QNAP TS-853 Pro 8-bay Intel Bay Trail SMB NAS Review
by Ganesh T S on December 29, 2014 7:30 AM ESTSingle Client Performance - CIFS & iSCSI on Windows
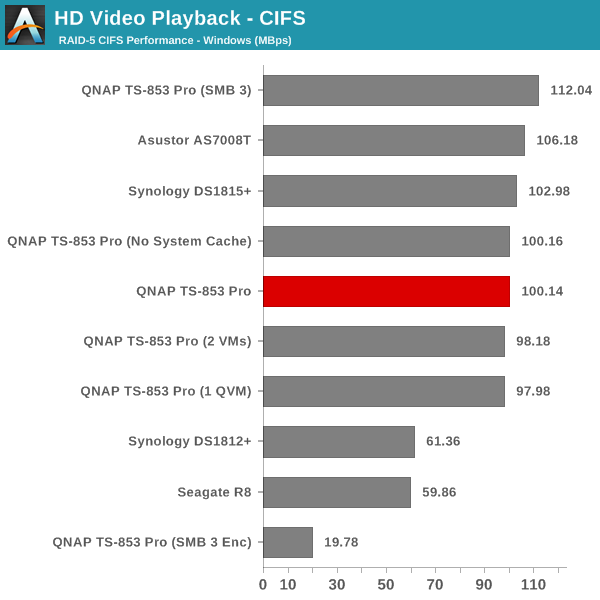
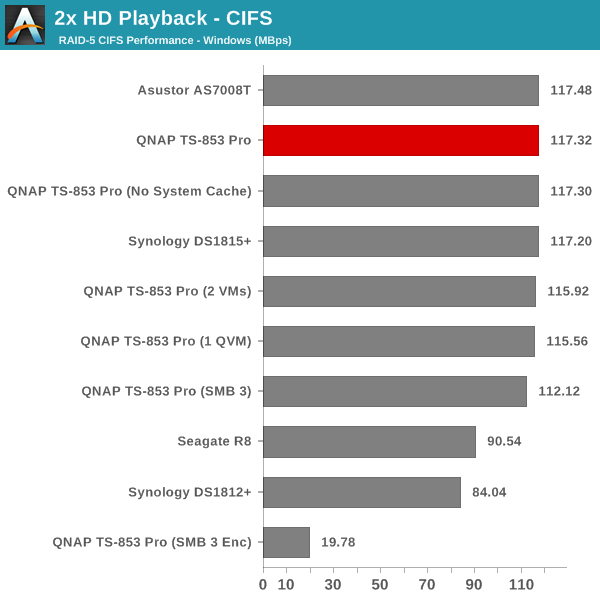
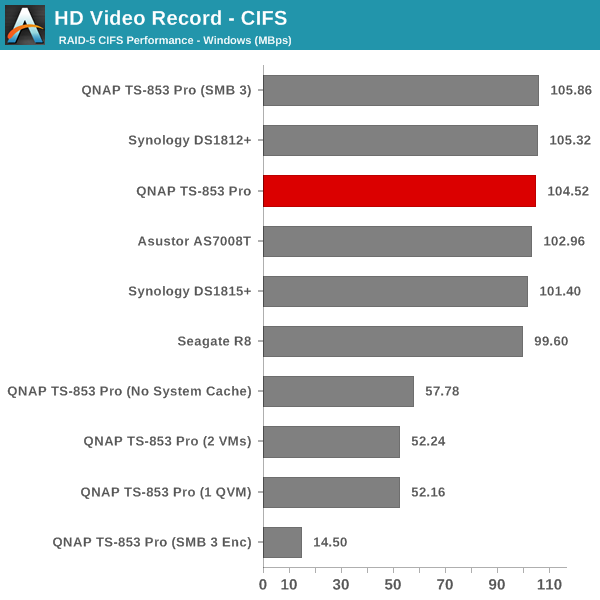
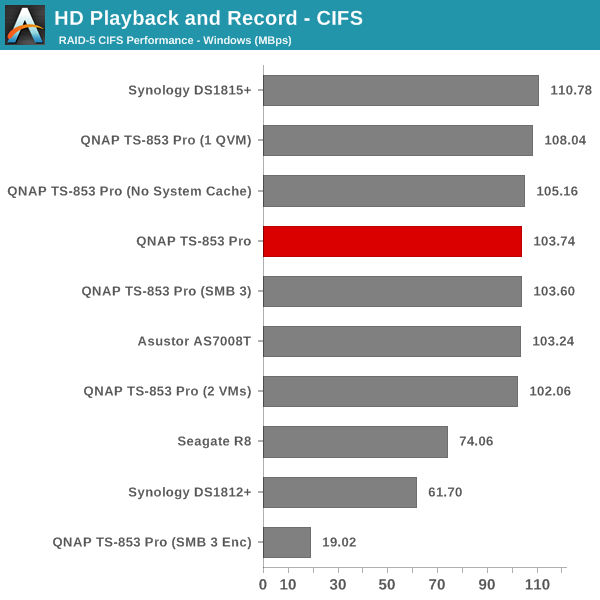
The single client CIFS and iSCSI performance of the QNAP TS-853 Pro was evaluated on the Windows platforms using Intel NASPT and our standard robocopy benchmark. This