Intel Releases Broadwell-U: New SKUs, up to 48 EUs and Iris 6100
by Ian Cutress on January 5, 2015 10:00 AM ESTBroadwell GPU Improvements
The new integrated graphics for Broadwell from Intel in the form of HD 5500, HD 6000 and Iris 6100 open up some very important functionality. DirectX 11.2, OpenGL 4.3 and OpenCL 2.0 are big scoring points, especially OpenCL 2.0 when it comes to graphics compute. This includes features such as shared memory coherency between CPU and GPU to allow transfer of pointer-rich memory structures and ultimately the beginnings of heterogeneous CPU + GPU compute.

‘DirectX 12 Ready’ is somewhat of an interesting case, and it depends on Microsoft’s final specifications. At this point in time Intel state that they conform to as much of DirectX 12 feature set that they can get their hands on with their relationship with Microsoft, and barring any major addition or change, should be compatible. UHD-4K is also now supported through the HDMI 1.4b interface, albeit limited to 24 Hz.
Support for HEVC is also present in terms of a combined (hybrid) hardware and software solution, just as it was on Core-M. Intel stated that as parts of the H.264 algorithm are near if not identical to those of the H.265, with a small tweak to the hardware it can be used for both. This is still not an all-encompassing hardware acceleration, but it does aim at some parts of the codec. I would speculate that if a full section of the silicon could be made for complete hardware acceleration, it might eat into certain power budgets.
GPU Slices
Although mentioned in our Broadwell architecture overview, for Broadwell-U we should cover the basics of the GPU layout. Below is an image of a HD 6000 implementation featuring two slices of 24 EUs each, with each slice having three sub-slices of 8 EUs. Each EU can handle 7 threads at once when in a 128xSIMD8 32-bit configuration. When in the right data structure, this offers a good amount of power, especially to coalesced 16-bit computation.
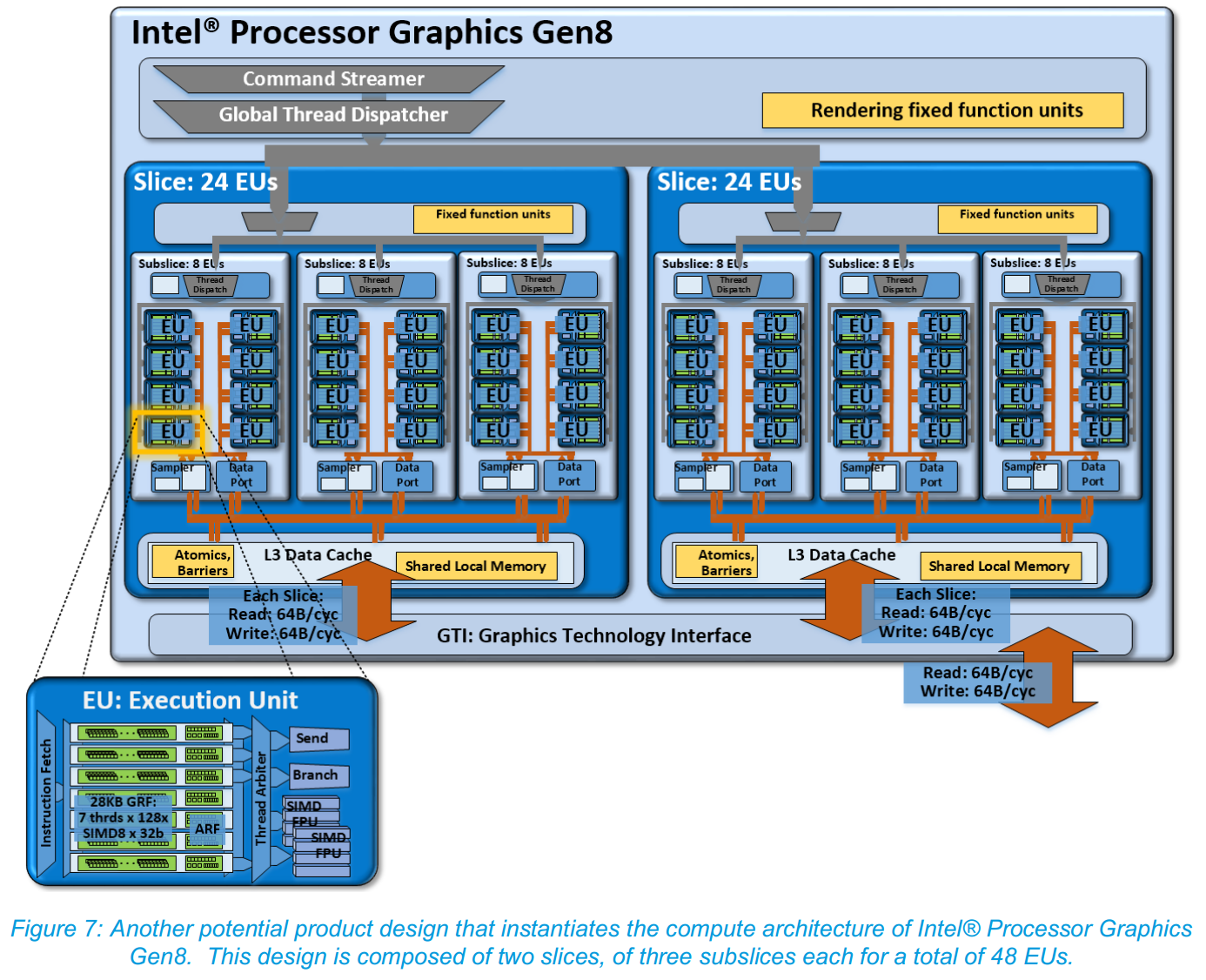
For Broadwell, Intel has reduced the number of EUs in a sub-slice from 10 down to 8. This is a big change, as it eases up the Thread Dispatch, Data Port and L1/L2 samplers in each EU as they have to deal with less data overall. By this logic, with two equivalent designs, one with 8 EUs per sub-slice should be able to get through more data due to less data bandwidth pressure and less competition for each sub-slice’s shared local memory.
