The NVIDIA GeForce GTX Titan X Review
by Ryan Smith on March 17, 2015 3:00 PM ESTGM200 - All Graphics, Hold The Double Precision
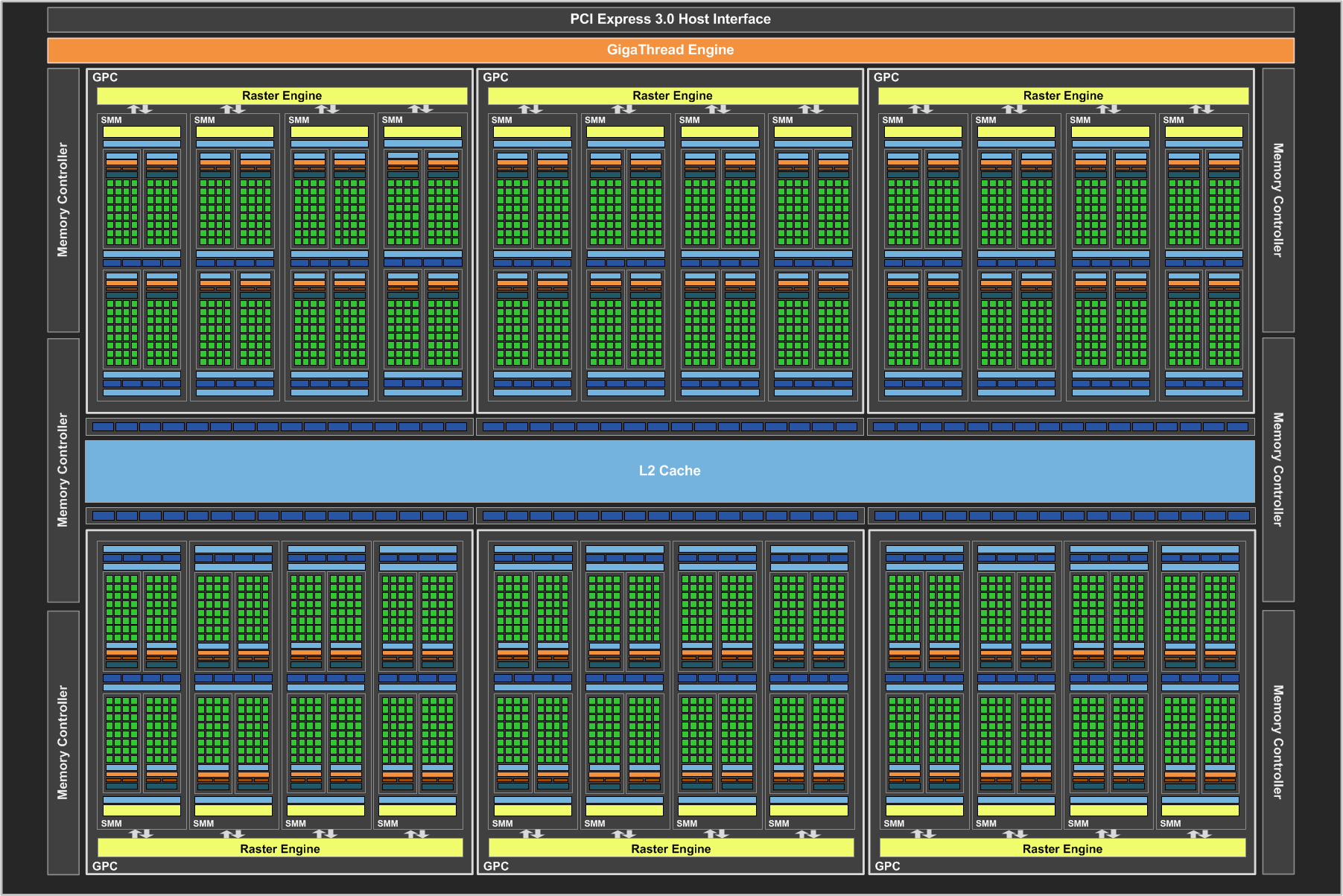
Before diving into our look at the GTX Titan X itself, I want to spend a bit of time talking about the GM200 GPU. GM200 is a very interesting GPU, and not for the usual reasons. In fact you could say that GM200 is remarkable for just how unremarkable it is.