was run from one of the virtual machines in our NAS testbed. All data for the robocopy benchmark on the client side was put in a RAM disk (created using OSFMount) to ensure that the client's storage system shortcomings wouldn't affect the benchmark results. It must be noted that all the shares / iSCSI LUNs are created in a RAID-5 volume. SMB 3.0 performs very well, but, with the host OS being Windows 8, it wouldn't really be fair to compare it against other NAS units that were processed with a Windows 7 client. In any case, we find enabling SMB 3.0 encryption pulls down the processing rate to around 20 MBps irrespective of the type of traffic. Enabling VMs pulls down the performance. In general, Haswell performs better than Rangeley or Bay Trail, but Asustor's ADM is not yet optimized fully. This allows Synology and QNAP to pull ahead with their Rangeley / Bay Trail solutions.

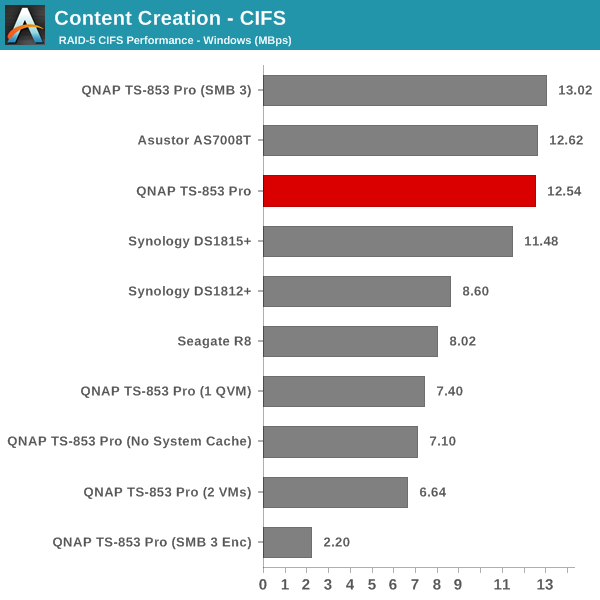
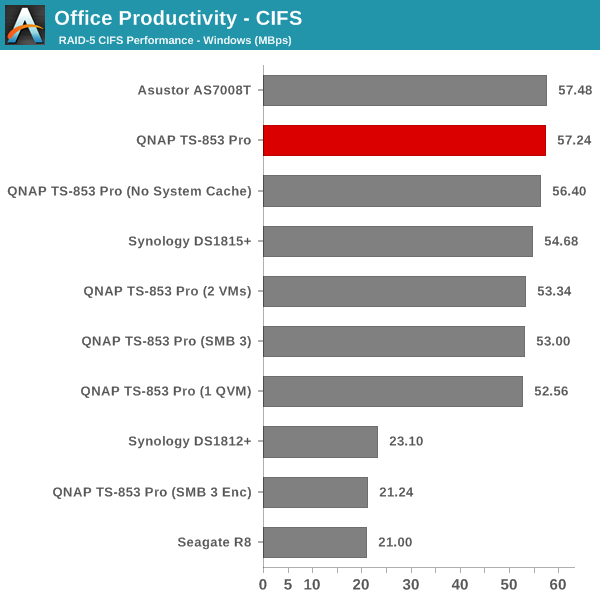