Each slice has an L3 Data Cache, which for Gen8 is improved from 384 KB to 576 KB per slice. This ends up being split anyway as 64 KB per sub-slice as shared local memory and 384 KB for inter-slice L3 communication. More slices mean more caching overall, and as an aid to the last level cache outside the GPU, the Graphics Technology Interface has doubled the write bandwidth.

The principle behind caches is to provide a small amount of memory that can be accessed faster at the expense of size. The algorithms in place to predict which data is needed next (or preprogrammed data fetching) helps increase the overall speed of any CPU function, but increasing the size of a cache decreases the need for later caches by reducing the data misses that require trips further out. GPUs are historically bandwidth starved, both for gaming and for compute, so by virtue of having four named caches for the GPU to use and increasing at least the third, this should contribute to the large performance numbers Intel is producing in comparison to the previous generation.
In terms of throughput, Intel gives the following numbers for GT2 / 24 EU configurations:
32b FP: 384 FLOP/cycle = 24 EUs * (2 * SIMD-4 FPU) * (MUL + ADD)
64b DP: 96 FLOP/cycle = 24 EU * SIMD-4 FPU * (MUL + ADD) * 0.5 throughput
32b INT: 192 IOP/cycle = 24 EU * (2 * SIMD-4 FPU) * ADD
The Gen8 EUs will support 16-bit floats (half-floats) natively, as well as 16-bit integers.
We can construct a table calculating out to full performance:
| Intel Gen8 Graphics Throughput | |||
| Processor | 32b FP GFLOPs |
64b DP GFLOPS |
32b INT GFLOPs |
| i7-5557U (48 EUs at 1100 MHz) | 844.8 | 211.2 | 422.4 |
| i5-5257U (48 EUs at 1050 MHz) | 806.4 | 201.6 | 403.2 |
| i3-5157U (48 EUs at 1000 MHz) | 768 | 192 | 384 |
| i7-5250U (48 EUs at 950 MHz) | 729.6 | 182.4 | 364.8 |
| i7-5600U (24 EUs at 950 MHz) | 364.8 | 91.2 | 182.4 |
| i5-5300U (24 EUs a 900 MHz) | 345.6 | 86.4 | 172.8 |
| i3-5010U (23 EUs at 900 MHz) | 331.2 | 82.8 | 165.6 |
| i3-5005U (23 EUs at 850 MHz) | 312.8 | 78.2 | 156.4 |
| Pentium 3805U (12 EUs at 800 MHz) | 153.6 | 38.4 | 76.8 |
Having doubled the EUs not only doubles the performance but the extra bit of frequency also helps.
