Chipworks Disassembles Apple's A8 SoC: GX6450, 4MB L3 Cache & More
by Ryan Smith on September 23, 2014 1:00 PM EST
One of the more enjoyable rituals with Apple’s annual iPhone launch is the decapping, deconstruction, and photographing of the processor die at the heart of Apple’s newest SoC. While we can learn a lot about the SoC from software, for some things there’s just no replacement for looking at the hardware itself and counting the functional blocks present. And this year, as in past years, the honor of being the first to tear apart the SoC goes to Chipworks.
For determining the layout of A8, Chipworks reached out to us to solicit our input on their die shot, and after some rounds of going back and forth we believe we’ve come to a solid determination of some of A8’s features and how it has been configured. So let's dive in.
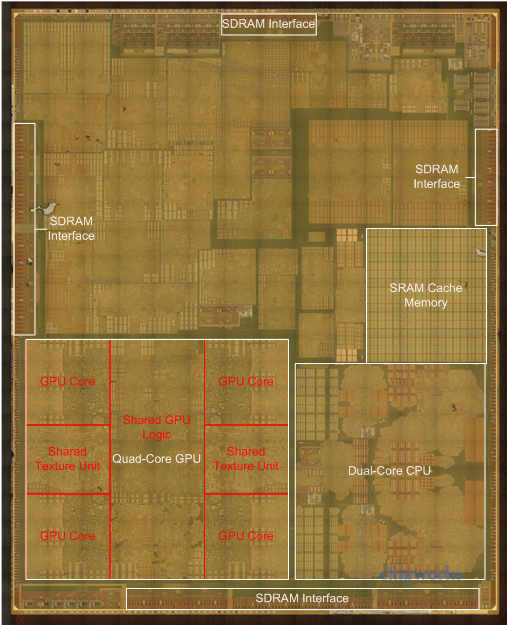
First and foremost we’ll start with A8’s GPU, as this was one of the hardest elements to analyze in software. Based on Apple’s 50% performance improvement we had previously speculated that A8 contained an Imagination PowerVR GX6650. However as we noted back then, a die shot would reveal all, and right on schedule it has.
A close analysis of the die shot makes it clear that there are only 4 GPU cores available and not 6, which immediately rules out the 6 core GX6650 we were previously expecting. Instead with 4 cores present this is conclusive proof that Apple is using the smaller 4 core GX6450 on A8, the direct successor to the G6430 used on the A7. GX6450 induces some performance optimizations along with some feature updates – including ASTC support, which Apple’s documentation has already confirmed is present – so its inclusion here is a natural progression for Apple.
On A8 and its 20nm process this measures at 19.1mm2, versus A7’s 22.1mm2 G6430. As a result Apple is saving some die space compared to A7, but this is being partially offset by the greater complexity of GX6450 and possibly additional SRAM for larger caches on the GPU. Meanwhile looking at the symmetry of the block, it’s interesting that the blocks of texturing resources that every pair of GPU cores share is so visible and so large. With these resources being so big relative to the GPU cores themselves, you can see why Imagination would want to share them as opposed to building them 1:1 with the GPU cores.
Meanwhile opposite the GPU we have the CPU block. Unlike the GPU the CPU block has seen some significant shrinking, which Chipworks estimates is down from 17.1mm2 in A7 to 12.2mm2 in A8. In A7 Cyclone did not lend itself to easily picking apart the individual CPU cores, and neither does the CPU here in A8. We’ll be looking at the new CPU’s architecture in-depth in our iPhone 6 review, but for now it’s safe to say that while this is definitely derived from Cyclone, Apple has added a few tweaks over the last year that make it an even more potent CPU than the first Cyclone. Meanwhile based on this die shot Chipworks believes that the L2 cache has been reorganized to a per-core design, as there is no obvious single block of L2 on A8 like there was A7.