From a semiconductor manufacturing standpoint we’re still at a standstill on 28nm for at least a little bit longer, pushing 28nm into its 4th year and having all sorts of knock-on effects. We’ve droned on about this for some time now, so we won’t repeat ourselves, but ultimately what it means for consumers is that AMD and NVIDIA have needed to make do with the tools they have, and in lieu of generational jumps in manufacturing have focused on architectural efficiency and wringing out everything they can get out of 28nm.
For NVIDIA those improvements came in the form of the company’s Maxwell architecture, which has made a concentrated effort to focus on energy and architectural efficiency to get the most out of their technology. In assembling GM204 NVIDIA built the true successor to GK104, putting together a pure graphics chip. From a design standpoint NVIDIA spent their energy efficiency gains on growing out GM204’s die size without increasing power, allowing them to go from 294mm2 and 3.5B transistors to 398mm2 and 5.2B transistors. With a larger die and larger transistor budget, NVIDIA was able to greatly increase performance by laying down a larger number of high performance (and relatively larger themselves) Maxwell SMMs.
On the other hand for GM206 and the GTX 960, NVIDIA banked the bulk of their energy savings, building what’s best described as half of a GM204 and leading to a GPU that didn’t offer as huge of a jump in performance from its predecessor (GK106) but also brought power usage down and kept costs in check.
Not Pictured: The 96 FP64 ALUs
But for Big Maxwell, neither option was open to NVIDIA. At 551mm2 GK110 was already a big GPU, so large (33%) increase in die size like with GM204 was not practical. Neither was leaving the die size at roughly the same area and building the Maxwell version of GK110, gaining only limited performance in the process. Instead NVIDIA has taken a 3rd option, and this is what makes GM200 so interesting.
For GM200 NVIDIA’s path of choice has been to divorce graphics from high performance FP64 compute. Big Kepler was a graphics powerhouse in its own right, but it also spent quite a bit of die area on FP64 CUDA cores and some other compute-centric functionality. This allowed NVIDIA to use a single GPU across the entire spectrum – GeForce, Quadro, and Tesla – but it also meant that GK110 was a bit jack-of-all-trades. Consequently when faced with another round of 28nm chips and intent on spending their Maxwell power savings on more graphics resources (ala GM204), NVIDIA built a big graphics GPU. Big Maxwell is not the successor to Big Kepler, but rather it’s a really (really) big version of GM204.
GM200 is 601mm2 of graphics, and this is what makes it remarkable. There are no special compute features here that only Tesla and Quadro users will tap into (save perhaps ECC), rather it really is GM204 with 50% more GPU. This means we’re looking at the same SMMs as on GM204, featuring 128 FP32 CUDA cores per SMM, a 512Kbit register file, and just 4 FP64 ALUs per SMM, leading to a puny native FP64 rate of just 1/32. As a result, all of that space in GK110 occupied by FP64 ALUs and other compute hardware – and NVIDIA won’t reveal quite how much space that was – has been reinvested in FP32 ALUs and other graphics-centric hardware.
| NVIDIA Big GPUs | ||||
| Die Size | Native FP64 Rate | |||
| GM200 (Big Maxwell) | 601mm2 | 1/32 | ||
| GK110 (Big Kepler) | 551mm2 | 1/3 | ||
| GF110 (Big Fermi) | 520mm2 | 1/2 | ||
| GT200 (Big Tesla) | 576mm2 | 1/8 | ||
| G80 | 484mm2 | N/A | ||
It’s this graphics “purification” that has enabled NVIDIA to improve their performance over GK110 by 50% without increasing power consumption and with only a moderate 50mm2 (9%) increase in die size. In fact in putting together GM200, NVIDIA has done something they haven’t done for years. The last flagship GPU from the company to dedicate this little space to FP64 was G80 – heart of the GeForce 8800GTX – which in fact didn’t have any FP64 hardware at all. In other words this is the “purest” flagship graphics GPU in 9 years.