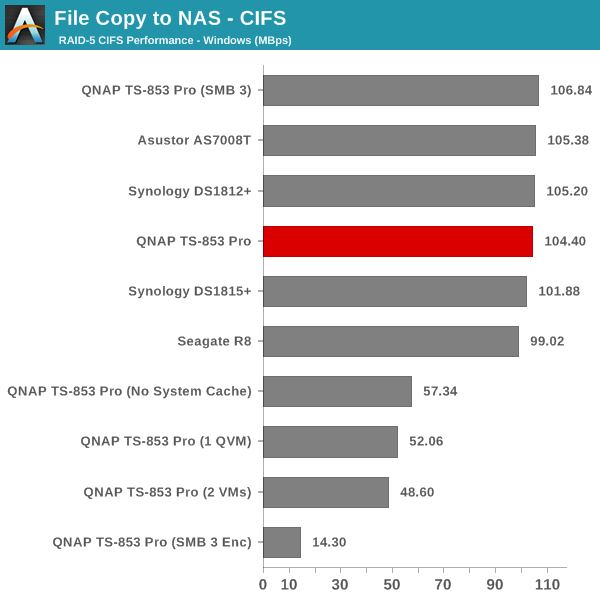

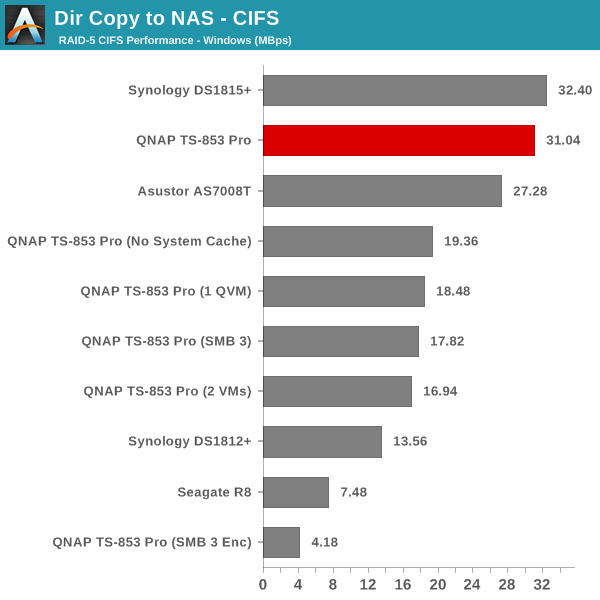
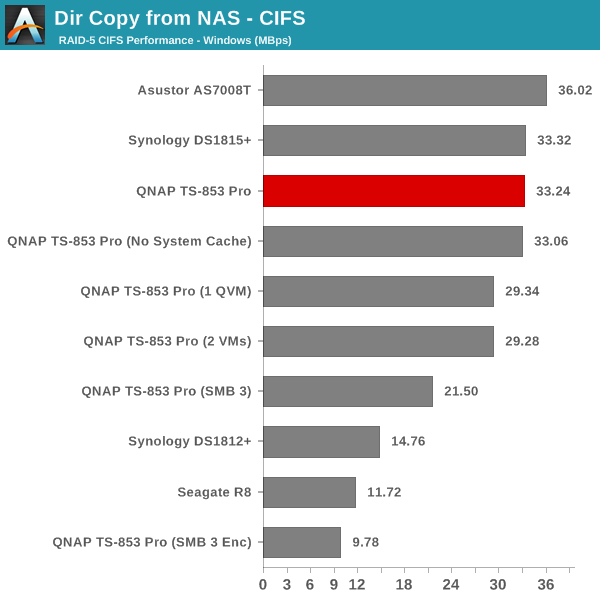
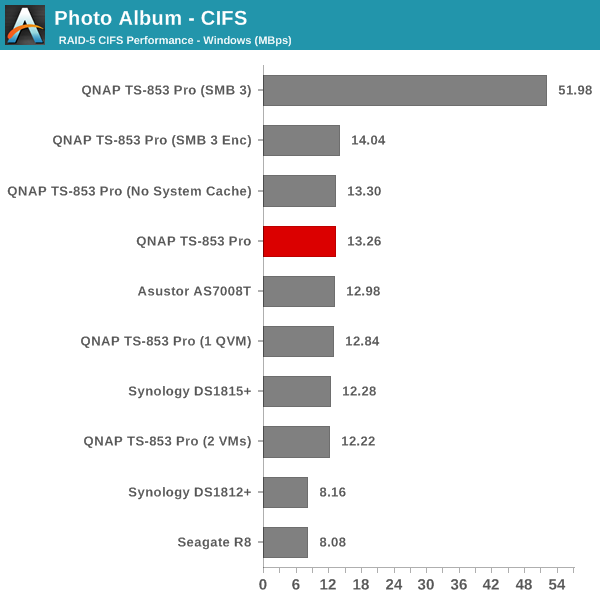
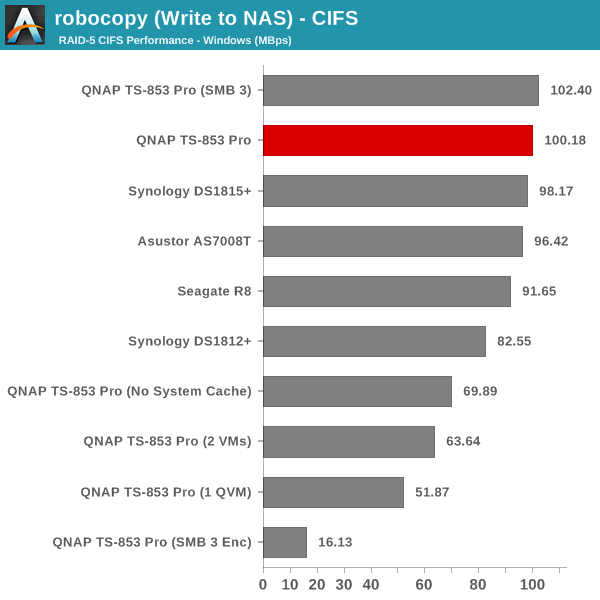
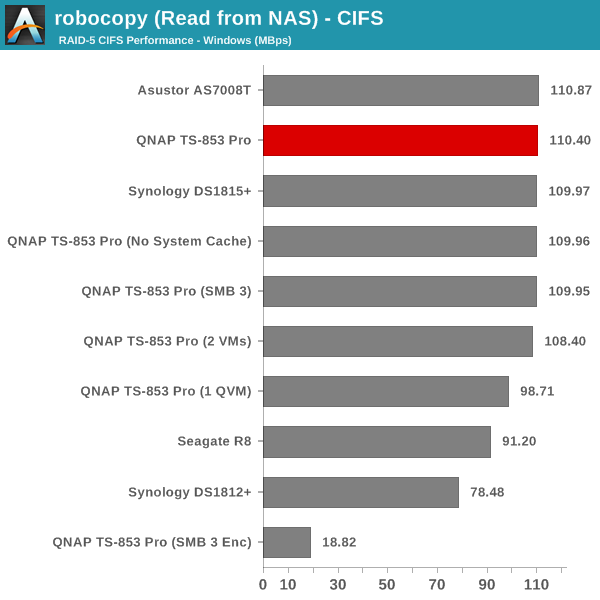
We created a 250 GB iSCSI LUN / target and mapped it on to a Windows VM in our testbed. The same NASPT benchmarks were run and the results are presented below. The observations we had in the CIFS subsection above hold true here too.
