybe they just judged single precision performance to be more important to focus on than double precision, with a performance boost for double precision users having to wait until Pascal is released. Perhaps it was a choice between making a modest performance boost for both single and double precision calculations or making a significant performance boost for single precision calculations by forgoing double precision. Maybe they thought the efficiency gain of Maxwell could not carry sales on its own.testbug00 - Tuesday, March 17, 2015 - link
If this is a 250W card using about the same power as the 290x under gaming load, what does that make the 290x?Creig - Tuesday, March 17, 2015 - link
A very good value for the money.shing3232 - Tuesday, March 17, 2015 - link
Agree.