Now to be clear here, when we say GM200 favors graphics we don’t mean exclusively, but rather it favors graphics and its associated FP32 math over FP64 math. GM200 is still a FP32 compute powerhouse, unlike anything else in NVIDIA’s lineup, and we don’t expect it will be matched by anything else from NVIDIA for quite some time. For that reason I wouldn’t be too surprised if we a Tesla card using it aimed at FP32 users such the oil & gas industry – something NVIDIA has done once before with the Tesla K10 – but you won’t be seeing GM200 in the successor to Tesla K40.
This is also why the GTX Titan X is arguably not a prosumer level card like the original GTX Titan. With the GTX Titan NVIDIA shipped it with its full 1/3 rate FP64 enabled, having GTX Titan pull double duty as the company’s consumer graphics flagship while also serving as their entry-level FP64 card. For GTX Titan X however this is not an option since GM200 is not a high performance FP64 GPU, and as a result the card is riding only on its graphics and FP32 compute capabilities. Which for that matter doesn’t mean that NVIDIA won’t also try to pitch it as a high-performance FP32 card for users who don’t need Tesla, but it won’t be the same kind of entry-level compute card like the original GTX Titan was. In other words, GTX Titan X is much more consumer focused than the original GTX Titan.

Tesla K80: The Only GK210 Card
Looking at the broader picture, I’m left to wonder if this is the start of a permanent divorce between graphics/FP32 compute and FP64 compute in the NVIDIA ecosystem. Until recently, NVIDIA has always piggybacked compute on their flagship GPUs as a means of bootstrapping the launch of the Tesla division. By putting compute in their flagship GPU, even if NVIDIA couldn’t sell those GPUs to compute customers they could sell them to GeForce/Quadro graphics customers. This limited the amount of total risk the company faced, as they’d never end up with a bunch of compute GPUs they could never sell.
However in the last 6 months we’ve seen a shift from NVIDIA at both ends of the spectrum. In November we saw the launch of a Tesla K80, a dual-GPU card featuring the GK210 GPU, a reworked version of GK110 that doubled the register file and shared memory sizes for better performance. GK210 would not come to GeForce or Quadro (though in theory it could have), making it the first compute-centric GPU from NVIDIA. And now with the launch of GM200 we have distinct graphics and compute GPUs from NVIDIA.
| NVIDIA GPUs By Compute | |||||
| GM200 | GK210 | GK110B | |||
| Stream Processors | 3072 | 2880 | 2880 | ||
| Memory Bus Width | 384-bit | 384-bit | 384-bit | ||
| Register File Size (Per SM) | 4 x 64KB | 512KB | 256KB | ||
| Shared Memory / L1 Cache (Per SM) |
96KB + 24KB | 128KB | 64KB | ||
| Transistor Count | 8B | 7.1B(?) | 7.1B | ||
| Manufacturing Process | TSMC 28nm | TSMC 28nm | TSMC 28nm | ||
| Architecture | Maxwell | Kepler | Kepler | ||
| Tesla Products | None | K80 | K40 | ||
The remaining question at this point is what happens from here. Was this divorce of compute and graphics a temporary action, the result of being stuck on the 28nm process for another generation? Or was it the first generation in a permanent divorce between graphics and compute, and consequently a divorce between GeForce/Quadro and Tesla? Is NVIDIA finally ready to let Tesla stand on its own?
With Pascal NVIDIA could very well build a jack-of-all-trades style GPU once more. However having already divorced graphics and compute for a generation, merging them again would eat up some of the power and die space benefits from going to 16nm FinFET, power and space that NVIDIA would likely want to invest in greater separate improvements in graphics and compute performance. We’ll see what Pascal brings, but I suspect GM200 is the shape of things to come for GeForce and the GTX Titan lineup.








276 Comments
View All Comments
Denithor - Wednesday, March 18, 2015 - link
Correct, but then they should have priced it around $800, not $1k. The reason they could demand $1k for the original Titan was due to the FP64 compute functionality on board.This is exactly what they did when they made the GTX 560 Ti, chopped out the compute features to maximize gaming power at a low cost. The reason that one was such a great card was due to price positioning, not just performance.