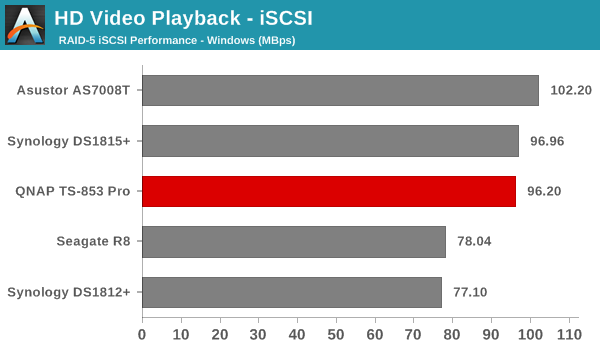
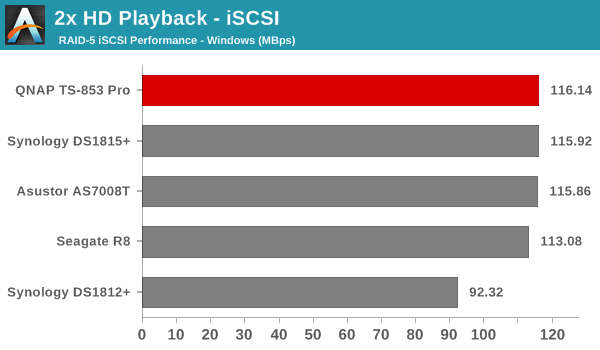
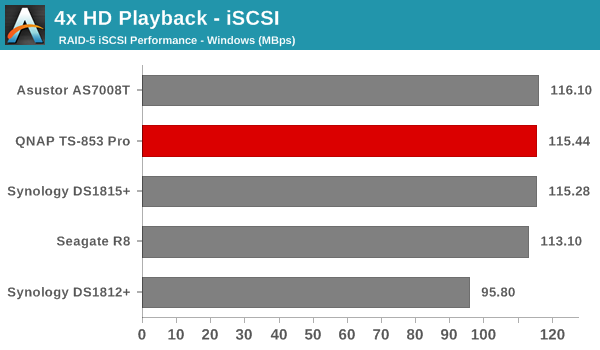
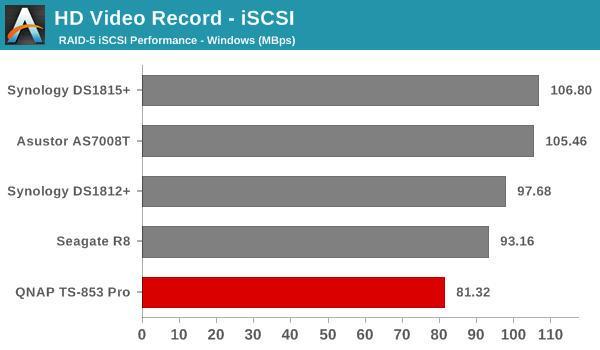
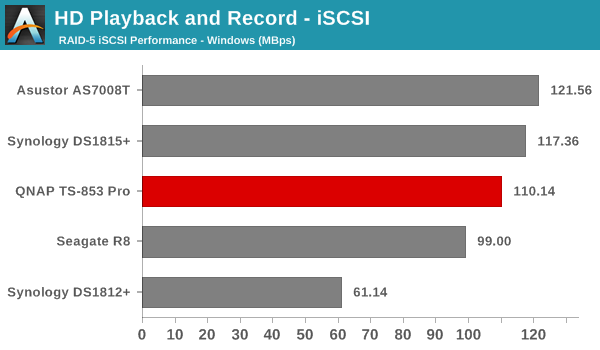
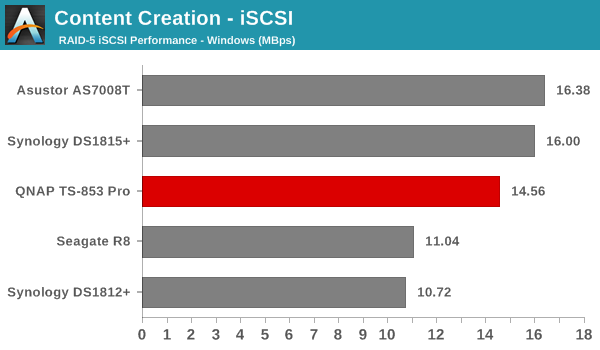
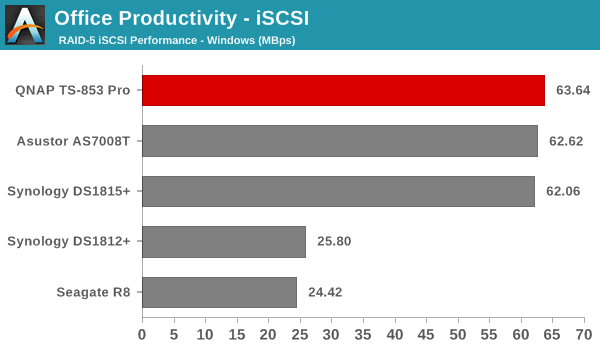
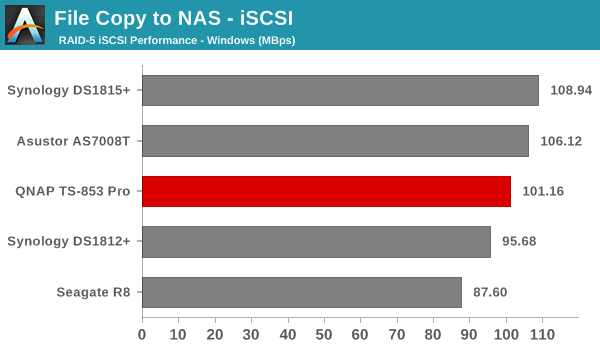
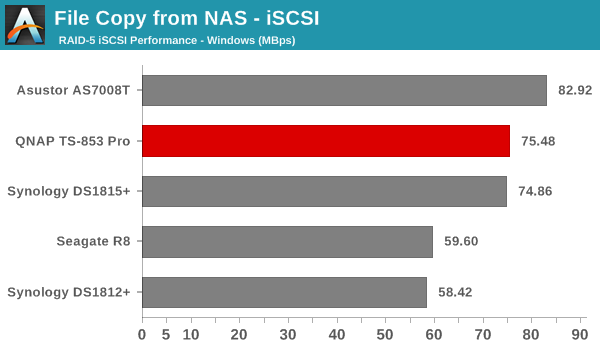
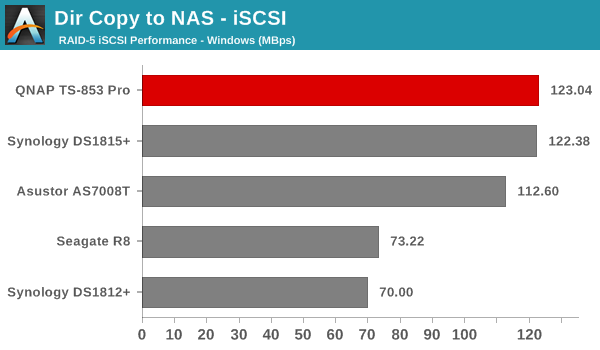
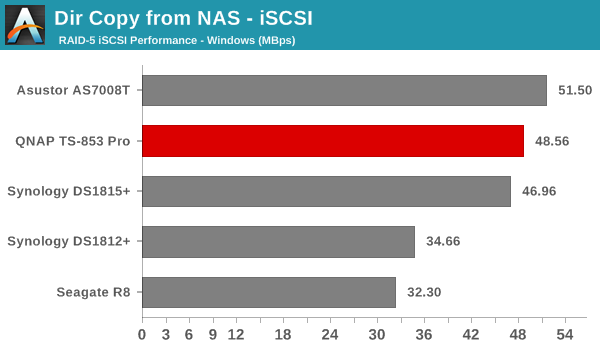
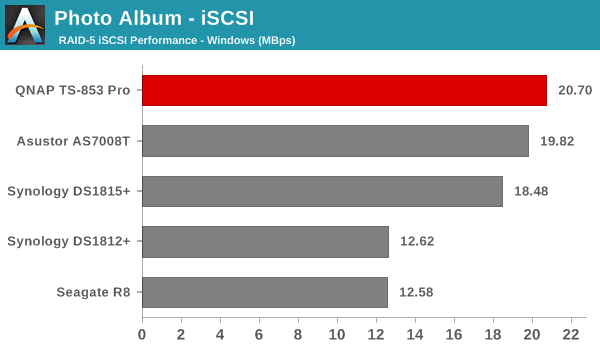
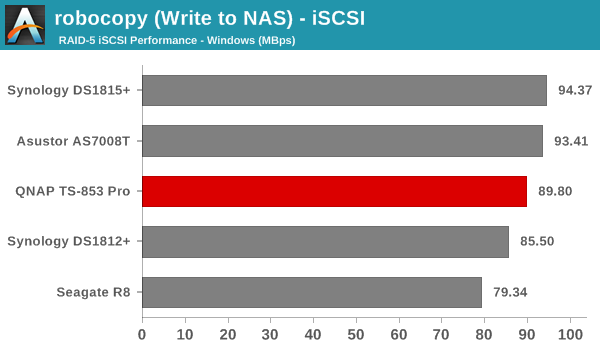
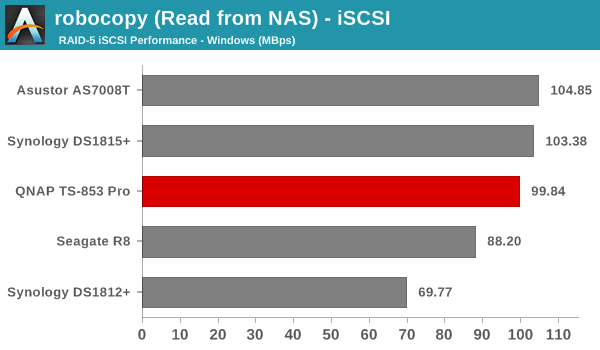
iSCSI testing results closely track the CIFS test results. Note that we only performed evaluation with Windows 7. The system cache was turned on for these tests (though the EXT4 delay allocation was disabled).








58 Comments
View All Comments
hrrmph - Monday, December 29, 2014 - link
How about a shrunken down unit with 8 x 2.5 inch bays and some 1TB SSDs?When will the bandwidth to get the data in and out quickly be available?
Jeff7181 - Monday, December 29, 2014 - link