As we mentioned back in August, the sub-slice also gets some minor improvements to increase pixel and Z-fill rates, and the front end’s geometry units are also beefed up. Further reading can be found on Intel’s PDF on the Gen 8 Graphics Overview from IDF.








85 Comments
View All Comments
kpb321 - Monday, January 5, 2015 - link
We will have to wait and see. There might be more of a performance difference for Haswell than in the past because they decreased the # of EU's per slice from 10 down to 8 and increased the cache size. That should mean a lot more cache available per EU which should help keep it from being as bandwidth limited as in the past. It will probably still be bandwidth limited but hopefully just not as much making the GT3 version without eDRAM more reasonable.With that said integrated GPUs will always be behind dedicated GPUs in performance because graphics is so parallel that is scales easily with more units but those additional units mean higher power and bandwidth requirements. That's why you see high end GPUs using 200+ watts and very wide/fast memory interfaces both of which are much higher than can be reasonable handled in integrated GPU setting.
III-V - Monday, January 5, 2015 - link
Gen8 actually makes a lot of changes that reduce its reliance on external memory. Take a look at the bit on caches in this article. It'll still be constrained by bandwidth, but not as much as you seem to be expecting.texasti89 - Monday, January 5, 2015 - link
It is nice to see audio DSP element is integrated into the PCH. I hope to see more and more integration in the near future. The power charts show clearly that display panel still has the major contribution in the overall platform power consumption. I think Intel and other SoC players have reached the point where SoCs can no longer provide pronounced improvements in overall power saving given demand for higher display resolution. Igzo display technology can cut the display power by at least half which will give further opportunity for SoC designers to effectively improve efficiency.thunderising - Monday, January 5, 2015 - link
So, the fastest Intel Core i7, which costs a lot of $$, and spends nearly 70% of its die space on graphics, produces 844.8 GFlops.Whereas, NVIDIA's Tegra X1 outputs 1024 TFlops.
*Claps*
Pork@III - Monday, January 5, 2015 - link
NVIDIA's Tegra X1 outputs 1024 TFlops>(in FP16)< But we already live in 2015 and work with FP32 and FP64 mostly
TiGr1982 - Monday, January 5, 2015 - link
Talking FP64, Tegra X1 may not even have it at all, or, at best, I suppose, it may have it at the same ratio, as GM204, which is just 1/32. So, I bet, FP64 capability does not really apply seriously to Tegra X1. FP16 and FP32 to be used there.III-V - Monday, January 5, 2015 - link
I'm sure it'll have some FP64 support... Probably at 1/32, 1/48, or 1/64 rate. It'd be ludicrous for it to not support it at all.TiGr1982 - Monday, January 5, 2015 - link
I suppose, FP64 can be at 1/32, like I said, is the case for GM204. But that's not a lot, certainly.TiGr1982 - Monday, January 5, 2015 - link
X1 gives this flops for FP16 (half precision). Don't be fooled by usual nV marketing and compare "apples to apples".However, this is not to say that this Broadwell-U is very impressive. To me, it looks just as one more evolutionary step over Haswell-U. Nothing special, I would say. Still dual core x86, as a lot of people complain here - for some reason Intel strongly believes quad core is not need in -U segment. Instead, they beef up only the GPU, which may be bottle-necked anyway by DDR3 just as in AMD Kaveri case.
And all of these Broadwell-U i5 and i7 are offered for big $$$, as usual in Intel's case. Somewhat disappointing - I agree with some other posters in this thread.
DigitalFreak - Monday, January 5, 2015 - link
It is a node shrink, so you shouldn't expect anything major over Haswell. Now if Skylake doesn't bring the goods, then they'll have an issue.