chizow - Monday, March 23, 2015 - link
@Denithor, I disagree, the reason they could charge $1K for the original Titan was because there was still considerable doubt there would ever be a traditionally priced GeForce GTX card based on GK110, the compute aspect was just add-on BS to fluff up the price.Since then of course, they released not 1, but 2 traditional GTX cards (780 and Ti) that were much better received by the gaming market in terms of both price and in the case of the Ti, performance. Most notably was the fact the original Titan price on FS/FT and Ebay markets quickly dropped below that of the 780Ti. If the allure of the Titan was indeed for DP compute, it would have held its price, but the fact Titan owners were dumping their cards for less than what it cost to buy a 780Ti clearly showed the demand and price justification for a Titan for compute alone simply wasn't there. Also, important to note Titan's drivers were still GeForce, so even if it did have better DP performance, there were still a lot of driver limitations related to CUDA preventing it from reaching Quadro/Tesla levels of performance.
Simply put, Nvidia couldn't pull that trick again under the guise of compute this time around, and people like me who weren't willing to pay a penny for compute over gaming weren't willing to justify that price tag for features we had no use for. Titan X on the other hand, its 100% dedicated to gamers, not a single transistor budgeted for something I don't care about, and no false pretenses to go with it.
Samus - Thursday, March 19, 2015 - link
The identity crisis this card has with itself is that for all the effort, it's still slower than two 980's in SLI, and when overclocked to try to catch up to them, ends up using MORE POWER than two 980's in SLI.So for the price (being identical) wouldn't you just pick up two 980's which offer more performance, less power consumption and FP64 (even if you don't need it, it'll help the resell value in the future)?
LukaP - Thursday, March 19, 2015 - link
The 980 have the same 1/32 DP performance as the Titan X. And Titan never was a sensible card. Noone sensible buys it over a x80 of that generation (which i assume will be 1080 or whatever they call it, based on GM200 with less ram, and maybe some disabled ROPs).The Titan is a true flagship. making no sense economically, but increasing your penis size by miles
chizow - Monday, March 23, 2015 - link
I considered going this route but ultimately decided against it despite having used many SLI setups in the past. There's a number of things to like about the 980 but ultimately I felt I didn't want to be hamstrung by the 4GB in the future. There are already a number of games that push right up to that 4GB VRAM usage at 1440p and in the end I was more interested in bringing up min FPS than absolutely maxing out top-end FPS with 980 SLI.Power I would say is about the same, 980 is super efficient but once overclocked, with 2 of them I am sure the 980 set-up would use as much if not more than the single Titan X.
naxeem - Saturday, March 21, 2015 - link
You're forgetting three things:1. NO game uses even close to 8GB, let alone 12
2. $1000/1300€ puts it to exactly double the price of exactly the same performance level you get with any other solution: 970 SLI kicks it with $750, 295x2 does the same, 2x290X also...
In Europe, the card is even 30% more expensive than in US and than other cards so even less people will buy it there.
3. In summer, when AMD releases 390X for $700 and gives even better performance, Nvidia will either have to drop TitanX to the same price or suffer being smashed around at the market.
Keep in mind HBM is seriously a performance kicker for high resolutions, end-game gaming that TitanX is intended for. No amount of RAM can counter RAM bandwidth, especially when you don't really need over 6-7GB for even the most demanding games out there.
ArmedandDangerous - Saturday, March 21, 2015 - link
Or they could just say fuck it and keep the Titan at it's exact price and release a x80 GM200 at a lower price with some features cut that will still compete with whatever AMD has to offer. This is the 3rd Titan, how can you not know this by now.naxeem - Tuesday, March 24, 2015 - link
Well, yes. But without any compute performance of previous Titans, who would any why buy a 1000 Titan X while having exact same performance in some 980Ti or alike?Those who need 12GB for rendering may as well buy Quadros with more VRAM... When you need 12, you need more anyway... For gaming, 12GB means jack sht.
Thetrav55 - Friday, March 20, 2015 - link
Well its only the fastest card in the WORLD look at it that way the fattest card in the world ONLY 1000$ I know I know 1000 does not justify the performance but its the fastest card in the WORLD!!!agentbb007 - Wednesday, June 24, 2015 - link
LOL had to laugh @ farealstarfareal's comment that the 390X would likely blow the doors off the Titan X, the 390X is nowhere near the Titan X, it's closer to a 980. The all mighty R9 FuryX reviews posted this morning and it's not even beating the 980ti.