It's available today if you can afford a few thousand dollars on 10 GbE or fibre channel.fackamato - Monday, December 29, 2014 - link
"8 x 2.5 inch bays and some 1TB SSDs"So say RAID5, 7TB of data, ~3.5GBps or ~28Gbps. Yeah you need to bond 3x 10Gb interfaces for that, at least.
SirGCal - Monday, December 29, 2014 - link
Why are all of these 8-drive setups configured as RAID-5? Personally, the entire point of so many disks are for more redundancy. At least RAID 6 (or even RAID Z3).Personally, I have a 24TB array and a 12 TB array, effectively. Each 8-drive servers (not these pre-built boxes, but actual servers). One with 4 and one with 2TB drives. Raid 6 and Z2. Both easily out perform the networks they are attached to. But they were designed to be as reasonably secure as possible, and they are plenty fast for even small business use. But I have to lose 3 drives to lose data.
When you do lose a drive, the time it takes, and the stress on the remaining drives, is when you are most likely to lose another drive. Assuming you don't do look-ahead drive replacement, etc. and just let it drive into the ground... Once one drive fails, the others are all tired and aging and the stress involved in rebuilding one drive can cause another one to go. Should that happen in RAID 5, you're done. With RAID 6, you at least have one more security step.
Knock on wood, I've only once ever had a RAID 6 rebuild fail once where-as I've had multiple RAID 5's fail, and that's over many dozens of servers and many many many years (decades). Hence why moving to RAID 6 was important. IMHO, RAID 5 is peachy for systems with <= 5 drives. But after that, especially with larger drives taking longer rebuild times, moving up to more redundancy is the sole point of having more drives in a unit. (assuming one single volume, etc. There are always other configurations with multiple RAID 5 or other volumes...)
Just my opining but that's what I see when I see all of the RAID 5 tests on these, could-be, very large arrays. And I'm not even going into the cost of these units, but I don't even see RAID 6 times as tested at all in the final page. If I was to ever be getting something like this, that would be the foremost important area, RAID 6 performances, that is...