A8 With PoP DRAM Removed
The final major identifiable block on A8 is once again the SRAM cache memory. On A7 we discovered that this block was 4MB and was responsible for servicing the GPU and CPU. On A8 this block is similarly present and serving the same role. This 4MB of SRAM ends up being quite big despite the shrink from 28nm to 20nm, and while at first glance it seems like it should be larger than 4MB given the relative size, in practice what has happened is that the individual SRAM cells have not shrunk by a full 50%. Chipworks estimates the cell size to now be about 0.08µm2, versus 0.12µm2 on A7, which is closer to a 33% shrink that a 50% shrink. As a result the SRAM cache still takes up a fair bit of space, but the value of being able to serve larger memory requests without having to go off-die continues to be immense.
| Apple A8 vs A7 SoCs | ||||
| Apple A8 (2014) | Apple A7 (2013) | |||
| Manufacturing Process | TSMC 20nm HKMG | Samsung 28nm HKMG | ||
| Die Size | 89mm2 | 104mm2 | ||
| Transistor Count | ~2B | "Over 1B" | ||
| CPU | 2 x Apple Enhanced Cyclone ARMv8 64-bit cores | 2 x Apple Cyclone ARMv8 64-bit cores | ||
| GPU | IMG PowerVR GX6450 | IMG PowerVR G6430 | ||
Overall, Chipworks’ analysis points to A8 being fabbed on TSMC’s 20nm process. This makes A8 among the first SoCs to receive the 20nm treatment. Thanks to this smaller node Apple has been able to build in additional features to the SoC while simultaneously shaving off around 15% of their die size. Chipworks estimates the final die size of A8 to stand at 89mm2, versus the 104mm2 for the Samsung 28nm based A7. Chipworks notes that if this were a straight shrink that one would expect the A8 to be closer to 50% the size of A7 (though not all logic can shrink quite that well), which indicates that Apple has spent quite a bit of die size on improving performance through more complex CPU and GPU architectures and miscellaneous feature additions.
Wrapping things up, we’ll be back later this month with our review of the iPhone 6 family and our full analysis of the A8 SoC. So until then stay tuned.

Source: Chipworks








65 Comments
View All Comments
mkozakewich - Tuesday, September 23, 2014 - link
Is that some app someone made? If so, I bet they scan it to see which iPhone it is and then put up a generic datasheet that they compiled themselves (probably with AnandTech's old guess data?)Jorgio - Tuesday, September 23, 2014 - link
What is the name of this app?PorkayM - Tuesday, September 23, 2014 - link
System statusAchtung_BG - Tuesday, September 23, 2014 - link
http://www.dailytech.com/Die+Shots+Confirm+A8+Pack...This article say GX6650 with graphics die shot ?!?
ltcommanderdata - Tuesday, September 23, 2014 - link
Anyone can take a die shot and draw some boxes and put labels on it. You just need to decide who is the more knowledgeable analyst.DanNeely - Tuesday, September 23, 2014 - link
All that does it go to prove Jason Mick missed the clue train again. Not the first time DT's desire to be able to scream "FRIST!!!" like a 4 year old on a comment thread resulted in them greatly exceeding their technical skills and looking like an idiot as a result.name99 - Tuesday, September 23, 2014 - link
Regarding the SRAM block,my guess is that it's still an L3 cache, and that it was moved closer to the CPU. Recall the graph onhttp://www.anandtech.com/show/7460/apple-ipad-air-...
which tells us we have an L3 cache of about 4MB and a latency of around 90 cycles or so.
That's obviously not great, and if moving the core physically closer to it (along with, presumably improving the interface to it which may well, in Cyclone, have been a rushed and half-assed job) can bring that down to maybe 50 cycles, that's a nice improvement.
IF the L3 is also being used as a staging area to move data to the GPU, then even if that transfer operation is slowed as a consequence, that's a sensible tradeoff, since GPUs are by design latency tolerant in a way that CPUs are not.
tipoo - Tuesday, September 23, 2014 - link
Kind of interesting, if the SRAM is making up for the main memory bandwidth deficit (it was reduced from a6-a7 I think?), why is it so far from the GPU cores?adityarjun - Wednesday, September 24, 2014 - link
If it not a 6 core GPU and how is Apple claiming a 50% increase in performance?Anandtech, do benchmarks actually show a 50% increase?
Krysto - Wednesday, September 24, 2014 - link
Wait, you still thought it was a GX6650 AFTER Apple announced that it's ONLY 50 percent faster?I'm disappointed in you Anandtech. That was obvious as daylight. GX6650 can be 2-4x faster, depending on configuration, than the old A7 GPU. OF COURSE it wasn't the GX6650, but something weaker.