Icehawk - Monday, December 29, 2014 - link
Agreed - I run a RAID 1 (just 2 HDs) at home at it's sole purpose is live backup/redundancy of my critical files, I don't really care about speed just data security. I don't work in IT anymore but when I did that was also the driving force behind our RAID setups, is this no longer the case?kpb321 - Monday, December 29, 2014 - link
I am not an expert but my understanding is it is more than just that. The size of drives has increased so much that with a large array like that a rebuild to replace a failed disk is reading so much data that the drives Unrecoverable Error Rate ends up being a factor and a fully functionaly drive may still end up throwing a read error. At that point the best case scenario is that the system retries the read and gets the right data or ignores it and continues on just corrupting that piece of data but the worst case is that the raid now marks that drive as failed and thinks you've just lost all your data due to a two drive failure.The first random article about this topic =)
http://subnetmask255x4.wordpress.com/2008/10/28/sa...
shodanshok - Wednesday, December 31, 2014 - link
Please read all the articles speaking about URE rate with a (big) grain of salt.Articles as the one linked above suggest that a multi TB disk will be doomed to regularly throw URE. I even read one articles stating that with consumer URE rate (10^-14) it will be almost impossible to read a 12+ TB arrays without error.
These statements are (generally) wrong, as we don't know _how_ the manufacturer arrive at the published URE numbers. For example, we don't know if they refer to a very large disk population, of a smaller set with aging (end-of-warranty) disks.
Here you can find an interesting discussion with other (very prepared) peoples on the linux-raid mailing list: http://marc.info/?l=linux-raid&m=1406709331293...
For the record: I read over 50 TB from an aging 500 GB Seagate 7200.12 disk without a single URE. At the same time, much younger disks (500 GB WD Green and Seagate 7200.11) gave me UREs much sooner than I expected.
Bottom line: while UREs are a _real_ problem (and the main reason to ditch single-parity RAID schemes, mainly on hardware raid cards where a single unreadable error occurring in an already degraded scenario can kill the entire array), many articles on the subject are absolutely wrong in their statements.
Regards.
PaulJeff - Monday, December 29, 2014 - link
Being in the storage arena for a long time, you have to look at performance and storage requirements. If you need high IOPS, with low overhead of RAID-based read and write commands, RAID5 has less of a penalty than RAID6. In terms of data protection, mathematically, RAID6 is more "secure" when it comes to unrecoverable read error (URE) during RAID rebuilds with high capacity (>2TB) drives with 4 or more drives in the array.I never rebuild RAID arrays whether they be hardware or software-based (ZFS) due to the issue of URE and critically long rebuild times. I make sure I have perfect backups because of this. Blow out the array, recreate the array or zpool and restore data. MUCH faster and less likely to have a problem. Risk management at work here.
To get over the IOPS issue with a large number of disks in an array, I use ZFS and max out the RAM onboard and large L2ARC when running VM's. For database and file storage, lots of RAM, decent sized L2ARC and ZIL are key.
SirGCal - Tuesday, December 30, 2014 - link
My smaller array mirrors the bigger one on the critical folders. Simple rsync every night. And I have built similar arrays in pairs that mirror each other all the time for just that reason. However I haven't had an issue with rebuild times... Even on my larger 24TB array, the rebuilt takes ~ 14 hours. However, even doing a full copy of the entire 12TB array parts only would take longer over a standard 1G network. The 'can not live without' bits are stored off-sight sure but still, pulling them back down over the internet and our wonderfully fast (sarcastic) USA internet would be painful also. I think it comes down to how big your arrays are to how long it actually takes to rebuild vs repopulate. My very large arrays can rebuild much faster then repopulate for example.ganeshts - Tuesday, December 30, 2014 - link
The reason we do RAID-5 is just to have a standard comparison metric across different NAS units that we evaluate. RAID-5 stresses the parity acceleration available, while also evaluating the storage controllers (direct SATA, SATA - PCIe bridges etc.)I do mention in the review that we expect users to have multiple volumes (possibly with different RAID levels) for units with 6 or more bays when using in real life.
We could do RAID-6 comparison if we had more time for evaluation at our disposal :) Already, testing our RAID-5 rebuild / migration / expansion takes 5 - 6 days as the table on the last page shows.